很长时间以来都没有怎么好好搞清楚RPC(即Remote Procedure Call,远程过程调用)和HTTP调用的区别,不都是写一个服务然后在客户端调用么?这里请允许我迷之一笑~Naive!本文简单地介绍一下两种形式的C/S架构,先说一下他们最本质的区别,就是RPC主要是基于TCP/IP协议的,而HTTP服务主要是基于HTTP协议的,我们都知道HTTP协议是在传输层协议TCP之上的,所以效率来看的话,RPC当然是要更胜一筹啦!下面来具体说一说RPC服务和HTTP服务。
为什么RPC呢?就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用。
RPC的协议有很多,比如最早的CORBA,Java RMI,Web Service的RPC风格,Hessian,Thrift,甚至Rest API。
关于RPC
RPC框架,首先了解什么叫RPC,为什么要RPC,RPC是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。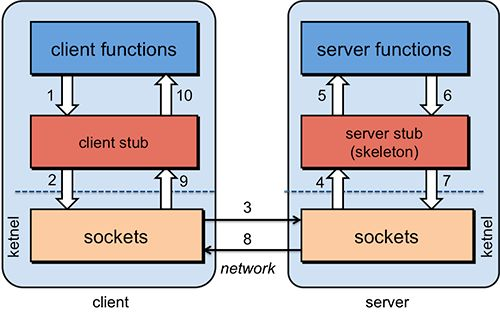
比如说,一个方法可能是这样定义的:
Employee getEmployeeByName(String fullName)
那么:
- 首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
- 第二,要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。比如基于Web服务协议栈的RPC,就要提供一个endpoint URI,或者是从UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
- 第三,当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给B服务器。
- 第四,B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
- 第五,返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用
OSI网络七层模型
在说RPC和HTTP的区别之前,我觉的有必要了解一下OSI的七层网络结构模型(虽然实际应用中基本上都是五层),它可以分为以下几层: (从上到下)
- 第一层:应用层。定义了用于在网络中进行通信和传输数据的接口;
- 第二层:表示层。定义不同的系统中数据的传输格式,编码和解码规范等;
- 第三层:会话层。管理用户的会话,控制用户间逻辑连接的建立和中断;
- 第四层:传输层。管理着网络中的端到端的数据传输;
- 第五层:网络层。定义网络设备间如何传输数据;
- 第六层:链路层。将上面的网络层的数据包封装成数据帧,便于物理层传输;
- 第七层:物理层。这一层主要就是传输这些二进制数据。
实际应用过程中,五层协议结构里面是没有表示层和会话层的。应该说它们和应用层合并了。我们应该将重点放在应用层和传输层这两个层面。因为HTTP是应用层协议,而TCP是传输层协议。好,知道了网络的分层模型以后我们可以更好地理解为什么RPC服务相比HTTP服务要Nice一些!
RPC服务
从三个角度来介绍RPC服务:分别是RPC架构,同步异步调用以及流行的RPC框架。
RPC架构
先说说RPC服务的基本架构吧。允许我可耻地盗一幅图哈~我们可以很清楚地看到,一个完整的RPC架构里面包含了四个核心的组件,分别是Client ,Server,Client Stub以及Server Stub,这个Stub大家可以理解为存根。分别说说这几个组件:
- 客户端(Client),服务的调用方。
- 服务端(Server),真正的服务提供者。
- 客户端存根,存放服务端的地址消息,再将客户端的请求参数打包成网络消息,然后通过网络远程发送给服务方。
- 服务端存根,接收客户端发送过来的消息,将消息解包,并调用本地的方法。

RPC主要是用在大型企业里面,因为大型企业里面系统繁多,业务线复杂,而且效率优势非常重要的一块,这个时候RPC的优势就比较明显了。实际的开发当中是这么做的,项目一般使用maven来管理。比如我们有一个处理订单的系统服务,先声明它的所有的接口(这里就是具体指Java中的interface),然后将整个项目打包为一个jar包,服务端这边引入这个二方库,然后实现相应的功能,客户端这边也只需要引入这个二方库即可调用了。为什么这么做?主要是为了减少客户端这边的jar包大小,因为每一次打包发布的时候,jar包太多总是会影响效率。另外也是将客户端和服务端解耦,提高代码的可移植性。
同步调用与异步调用
什么是同步调用?什么是异步调用?同步调用就是客户端等待调用执行完成并返回结果。异步调用就是客户端不等待调用执行完成返回结果,不过依然可以通过回调函数等接收到返回结果的通知。如果客户端并不关心结果,则可以变成一个单向的调用。这个过程有点类似于Java中的callable和runnable接口,我们进行异步执行的时候,如果需要知道执行的结果,就可以使用callable接口,并且可以通过Future类获取到异步执行的结果信息。如果不关心执行的结果,直接使用runnable接口就可以了,因为它不返回结果,当然啦,callable也是可以的,我们不去获取Future就可以了。
流行的RPC框架
目前流行的开源RPC框架还是比较多的。下面重点介绍三种:
- gRPC是Google最近公布的开源软件,基于最新的HTTP2.0协议,并支持常见的众多编程语言。 我们知道HTTP2.0是基于二进制的HTTP协议升级版本,目前各大浏览器都在快马加鞭的加以支持。 这个RPC框架是基于HTTP协议实现的,底层使用到了Netty框架的支持。
- Thrift是Facebook的一个开源项目,主要是一个跨语言的服务开发框架。它有一个代码生成器来对它所定义的IDL定义文件自动生成服务代码框架。用户只要在其之前进行二次开发就行,对于底层的RPC通讯等都是透明的。不过这个对于用户来说的话需要学习特定领域语言这个特性,还是有一定成本的。
- Dubbo是阿里集团开源的一个极为出名的RPC框架,在很多互联网公司和企业应用中广泛使用。协议和序列化框架都可以插拔是及其鲜明的特色。同样 的远程接口是基于Java Interface,并且依托于spring框架方便开发。可以方便的打包成单一文件,独立进程运行,和现在的微服务概念一致。
偷偷告诉你集团内部已经不怎么使用dubbo啦,现在用的比较多的叫HSF,又名“好舒服”。后面有可能会开源,大家拭目以待。
HTTP服务
其实在很久以前,我对于企业开发的模式一直定性为HTTP接口开发,也就是我们常说的RESTful风格的服务接口。的确,对于在接口不多、系统与系统交互较少的情况下,解决信息孤岛初期常使用的一种通信手段;优点就是简单、直接、开发方便。利用现成的http协议进行传输。我们记得之前本科实习在公司做后台开发的时候,主要就是进行接口的开发,还要写一大份接口文档,严格地标明输入输出是什么?说清楚每一个接口的请求方法,以及请求参数需要注意的事项等。比如下面这个例子:POST http://www.httpexample.com/restful/buyer/info/share
接口可能返回一个JSON字符串或者是XML文档。然后客户端再去处理这个返回的信息,从而可以比较快速地进行开发。但是对于大型企业来说,内部子系统较多、接口非常多的情况下,RPC框架的好处就显示出来了,首先就是长链接,不必每次通信都要像http一样去3次握手什么的,减少了网络开销;其次就是RPC框架一般都有注册中心,有丰富的监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。
引自:https://blog.csdn.net/kkkloveyou/article/details/51874354
本文介绍了什么是远程过程调用(RPC),RPC 有哪些常用的方法,RPC 经历了哪些发展阶段,以及比较了各种 RPC 技术的优劣。
什么是 RPC
RPC 是远程过程调用(Remote Procedure Call)的缩写形式,Birrell 和 Nelson 在 1984 发表于 ACM Transactions on Computer Systems 的论文《Implementing remote procedure calls》对 RPC 做了经典的诠释。RPC 是指计算机 A 上的进程,调用另外一台计算机 B 上的进程,其中 A 上的调用进程被挂起,而 B 上的被调用进程开始执行,当值返回给 A 时,A 进程继续执行。调用方可以通过使用参数将信息传送给被调用方,而后可以通过传回的结果得到信息。而这一过程,对于开发人员来说是透明的。
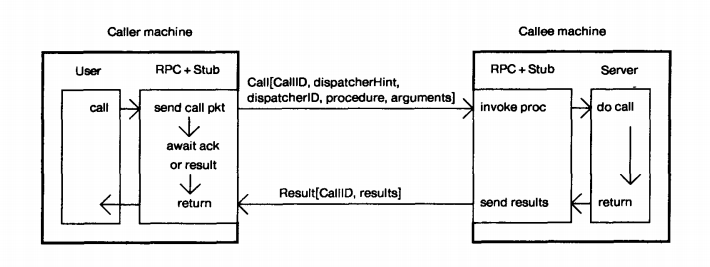
图1 描述了数据报在一个简单的RPC传递的过程
注:上述论文,可以在线阅读 http://www.cs.virginia.edu/~zaher/classes/CS656/birrel.pdf。
远程过程调用采用客户机/服务器(C/S)模式。请求程序就是一个客户机,而服务提供程序就是一台服务器。和常规或本地过程调用一样,远程过程调用是同步操作,在远程过程结果返回之前,需要暂时中止请求程序。使用相同地址空间的低权进程或低权线程允许同时运行多个远程过程调用。
RPC 的基本操作
让我们看看本地过程调用是如何实现的。考虑下面的 C 语言的调用:
count = read(fd, buf, nbytes);- 1
其中,fd 为一个整型数,表示一个文件。buf 为一个字符数组,用于存储读入的数据。 nbytes 为另一个整型数,用于记录实际读入的字节数。如果该调用位于主程序中,那么在调用之前堆栈的状态如图2(a)所示。为了进行调用,调用方首先把参数反序压入堆栈,即为最后一个参数先压入,如图2(b)所示。在 read 操作运行完毕后,它将返回值放在某个寄存器中,移出返回地址,并将控制权交回给调用方。调用方随后将参数从堆栈中移出,使堆栈还原到最初的状态。
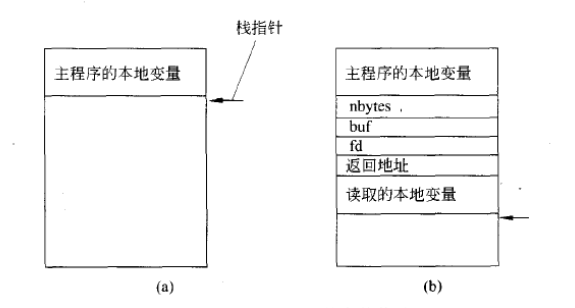
图2 过程调用中的参数传递
RPC 背后的思想是尽量使远程过程调用具有与本地调用相同的形式。假设程序需要从某个文件读取数据,程序员在代码中执行 read 调用来取得数据。在传统的系统中, read 例程由链接器从库中提取出来,然后链接器再将它插入目标程序中。 read 过程是一个短过程,一般通过执行一个等效的 read 系统调用来实现。即,read 过程是一个位于用户代码与本地操作系统之间的接口。
虽然 read 中执行了系统调用,但它本身依然是通过将参数压入堆栈的常规方式调用的。如图2(b)所示,程序员并不知道 read 干了啥。
RPC 是通过类似的途径来获得透明性。当 read 实际上是一个远程过程时(比如在文件服务器所在的机器上运行的过程),库中就放入 read 的另外一个版本,称为客户存根(client stub)。这种版本的 read 过程同样遵循图2(b)的调用次序,这点与原来的 read 过程相同。另一个相同点是其中也执行了本地操作系统调用。唯一不同点是它不要求操作系统提供数据,而是将参数打包成消息,而后请求此消息发送到服务器,如图3所示。在对 send 的调用后,客户存根调用 receive 过程,随即阻塞自己,直到收到响应消息。
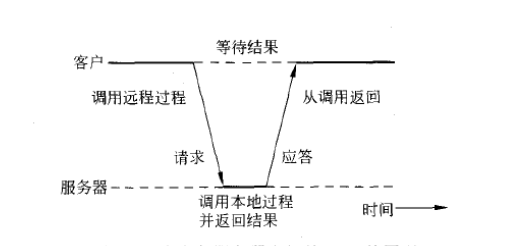
图3 客户与服务器之间的RPC原理
当消息到达服务器时,服务器上的操作系统将它传递给服务器存根(server stub)。服务器存根是客户存根在服务器端的等价物,也是一段代码,用来将通过网络输入的请求转换为本地过程调用。服务器存根一般先调用 receive ,然后被阻塞,等待消息输入。收到消息后,服务器将参数由消息中提取出来,然后以常规方式调用服务器上的相应过程(如图3所示)。从服务器角度看,过程好像是由客户直接调用的一样:参数和返回地址都位于堆栈中,一切都很正常。服务器执行所要求的操作,随后将得到的结果以常规的方式返回给调用方。以 read 为例,服务器将用数据填充 read 中第二个参数指向的缓冲区,该缓存区是属于服务器存根内部的。
调用完后,服务器存根要将控制权教会给客户发出调用的过程,它将结果(缓冲区)打包成消息,随后调用 send 将结果返回给客户。事后,服务器存根一般会再次调用 receive,等待下一个输入的请求。
客户机器接收到消息后,客户操作系统发现该消息属于某个客户进程(实际上该进程是客户存根,知识操作系统无法区分二者)。操作系统将消息复制到相应的缓存区中,随后解除对客户进程的阻塞。客户存根检查该消息,将结果提取出来并复制给调用者,而后以通常的方式返回。当调用者在 read 调用进行完毕后重新获得控制权时,它所知道的唯一事就是已经得到了所需的数据。它不指导操作是在本地操作系统进行,还是远程完成。
整个方法,客户方可以简单地忽略不关心的内容。客户所涉及的操作只是执行普通的(本地)过程调用来访问远程服务,它并不需要直接调用 send 和 receive 。消息传递的所有细节都隐藏在双方的库过程中,就像传统库隐藏了执行实际系统调用的细节一样。
概况来说,远程过程调用包含如下步骤:
- 客户过程以正常的方式调用客户存根;
- 客户存根生成一个消息,然后调用本地操作系统;
- 客户端操作系统将消息发送给远程操作系统;
- 远程操作系统将消息交给服务器存根;
- 服务器存根调将参数提取出来,而后调用服务器;
- 服务器执行要求的操作,操作完成后将结果返回给服务器存根;
- 服务器存根将结果打包成一个消息,而后调用本地操作系统;
- 服务器操作系统将含有结果的消息发送给客户端操作系统;
- 客户端操作系统将消息交给客户存根;
- 客户存根将结果从消息中提取出来,返回给调用它的客户存根。
以上步骤就是将客户过程对客户存根发出的本地调用转换成对服务器过程的本地调用,而客户端和服务器都不会意识到中间步骤的存在。
RPC 的主要好处是双重的。首先,程序员可以使用过程调用语义来调用远程函数并获取响应。其次,简化了编写分布式应用程序的难度,因为 RPC 隐藏了所有的网络代码存根函数。应用程序不必担心一些细节,比如 socket、端口号以及数据的转换和解析。在 OSI 参考模型,RPC 跨越了会话层和表示层。
实现远程过程调用
要实现远程过程调用,需考虑以下几个问题。
如何传递参数
传递值参数
传递值参数比较简单,下图图展示了一个简单 RPC 进行远程计算的例子。其中,远程过程 add(i,j) 有两个参数 i 和 j, 其结果是返回 i 和 j 的算术和。
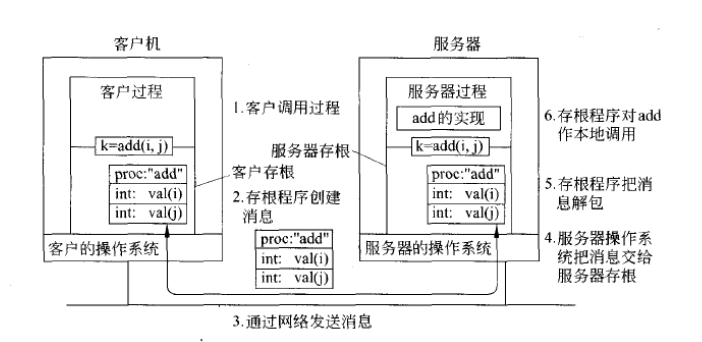
图4 通过RPC进行远程计算的步骤
通过 RPC 进行远程计算的步骤有:
- 将参数放入消息中,并在消息中添加要调用的过程的名称或者编码。
- 消息到达服务器后,服务器存根堆该消息进行分析,以判明需要调用哪个过程,随后执行相应的调用。
- 服务器运行完毕后,服务器存根将服务器得到的结果打包成消息送回客户存根,客户存根将结果从消息中提取出来,把结果值返回给客户端。
当然,这里只是做了简单的演示,在实际分布式系统中,还需要考虑其他情况,因为不同的机器对于数字、字符和其他类型的数据项的表示方式常有差异。比如整数型,就有 Big Endian 和 Little Endian 之分。
传递引用参数
传递引用参数相对来说比较困难。单纯传递参数的引用(也包含指针)是完全没有意义的,因为引用地址传递给远程计算机,其指向的内存位置可能跟远程系统上完全不同。如果你想支持传递引用参数,你必须发送参数的副本,将它们放置在远程系统内存中,向他们传递一个指向服务器函数的指针,然后将对象发送回客户端,复制它的引用。如果远程过程调用必须支持引用复杂的结构,比如树和链表,他们需要将结构复制到一个无指针的表示里面(比如,一个扁平的树),并传输到在远程端来重建数据结构。
如何表示数据
在本地系统上不存在数据不相容的问题,因为数据格式总是相同的。而在分布式系统中,不同远程机器上可能有不同的字节顺序,不同大小的整数,以及不同的浮点表示。对于 RPC,如果想与异构系统通信,我们就需要想出一个“标准”来对所有数据类型进行编码,并可以作为参数传递。例如,ONC RPC 使用 XDR (eXternal Data Representation) 格式 。这些数据表示格式可以使用隐式或显式类型。隐式类型,是指只传递值,而不传递变量的名称或类型。常见的例子是 ONC RPC 的 XDR 和 DCE RPC 的 NDR。显式类型,指需要传递每个字段的类型以及值。常见的例子是 ISO 标准 ASN.1 (Abstract Syntax Notation)、JSON (JavaScript Object Notation)、Google Protocol Buffers、以及各种基于 XML 的数据表示格式。
如何选用传输协议
有些实现只允许使用一个协议(例如 TCP )。大多数 RPC 实现支持几个,并允许用户选择。
出错时,会发生什么
相比于本地过程调用,远程过程调用出错的机会将会更多。由于本地过程调用没有过程调用失败的概念,项目使用远程过程调用必须准备测试远程过程调用的失败或捕获异常。
远程调用的语义是什么
调用一个普通的过程语义很简单:当我们调用时,过程被执行。远程过程完全一次性调用成功是非常难以实现。执行远程过程可以有如下结果:
- 如果服务器崩溃或进程在运行服务器代码之前就死了,那么远程过程会被执行0次;
- 如果一切工作正常,远程过程会被执行1次;
- 如果服务器返回服务器存根后在发送响应前就奔溃了,远程过程会被执行1次或者多次。客户端接收不到返回的响应,可以决定再试一次,因此出现多次执行函数。如果没有再试一次,函数执行一次;
- 如果客户机超时和重新传输,那么远程过程会被执行多次。也有可能是原始请求延迟了。两者都可能会执行或不执行。
RPC 系统通常会提供至少一次或最多一次的语义,或者在两者之间选择。如果需要了解应用程序的性质和远程过程的功能是否安全,可以通过多次调用同一个函数来验证。如果一个函数可以运行任何次数而不影响结果,这是幂等(idempotent)函数的,如每天的时间、数学函数、读取静态数据等。否则,它是一个非幂等(nonidempotent)函数,如添加或修改一个文件)。
远程调用的性能怎么样
毫无疑问,一个远程过程调用将会比常规的本地过程调用慢得多,因为产生了额外的步骤以及网络传输本身存在延迟。然而,这并不应该阻止我们使用远程过程调用。
远程调用安全吗?
使用 RPC,我们必须关注各种安全问题:
- 客户端发送消息到远程过程,那个过程是可信的吗?
- 客户端发送消息到远程计算机,那个远程机器是可信的吗?
- 服务器如何验证接收的消息是来自合法的客户端吗?服务器如何识别客户端?
- 消息在网络中传播如何防止时被其他进程嗅探?
- 可以由其他进程消息被拦截和修改时遍历网络从客户端到服务器或服务器端?
- 协议能防止重播攻击吗?
- 如何防止消息在网络传播中被意外损坏或截断?
远程过程调用的优点
远程过程调用有诸多的优点:
- 你不必担心传输地址问题。服务器可以绑定到任何可用的端口,然后用 RPC 名称服务来注册端口。客户端将通过该名称服务来找到对应的端口号所需要的程序。而这一切对于程序员来说是透明的。
- 系统可以独立于传输提供者。自动生成服务器存根使其可以在系统上的任何一个传输提供者上可用,包括 TCP 和 UDP,而这些,客户端可以动态选择的。当代码发送以后,接收消息是自动生成的,而不需要额外的编程代码。
- 应用程序在客户端只需要知道一个传输地址——名称服务,负责告诉应用程序去哪里连接服务器函数集。
- 使用函数调用模型来代替 socket 的发送/接收(读/写)接口。用户不需要处理参数的解析。
RPC API
任何 RPC 实现都需要提供一组支持库。这些包括:
- 名称服务操作:
注册和查找绑定信息(端口、机器)。允许一个应用程序使用动态端口(操作系统分配的); - 绑定操作:使用适当的协议建立客户机/服务器通信(建立通信端点);
- 终端操作:注册端点信息(协议、端口号、机器名)到名称服务并监听过程调用请求。这些函数通常被自动生成的主程序——服务器存根(骨架)所调用;
- 安全操作:系统应该提供机制保证客户端和服务器之间能够相互验证,两者之间提供一个安全的通信通道;
- 国际化操作(可能):这是很少的一部分 RPC 包可能包括了转换时间格式、货币格式和特定于语言的在字符串表的字符串的功能;
- 封送处理/数据转换操作:函数将数据序列化为一个普通的的字节数组,通过网络进行传递,并能够重建;
- 存根内存管理和垃圾收集:存根可能需要分配内存来存储参数,特别是模拟引用传递语义。RPC 包需要分配和清理任何这样的分配。他们也可能需要为创建网络缓冲区而分配内存。RPC 包支持对象,RPC 系统需要一种跟踪远程客户端是否仍有引用对象或一个对象是否可以删除。
- 程序标识操作:允许应用程序访问(或处理) RPC 接口集的标识符,这样的服务器提供的接口集可以被用来交流和使用。
- 对象和函数的标识操作:
允许将远程函数或远程对象的引用传递给其他进程。并不是所有的 RPC 系统都支持。
所以,判断一种通信方式是否是 RPC,就看它是否提供上述的 API。
第一代 RPC
ONC RPC(以前称为 Sun RPC)
Sun 公司是第一个提供商业化 RPC 库和 RPC 编译器。在1980年代中期 Sun 计算机提供 RPC,并在 Sun Network File System(NFS) 得到支持。该协议被主要以 Sun 和 AT&T 为首的 Open Network Computing (开放网络计算)作为一个标准来推动。这是一个非常轻量级 RPC 系统可用在大多数 POSIX 和类 POSIX 操作系统中使用,包括 Linux、SunOS、OS X 和各种发布版本的 BSD。这样的系统被称为 Sun RPC 或 ONC RPC。
ONC RPC 提供了一个编译器,需要一个远程过程接口的定义来生成客户机和服务器的存根函数。这个编译器叫做 rpcgen。在运行此编译器之前,程序员必须提供接口定义。包含函数声明的接口定义,通过版本号进行分组,并被一个独特的程序编码来标识。该程序编码能够让客户来确定所需的接口。版本号是非常有用的,即使客户没有更新到最新的代码仍然可以连接到一个新的服务器,只要该服务器还支持旧接口。
参数通过网络转化成一种隐式类型序列化格式被称为 XDR (eXternal Data Representation)。这将确保参数能够发送到异构系统可以被正常使用,及时这些系统可能使用了不同的字节顺序,不同大小的整数,或不同的浮点或字符串表示。最后,Sun RPC 提供了一个实现必要的支持 RPC 协议和 socket 例程的运行时库。
所有的程序员都需要写是一个客户端程序(client.c),服务器功能(server.c)和 RPC 接口定义(date.x)。当 RPC 接口定义(后缀为.x 的文件,例如 date.x)是用 rpcgen 编译的,会创建三个或四个文件。下面是 date.x 的例子:
- date.h:包含项目的定义、版本和声明的函数。客户端和服务器端功能应该包括这个文件。
- date_svc.c :C 语言代码来实现服务器存根。
- date_clnt.c :C 语言代码来实现客户端存根。
- date_xdr.c :包含 XDR 例程来将数据转化为 XDR 格式。如果这个文件生成,它应该编译并用来链接在客户端和服务器的函数。
创建客户端和服务器可执行文件的第一步是定义在文件 date.x 里的编译数据。之后,客户端和服务器端函数可能被编译,并链接各自 rpcgen 生成的存根函数。
在旧版本里,传输协议只能将字符串“tcp”或字符串“udp”来指定各自的 IP 服务 RPC,且仅限于 Linux 实现的 RPC。为了使接口更加灵活,UNIX 系统从版本 4 (SunOS 从版本 5)开始网络选择程序允许一个更普通的规范。他们搜索文件(/etc/netconfig),来查找第一个满足您需求的提供者。最后一个参数可以是:
- “netpath”:搜索 NETPATH 环境变量用于首选传输提供者的序列;
- “circuit_n”:找到第一个在 NETPATH 列表中的虚拟电路提供者;
- “datagram_n”:找到第一个 NETPATH 列表中的数据报提供者;
- “visible”:找到第一个在 /etc/netconfig 的可见传输提供者;
- “circuit_v”:找到第一个在 /etc/netconfig 的可见虚拟电路传输提供者;
- “datagram_v”:找到第一个在 /etc/netconfig 的可见数据报传输提供者;
每个远程过程调用最初仅限于接受一个输入参数。系统只是后来修改为支持多个参数。支持单一参数 RPC 在一些 rpcgen 的版本中仍然是默认的,比如苹果的 OS X。传递多个参数必须通过定义一个结构,包含所需的参数,初始化它,并传递这个结构。
远程过程调用返回一个指针指向结果而不是期望的结果。服务器函数必须修改来能接受一个 RPC 定义(.x 文件)中声明的值的指针作为输入,并返回一个结果值的指针。在服务器上,一个指针必须是指向静态数据的指针。否则,当过程返回或释放过程的框架所指出的区域将未定义。在客户端,返回指针可以让我们区分一个失败的 RPC(空指针)和一个空返回从服务器(间接空指针)。
RPC 过程的名称若在 RPC 定义文件中做了定义,则会转换为小写,并在后缀价下划线,后跟一个版本号。例如,BIN_DATE 转成为引用函数 bin_date_1 。您的服务器必须实现 bin_date_1。
当我们运行这个程序时,会发生什么?
服务器
当我们启动服务器,服务器存根代码(程序)在后台运行运行。它创建一个 socket 并可绑定任何本地端口到 socket。然后调用一个在 RPC 库的函数 svc_register,来注册程序编号和版本。这个是用来联系 port mapper(端口映射器)。port mapper 是一个独立的进程,通常是在系统启动时启动。它跟踪端口号、版本号以及程序编号。在 UNIX 系统版本4中,这个进程称为 rpcbind。在 Linux 、OS X 和 BSD 系统,它被称为 portmap。
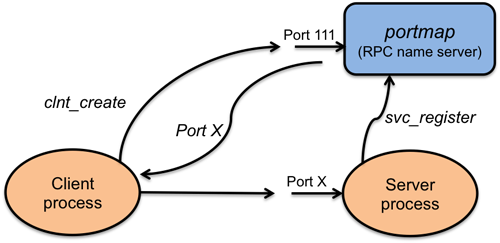
图5 ONC RPC 中的函数查找
客户端
当我们开始客户端程序时,它首先用远程系统的名称、程序编号、版本号和协议来调用 clnt_create 。它接触远程系统上的端口映射器,来为系统找到合适的端口。
然后客户端调用 RPC 存根函数(在本例中为 bin_date_1)。该函数发送一条消息(如,数据报)到服务器(使用早些时候发现的端口号)并等待响应。对于数据报服务来说,若没有接收到响应,它将重新发送一个固定的次数请求。
消息接着被远程系统接收到,它调用服务器函数(bin_date_1)并将返回值返回给客户端存根。客户端存根而后返回到客户端发出调用的代码。
分布式计算环境中的 RPC(DCE RPC)
DCE(Distributed Computing Environment,分布式计算环境)是一组由OFS(Open Software Foundation,开放软件基金会)设计的组件,用来提供支持分布式应用和分布式环境。与 X/Open 合并后,这组织成为了 The Open Group (开放式开发组)。DCE 提供的组件包括一个分布式文件服务、时间服务、目录服务以及其他服务。当然,我们感兴趣的是 DCE 的远程过程调用。它非常类似于 Sun RPC。接口是由 Interface Definition Notation (IDN) 定义的。类似于 Sun RPC,接口定义就像函数原型。
Sun RPC 不足之处在于,服务器的标识是一个“独特”的 32-bit 数字。虽然这是一个比在 socket 中 16-bit 可用空间更大的空间,但仍然无法满足数字唯一性的需求。DCE RPC 考虑到了这一缺陷,它无需程序员来处理编码。在编写应用程序时的第一步是从 uuidgen 程序获得一个惟一的 ID。这个程序会生成一个包含 ID 接口的原型 IDN 文件,并保证永远不会再次使用。它是一个 128-bit 的值,其中包含一个位置代码和创建时间的编码。然后用户编辑原型文件,填写远程过程声明。
在这一步后,IDN 的编译器 dceidl(类似于 rpcgen)会生成一个头、客户机存根和服务器存根。
Sun RPC 的另一个缺陷是,客户端必须知道服务器在哪台机器上。当它要访问时,必须要询问机器上的 RPC 名称服务程序编码所对应的端口号。DCE 支持将多个机器组织成为管理实体,称为 cells。cell 目录服务器使得每台机器知道如何与另外一台负责维护 cell 信息服务机器交互。
在 Sun RPC 中,服务器只能用本地名称服务(端口映射器)来注册其程序编号到端口映射。而在 DCE 中,服务器用 RPC 守护进程(名称服务器)来注册其端点(端口)到本地机器,并且用 cell 目录服务器注册其程序名字到机器的映射。当客户机想要与一个 RPC 服务器建立通信,它首先要求其 cell 目录服务器来定位服务器所在的机器。然后客户端从 RPC 守护进程处获得机器上服务器进程的端口号。DCE 的跨 cell 还支持更复杂的搜索。
DCE RPC 定义了 NDR (Network Data Representation) 用于对网络进行编码来封送信息。与用一个单一的规范来表示不同的数据类型相比,NDR 支持多规范(multi-canonical)格式。允许客户端来选择使用哪种格式,理想的情况是不需要将它从本地类型来转换。如果这不同于服务器的本地数据表示,服务器将仍然需要转换,但多规范格式可以避免当客户端和服务器都共享相同的本地格式的情况下转换为其他外部格式。例如,在一个规定了大端字节序网络数据格式的情况下,客户端和服务器只支持小端字节序,那么客户端必须将每个数据从小端字节序转为大端字节序,而当服务器接受到消息后,将每个数据转回小端字节序。多规范网络数据表示将允许客户端发送网络消息包含小端字节序格式的数据。
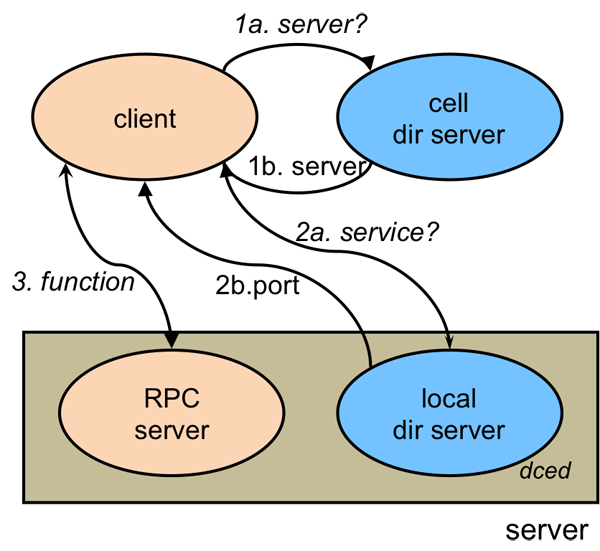
图6 DCE RPC 中的函数查找
第二代 RPC:支持对象
面向对象的语言开始在1980年代末兴起,很明显,当时的 Sun ONC 和 DCE RPC 系统都没有提供任何支持诸如从远程类实例化远程对象、跟踪对象的实例或提供支持多态性。现有的 RPC 机制虽然可以运作,但他们仍然不支持自动、透明的方式的面向对象编程技术。
微软 DCOM(COM+)
1992年4月,微软发布 Windows 3.1 包括一种机制称为 OLE (Object Linking and Embedding)。这允许一个程序动态链接其他库来支持的其他功能。如将一个电子表格嵌入到 Word 文档。OLE 演变成了 COM (Component Object Model)。一个 COM 对象是一个二进制文件。使用 COM 服务的程序来访问标准化接口的 COM 对象而不是其内部结构。COM 对象用全局唯一标识符(GUID)来命名,用类的 ID 来识别对象的类。几种方法来创建一个 COM 对象(例如 CoGetInstanceFromFile)。COM 库在系统注册表中查找相应的二进制代码(一个 DLL 或可执行文件),来创建对象,并给调用者返回一个接口指针。COM 的着眼点是在于同一台计算机上不同应用程序之间的通讯需求.
DCOM( Distributed Component Object Model)是 COM 的扩展,它支持不同的两台机器上的组件间的通信,而且不论它们是运行在局域网、广域网、还是 Internet 上。借助 DCOM 你的应用程序将能够进行任意空间分布。DCOM 于1996年在 Windows NT4.0 中引入的,后来更名为 COM+。由于 DCOM 是为了支持访问远程 COM 对象,需要创建一个对象的过程,此时需要提供服务器的网络名以及类 ID。微软提供了一些机制来实现这一点。最透明的方式是远程计算机的名称固定在注册表(或 DCOM 类存储)里,与特定类 ID 相关联。以此方式,应用程序不知道它正在访问一个远程对象,并且可以使用与访问本地 COM 对象相同的接口指针。另一方面,应用程序也可指定一个机器名作为参数。
由于 DCOM 是 COM 这个组件技术的无缝升级,所以你能够从你现有的有关 COM 得知识中获益,你的以前在 COM 中开发的应用程序、组件、工具都可以移入分布式的环境中。DCOM 将为你屏蔽底层网络协议的细节,你只需要集中精力于你的应用。
DCOM 最大的缺点是这是微软独家的解决办法,在跨防火墙方面的工作做得不是很好(大多数RPC系统也有类似的问题),因为防火墙必须允许某些端口来允许 ORPC 和 DCOM 通过。
CORBA
虽然 DCE 修复的一些 Sun RPC 的缺点,但某些缺陷依然存在。例如,如果服务器没有运行,客户端是无法连接到远程过程进行调用的。管理员必须要确保在任何客户端试图连接到服务器之前将服务器启动。如果一个新服务或接口添加到了系统,客户端是不能发现的。最后,面向对象语言期望在函数调用中体现多态性,即不同类型的数据的函数的行为应该有所不同,而这点恰恰是传统的 RPC 所不支持的。
CORBA (Common Object Request Broker Architecture) 就是为了解决上面提到的各种问题。是由 OMG 组织制订的一种标准的面向对象应用程 序体系规范。或者说 CORBA体系结构是对象管理组织(OMG)为解决分布式处理环境(DCE)中,硬件和软件系统的互连而提出的一种解决方案。OMG 成立于1989年,作为一个非营利性组织,集中致力于开发在技术上具有先进性、在商业上具有可行性并且独立于厂商的软件互联规范,推广面向对象模型技术,增强软件的可移植性(Portability)、可重用性(Reusability)和互操作性(Interoperability)。该组织成立之初,成员包括 Unisys、Sun、Cannon、Hewlett-Packard 和 Philips 等在业界享有声誉的软硬件厂商,目前该组织拥有800多家成员。
CORBA 体系的主要内容包括以下几部分:
- 对象请求代理 (Object Request Broker,ORB):负责对象在分布环境中透明地收发请求和响应,它是构建分布对象应用、在异构或同构环境下实现应用间互操作的基础。
- 对象服务(Object Services):为使用和实现对象而提供的基本对象集合,这些服务应独立于应用领域。主要的 CORBA 服务有:名录服务(Naming Service)、事件服务(Event Service)、生命周期服务(Life Cycle Service)、关系服务(Relationship Service)以及事务服务(Transaction Service)等。这些服务几乎包括分布系统和面向对象系统的各个方面,每个组成部分都非常复杂。
- 公共设施(Common Facilitites):向终端用户提供一组共享服务接口,例如系统管理、组合文档和电子邮件等。
- 应用接口(Application Interfaces)。由销售商提供的可控制其接口的产品,相应于传统的应用层表示,处于参考模型的最高层。
- 领域接口(Domain Interfaces):为应用领域服务而提供的接口,如OMG 组织为 PDM 系统制定的规范。
当客户端发出请求时,ORB 做了如下事情:
- 在客户端编组参数;
- 定位服务器对象。如果有必要的话,它会在服务器创建一个过程来处理请求;
- 如果服务器是远程是,就使用 RPC 或 socket 来传送请求;
- 在服务器上将参数解析成为服务器格式;
- 在服务器上组装返回值;
- 如果服务器是远程的,就将返回值传回;
- 在客户端对返回结果进行解析;
IDL(Interface Definition Language) 是用于指定类的名字、属性和方法。它不包含对象的实现。IDL 编译器生成代码来处理编组、解封以及ORB与网络之间的交互。它会生成客户机和服务器存根。IDL 是编程语言中立,支持包括C、C++、Java、Perl、Python、Ada、COBOL、Smalltalk、Objective C 和 LISP 等语言。一个示例IDL如下所示:
Module StudentObject {
Struct StudentInfo {
String name;
int id;
float gpa;
};
exception Unknown {};
interface Student {
StudentInfo getinfo(in string name)
raises(unknown);
void putinfo(in StudentInfo data);
};
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
IDL数据类型包括:
- 基本类型:long, short, string, float, …
- 构造类型:struct、union、枚举、序列
- 对象引用
- any 类型:一个动态类型的值
编程中最常见的实现方式是通过对象引用来实现请求。下面是一个使用 IDL 的例子:
Student st = ... // get object reference
try {
StudentInfo sinfo = st.getinfo("Fred Grampp");
} catch (Throwable e) {
... // error
}- 1
- 2
- 3
- 4
- 5
- 6
在 CORBA 规范中,没有明确说明不同厂商的中间件产品要实现所有的服务功能,并且允许厂商开发自己的服务类型。因此, 不同厂商的 ORB 产品对 CORBA 服务的支持能力不同,使我们在针对待开发系统的功能进行中间件产品选择时,有更多的选择余地。
CORBA 的不足有:
- 尽管有多家供应商提供CORBA产品,但是仍找不到能够单独为异种网络中的所有环境提供实现的供应商。不同的 CORBA 实现之间会出现缺乏互操作性的现象,从而造成一些问题;而且,由于供应商常常会自行定义扩展,而 CORBA 又缺乏针对多线程环境的规范,对于像 C 或 C++ 这样的语言,源码兼容性并未完全实现。
- CORBA 过于复杂,要熟悉 CORBA,并进行相应的设计和编程,需要许多个月来掌握,而要达到专家水平,则需要好几年。
更多有关 CORBA 的优缺点,可以参阅 Michi Henning 的《The rise and fall of CORBA》。
Java RMI
CORBA 旨在提供一组全面的服务来管理在异构环境中(不同语言、操作系统、网络)的对象。Java 在其最初只支持通过 socket 来实现分布式通信。1995年,作为 Java 的缔造者,Sun 公司开始创建一个 Java 的扩展,称为 Java RMI(Remote Method Invocation,远程方法调用)。Java RMI 允许程序员创建分布式应用程序时,可以从其他 Java 虚拟机(JVM)调用远程对象的方法。
一旦应用程序(客户端)引用了远程对象,就可以进行远程调用了。这是通过 RMI 提供的命名服务(RMI 注册中心)来查找远程对象,来接收作为返回值的引用。Java RMI 在概念上类似于 RPC,但能在不同地址空间支持对象调用的语义。
与大多数其他诸如 CORBA 的 RPC 系统不同,RMI 只支持基于 Java 来构建,但也正是这个原因, RMI 对于语言来说更加整洁,无需做额外的数据序列化工作。Java RMI 的设计目标应该是:
- 能够适应语言、集成到语言、易于使用;
- 支持无缝的远程调用对象;
- 支持服务器到 applet 的回调;
- 保障 Java 对象的安全环境;
- 支持分布式垃圾回收;
- 支持多种传输。
分布式对象模型与本地 Java 对象模型相似点在于:
- 引用一个对象可以作为参数传递或作为返回的结果;
- 远程对象可以投到任何使用 Java 语法实现的远程接口的集合上;
- 内置 Java instanceof 操作符可以用来测试远程对象是否支持远程接口。
不同点在于:
- 远程对象的类是与远程接口进行交互,而不是与这些接口的实现类交互;
- Non-remote 参数对于远程方法调用来说是通过复制,而不是通过引用;
- 远程对象是通过引用来传递,而不是复制实际的远程实现;
- 客户端必须处理额外的异常。
接口和类
所有的远程接口都继承自 java.rmi.Remote 接口。例如:
public interface bankaccount extends Remote
{
public void deposit(float amount)
throws java.rmi.RemoteException;
public void withdraw(float amount)
throws OverdrawnException,
java.rmi.RemoteException;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意,每个方法必须在 throws 里面声明 java.rmi.RemoteException 。 只要客户端调用远程方法出现失败,这个异常就会抛出。
远程对象类
Java.rmi.server.RemoteObject 类提供了远程对象实现的语义包括hashCode、equals 和 toString。 java.rmi.server.RemoteServer 及其子类提供让对象实现远程可见。java.rmi.server.UnicastRemoteObject 类定义了客户机与服务器对象实例建立一对一的连接.
存根
Java RMI 通过创建存根函数来工作。存根由 rmic 编译器生成。自 Java 1.5 以来,Java 支持在运行时动态生成存根类。编译器 rmic 会提供各种编译选项。
定位对象
引导名称服务提供了用于存储对远程对象的命名引用。一个远程对象引用可以存储使用类 java.rmi.Naming 提供的基于 URL 的方法。例如,
BankAccount acct = new BankAcctImpl();
String url = "rmi://java.sun.com/account";
// bind url to remote object
java.rmi.Naming.bind(url, acct);
// look up account
acct = (BankAccount)java.rmi.Naming.lookup(url);- 1
- 2
- 3
- 4
- 5
- 6
- 7

图7 Java RMI 工作流程
RMI 架构
RMI 是一个三层架构(图8)。最上面是 Stub/Skeleton layer(存根/骨架层)。方法调用从 Stub、Remote Reference Layer (远程引用层)和 Transport Layer(传输层)向下,传递给主机,然后再次经传 Transport Layer 层,向上穿过 Remote Reference Layer 和 Skeleton ,到达服务器对象。 Stub 扮演着远程服务器对象的代理的角色,使该对象可被客户激活。Remote Reference Layer 处理语义、管理单一或多重对象的通信,决定调用是应发往一个服务器还是多个。Transport Layer 管理实际的连接,并且追踪可以接受方法调用的远程对象。服务器端的 Skeleton 完成对服务器对象实际的方法调用,并获取返回值。返回值向下经 Remote Reference Layer 、服务器端的 Transport Layer 传递回客户端,再向上经 Transport Layer 和 Remote Reference Layer 返回。最后,Stub 程序获得返回值。
要完成以上步骤需要有以下几个步骤:
- 生成一个远程接口;
- 实现远程对象(服务器端程序);
- 生成 Stub 和 Skeleton(服务器端程序);
- 编写服务器程序 ;
- 编写客户程序 ;
- 注册远程对象;
- 启动远程对象
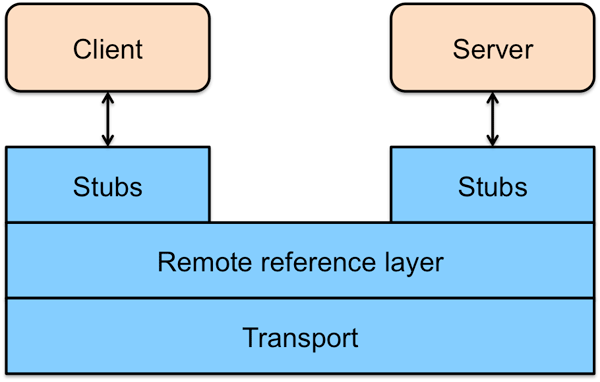
图8 Java RMI 架构
RMI 分布式垃圾回收
根据 Java 虚拟机的垃圾回收机制原理,在分布式环境下,服务器进程需要知道哪些对象不再由客户端引用,从而可以被删除(垃圾回收)。在 JVM中,Java 使用引用计数。当引用计数归零时,对象将会垃圾回收。在RMI,Java 支持两种操作:dirty 和 clean。本地 JVM 定期发送一个 dirty 到服务器来说明该对象仍在使用。定期重发 dirty 的周期是由服务器租赁时间来决定的。当客户端没有需要更多的本地引用远程对象时,它发送一个 clean 调用给服务器。不像 DCOM,服务器不需要计算每个客户机使用的对象,只是简单的做下通知。如果它租赁时间到期之前没有接收到任何 dirty 或者 clean 的消息,则可以安排将对象删除。
第三代 RPC 以及 Web Services
由于互联网的兴起,Web 浏览器成为占主导地位的用于访问信息的模型。现在的应用设计的首要任务大多数是提供用户通过浏览器来访问,而不是编程访问或操作数据。
网页设计关注的是内容。解析展现方面往往是繁琐的。传统 RPC 解决方案可以工作在互联网上,但问题是,他们通常严重依赖于动态端口分配,往往要进行额外的防火墙配置。
Web Services 成为一组协议,允许服务被发布、发现,并用于技术无关的形式。即服务不应该依赖于客户的语言、操作系统或机器架构。
Web Services 的实现一般是使用 Web 服务器作为服务请求的管道。客户端访问该服务,首先是通过一个 HTTP 协议发送请求到服务器上的 Web 服务器。Web 服务器配置识别 URL 的一部分路径名或文件名后缀并将请求传递给特定的浏览器插件模块。这个模块可以除去头、解析数据(如果需要),并根据需要调用其他函数或模块。对于这个实现流,一个常见的例子是浏览器对于 Java Servlet 的支持。HTTP 请求会被转发到 JVM 运行的服务端代码来执行处理。
XML-RPC
XML-RPC 是1998年作为一个 RPC 消息传递协议,将请求和响应封装解析为人类可读的 XML格式。XML 格式基于 HTTP 协议,缓解了传统企业的防火墙需要为 RPC 服务器应用程序打开额外的端口的问题。
下面是一个 XML-RPC 消息的例子:
<methodCall>
<methodName>
sample.sumAndDifference
</methodName>
<params>
<param><value><int> 5 </int></value></param>
<param><value><int> 3 </int></value></param>
</params>
</methodCall>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个例子中,方法 sumAndDifference 有两个整数参数 5 和 3。
XML-RPC 支持的基本数据类型是:int、string、boolean、double 和 dateTime.iso8601。此外,还有 base64 类型用于编码任意二进制数据。array 和 struct 允许定义数组和结构。
XML-RPC 不限制语任何特定的语言,也不是一套完整的软件来处理远程过程,诸如存根生成、对象管理和服务查找都不在协议内。现在有很多库针可以针对不同的语言,比如 Apache XML-RPC 可以用于 Java、Python 和 Perl。
XML-RPC 是一个简单的规范(约7页),没有雄心勃勃的目标——它只关注消息,而并不处理诸如垃圾收集、远程对象、远程过程的名称服务和其他方面的问题。然而,即使没有广泛的产业支持,简单的协议却能广泛采用。
SOAP
SOAP(Simple Object Access Protocol,简单对象访问协议),是以 XML-RPC 规范作为创建 SOAP 的依据,成立于1998年,获得微软和 IBM 的大力支持。该协议在创建初期只作为一种对象访问协议,但由于 SOAP 的发展,其协议已经不单只是用于简单的访问对象,所以这种 SOAP 缩写已经在标准的1.2版后被废止了。1.2版在2003年6月24日成为 W3C 的推荐版本。SOAP 指定 XML 作为无状态的消息交换格式,包括了 RPC 式的过程调用。
有关 SOAP 的标准可以参阅 https://www.w3.org/TR/soap/。
SOAP 只是一种消息格式,并未定义垃圾回收、对象引用、存根生成和传输协议。
下面是一个简单的例子:
<?xml version='1.0' ?>
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope">
<env:Header>
<m:reservation xmlns:m="http://travelcompany.example.org/reservation"
env:role="http://www.w3.org/2003/05/soap-envelope/role/next"
env:mustUnderstand="true">
<m:reference>uuid:093a2da1-q345-739r-ba5d-pqff98fe8j7d</m:reference>
<m:dateAndTime>2001-11-29T13:20:00.000-05:00</m:dateAndTime>
</m:reservation>
<n:passenger xmlns:n="http://mycompany.example.com/employees"
env:role="http://www.w3.org/2003/05/soap-envelope/role/next"
env:mustUnderstand="true">
<n:name>Åke Jógvan Øyvind</n:name>
</n:passenger>
</env:Header>
<env:Body>
<p:itinerary
xmlns:p="http://travelcompany.example.org/reservation/travel">
<p:departure>
<p:departing>New York</p:departing>
<p:arriving>Los Angeles</p:arriving>
<p:departureDate>2001-12-14</p:departureDate>
<p:departureTime>late afternoon</p:departureTime>
<p:seatPreference>aisle</p:seatPreference>
</p:departure>
<p:return>
<p:departing>Los Angeles</p:departing>
<p:arriving>New York</p:arriving>
<p:departureDate>2001-12-20</p:departureDate>
<p:departureTime>mid-morning</p:departureTime>
<p:seatPreference/>
</p:return>
</