一、概要
随着系统日益庞大、逻辑业务越来越复杂,系统架构由原来的单一系统到垂直系统,发展到现在的分布式系统。分布式系统中,可以做到公共业务模块的高可用,高容错性,高扩展性,然而,当系统越来越复杂时,需要考虑的东西自然也越来越多,要求也越来越高,比如服务路由、负载均衡等。此文将针对负载均衡算法进行讲解,不涉及具体的实现。
二、负载均衡算法
在分布式系统中,多台服务器同时提供一个服务,并统一到服务配置中心进行管理,如图1-1。消费者通过查询服务配置中心,获取到服务到地址列表,需要选取其中一台来发起RPC远程调用。如何选择,则取决于具体的负载均衡算法,对应于不同的场景,选择的负载均衡算法也不尽相同。负载均衡算法的种类有很多种,常见的负载均衡算法包括轮询法、随机法、源地址哈希法、加权轮询法、加权随机法、最小连接法等,应根据具体的使用场景选取对应的算法。
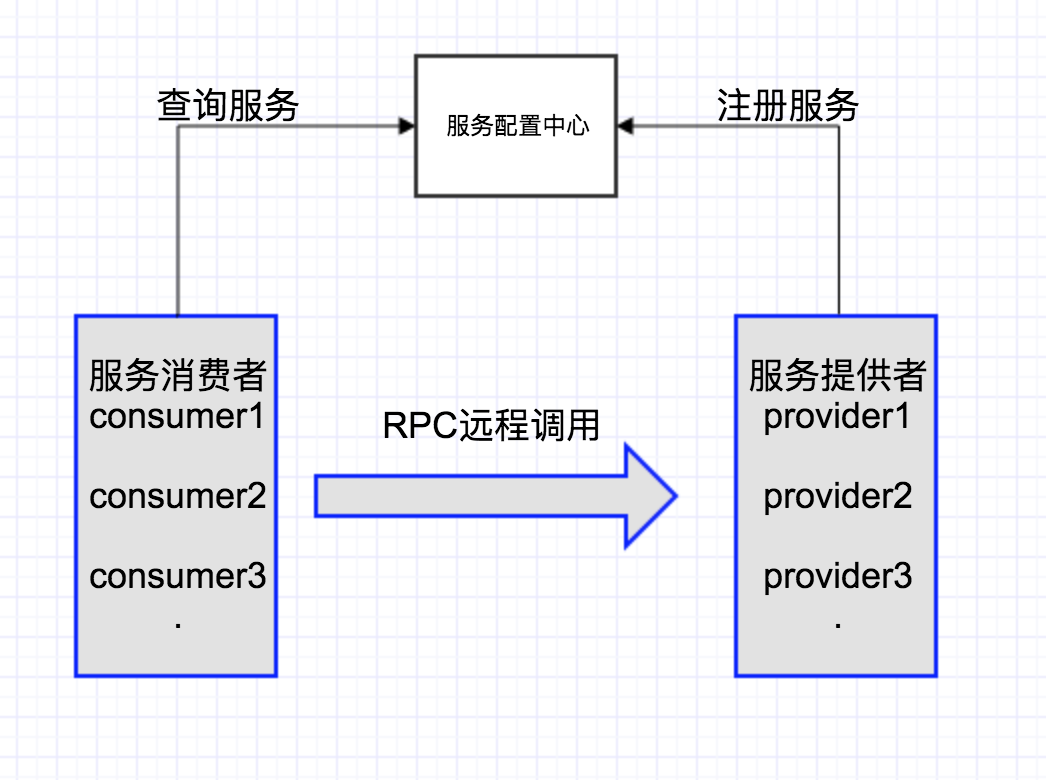
图1-1
1、轮询(Round Robin)法
轮询很容易实现,将请求按顺序轮流分配到后台服务器上,均衡的对待每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
这里通过实例化一个serviceWeightMap的Map变量来服务器地址和权重的映射,以此来模拟轮询算法的实现,其中设置的权重值在以后的加权算法中会使用到,这里先不做过多介绍,该变量初始化如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
private static Map<String, Integer> serviceWeightMap = new HashMap<String, Integer>();static { serviceWeightMap.put("192.168.1.100", 1); serviceWeightMap.put("192.168.1.101", 1);<br> //权重为4 serviceWeightMap.put("192.168.1.102", 4); serviceWeightMap.put("192.168.1.103", 1); serviceWeightMap.put("192.168.1.104", 1);<br> //权重为3 serviceWeightMap.put("192.168.1.105", 3); serviceWeightMap.put("192.168.1.106", 1);<br> //权重为2 serviceWeightMap.put("192.168.1.107", 2); serviceWeightMap.put("192.168.1.108", 1); serviceWeightMap.put("192.168.1.109", 1); serviceWeightMap.put("192.168.1.110", 1);} |
通过该地址列表,实现的轮询算法的部分关键代码如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
private static Integer pos = 0;public static String testRoundRobin() { // 重新创建一个map,避免出现由于服务器上线和下线导致的并发问题 Map<String, Integer> serverMap = new HashMap<String, Integer>(); serverMap.putAll(serviceWeightMap); //取得IP地址list Set<String> keySet = serverMap.keySet(); ArrayList<String> keyList = new ArrayList<String>(); keyList.addAll(keySet); String server = null; synchronized (pos) { if (pos > keySet.size()) { pos = 0; } server = keyList.get(pos); pos++; } return server;} |
由于serviceWeightMap中的地址列表是动态的,随时可能由机器上线、下线或者宕机,因此,为了避免可能出现的并发问题,比如数组越界,通过在方法内新建局部变量serverMap,先将域变量拷贝到线程本地,避免被其他线程修改。这样可能会引入新的问题,当被拷贝之后,serviceWeightMap的修改将无法被serverMap感知,也就是说,在这一轮的选择服务器中,新增服务器或者下线服务器,负载均衡算法中将无法获知。新增比较好处理,而当服务器下线或者宕机时,服务消费者将有可能访问不到不存在的地址。因此,在服务消费者服务端需要考虑该问题,并且进行相应的容错处理,比如重新发起一次调用。
对于当前轮询的位置变量pos,为了保证服务器选择的顺序性,需要对其在操作时加上synchronized锁,使得同一时刻只有一个线程能够修改pos的值,否则当pos变量被并发修改,将无法保证服务器选择的顺序性,甚至有可能导致keyList数组越界。
使用轮询策略的目的是,希望做到请求转移的绝对均衡,但付出的代价性能也是相当大的。为了保证pos变量的并发互斥,引入了重量级悲观锁synchronized,将会导致该轮询代码的并发吞吐量明显下降。
2、随机法
通过系统随机函数,根据后台服务器列表的大小值来随机选取其中一台进行访问。由概率概率统计理论可以得知,随着调用量的增大,其实际效果越来越接近于平均分配流量到后台的每一台服务器,也就是轮询法的效果。
随机算法的部分关键代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public static String testRandom() { // 重新创建一个map,避免出现由于服务器上线和下线导致的并发问题 Map<String, Integer> serverMap = new HashMap<String, Integer>(); serverMap.putAll(serviceWeightMap); //取得IP地址list Set<String> keySet = serverMap.keySet(); ArrayList<String> keyList = new ArrayList<String>(); keyList.addAll(keySet); Random random = new Random(); int randomPos = random.nextInt(keyList.size()); String server = keyList.get(randomPos); return server;} |
跟前面类似,为了避免并发的问题,需要将serviceWeightMap拷贝到serverMap中。通过Random的nextInt函数,取到0~keyList.size之间的随机值, 从而从服务器列表中随机取到一台服务器的地址,进行返回。根据概率统计理论,吞吐量越大,随机算法的效果越接近于轮询算法的效果。
3、源地址哈希法
源地址哈希法的思想是根据服务消费者请求客户端的IP地址,通过哈希函数计算得到一个哈希值,将此哈希值和服务器列表的大小进行取模运算,得到的结果便是要访问的服务器地址的序号。采用源地址哈希法进行负载均衡,相同的IP客户端,如果服务器列表不变,将映射到同一个后台服务器进行访问。
源地址哈希法部分关键代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public static String testConsumerHash(String remoteIp) { // 重新创建一个map,避免出现由于服务器上线和下线导致的并发问题 Map<String, Integer> serverMap = new HashMap<String, Integer>(); serverMap.putAll(serviceWeightMap); //取得IP地址list Set<String> keySet = serverMap.keySet(); ArrayList<String> keyList = new ArrayList<String>(); keyList.addAll(keySet); int hashCode = remoteIp.hashCode(); int pos = hashCode % keyList.size(); return keyList.get(pos);} |
4、加权轮询(Weight Round Robin)法
不同的后台服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不一样。跟配置高、负载低的机器分配更高的权重,使其能处理更多的请求,而配置低、负载高的机器,则给其分配较低的权重,降低其系统负载,加权轮询很好的处理了这一问题,并将请求按照顺序且根据权重分配给后端。
加权轮询法部分关键代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
public static String testWeightRoundRobin() { // 重新创建一个map,避免出现由于服务器上线和下线导致的并发问题 Map<String, Integer> serverMap = new HashMap<String, Integer>(); serverMap.putAll(serviceWeightMap); //取得IP地址list Set<String> keySet = serverMap.keySet(); Iterator<String> it = keySet.iterator(); List<String> serverList = new ArrayList<String>(); while (it.hasNext()) { String server = it.next(); Integer weight = serverMap.get(server); for (int i=0; i<weight; i++) { serverList.add(server); } } String server = null; synchronized (pos) { if (pos > serverList.size()) { pos = 0; } server = serverList.get(pos); pos++; } return server;} |
与轮询算法类似,只是在获取服务器地址之前增加了一段权重计算代码,根据权重的大小,将地址重复增加到服务器地址列表中,权重越大,该服务器每轮所获得的请求数量越多。
5、加权随机(Weight Random)法
加权随机法跟加权轮询法类似,根据后台服务器不同的配置和负载情况,配置不同的权重。不同的是,它是按照权重来随机选取服务器的,而非顺序。
部分关键代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public static String testWeightRandom() { // 重新创建一个map,避免出现由于服务器上线和下线导致的并发问题 Map<String, Integer> serverMap = new HashMap<String, Integer>(); serverMap.putAll(serviceWeightMap); //取得IP地址list Set<String> keySet = serverMap.keySet(); List<String> serverList = new ArrayList<String>(); Iterator<String> it = keySet.iterator(); while (it.hasNext()) { String server = it.next(); Integer weight = serverMap.get(server); for (int i=0; i<weight; i++) { serverList.add(server); } } Random random = new Random(); int randomPos = random.nextInt(serverList.size()); String server = serverList.get(randomPos); return server;} |
6、最小连接数法
前面我们费尽心思来实现服务消费者请求次数分配的均衡,我们知道这样做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是,实际上,请求次数的均衡并不代表负载的均衡。因此我们需要介绍最小连接数法,最小连接数法比较灵活和智能,由于后台服务器的配置不尽相同,对请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态的选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能的提高后台服务器利用率,将负载合理的分流到每一台服务器。