random forest 和 extra-trees是对decison tree做ensemble而得到最终模型的两种算法.
阅读本文前需要先了解一下
random_forest
决策树在节点划分上,在随机的特征子集中寻找最优划分特征.进一步增强了随机性,抑制了过拟合.
class
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)¶
随机树的随机性体现在
- 每一颗决策树只学习部分的训练数据
- 决策树在做节点划分时,从某一特征子集中选取出最优划分特征.而不是从全部特征中选取.
extra-trees
class
sklearn.ensemble.ExtraTreesClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=False, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)¶
从名字就可以看出来,extra-trees,极限随机树们 =。=. 其实也是一个森林,只是这个森林里的树比random forest里的树还要更随机.
相比与random forest extra-trees进一步增大了随机性。这种随机性地增加体现在
- 在节点划分上,不光特征是从特征子集随机取的,阈值也是随机取的.
This usually allows to reduce the variance of the model a bit more, at the expense of a slightly greater increase in bias. 这种随机性的引入,通常会导致模型的方差减小,代价就是偏差可能会略微升高.
这里解释一下机器学习中的偏差(bias)和方差(variance).
一图胜千言
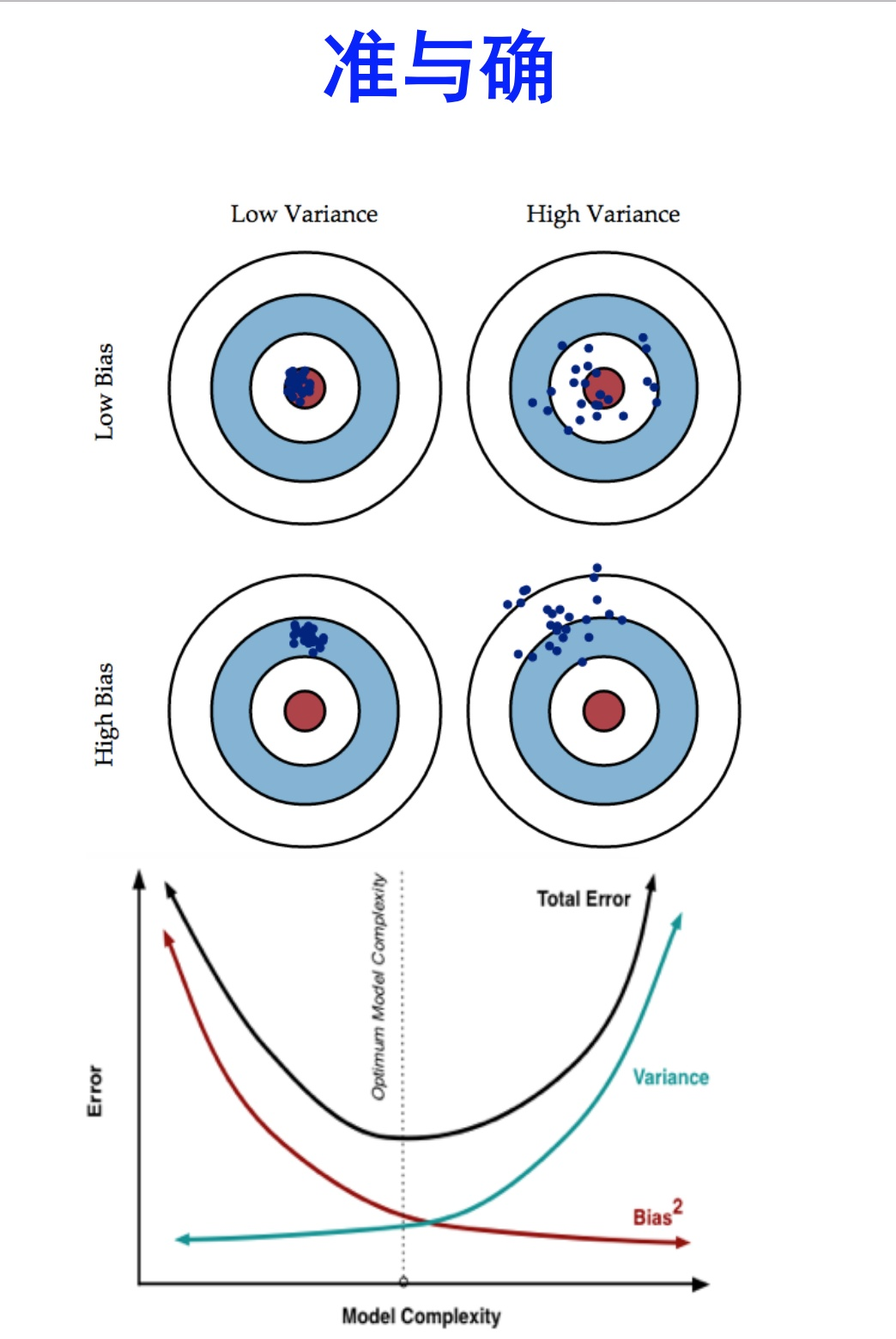
上图的点可以理解为一个个的模型,
high bias意味着欠拟合,模型过于简单了. low bias意味着准确率比较高. 这个相对好理解. 点离红心越近,说明在训练集上预测越准确.偏差越小.
high variance意味着过拟合,模型过于复杂,过分地去拟合训练数据了,点很分散,一旦训练数据发生一些变化,学习的结果将产生巨大变化.
可以这样理解:
- bias表示学习到的模型与完美真实模型的差异
- variance表示对不同的数据,模型所能学习到的信息之间的差异.
比如,一个模型,开始时一无所知,这个时候bias肯定很大,预测的准确度很差,而viriance很小,因为此时,对于任何数据来说,这个模型都一无所知,其预测结果也都是一样的. 随着学习的深入,模型复杂度的提高,bias肯定是减小了,预测的准确度上升,但是variance确增大了,因为模型学到了越来越多的有关训练数据的信息,容易过度拟合当前的训练数据,当换一组数据时,可能对模型的预测结果有很大的影响。
更多细致的讨论见https://www.zhihu.com/question/27068705.
以下引自某个回答
首先明确一点,Bias和Variance是针对Generalization(一般化,泛化)来说的。
在机器学习中,我们用训练数据集去训练(学习)一个model(模型),通常的做法是定义一个Loss function(误差函数),通过将这个Loss(或者叫error)的最小化过程,来提高模型的性能(performance)。然而我们学习一个模型的目的是为了解决实际的问题(或者说是训练数据集这个领域(field)中的一般化问题),单纯地将训练数据集的loss最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的loss与一般化的数据集的loss之间的差异就叫做generalization error。
而generalization error又可以细分为Bias和Variance两个部分。
首先如果我们能够获得所有可能的数据集合,并在这个数据集合上将loss最小化,这样学习到的模型就可以称之为“真实模型”,当然,我们是无论如何都不能获得并训练所有可能的数据的,所以“真实模型”肯定存在,但无法获得,我们的最终目标就是去学习一个模型使其更加接近这个真实模型。而bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。
Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。这里需要注意的是我们能够用来学习的训练数据集只是全部数据中的一个子集。想象一下我们现在收集几组不同的数据,因为每一组数据的不同,我们学习到模型的最小loss值也会有所不同,当然,它们与“真实模型”的最小loss也是不一样的。
其他答主有提到关于cross validation中k值对bias和variance的影响,那我就从其他方面来举个例子。
假设我们现在有一组训练数据,需要训练一个模型(基于梯度的学习,不包括最近邻等方法)。在训练过程的最初,bias很大,因为我们的模型还没有来得及开始学习,也就是与“真实模型”差距很大。然而此时variance却很小,因为训练数据集(training data)还没有来得及对模型产生影响,所以此时将模型应用于“不同的”训练数据集也不会有太大差异。
而随着训练过程的进行,bias变小了,因为我们的模型变得“聪明”了,懂得了更多关于“真实模型”的信息,输出值与真实值之间更加接近了。但是如果我们训练得时间太久了,variance就会变得很大,因为我们除了学习到关于真实模型的信息,还学到了许多具体的,只针对我们使用的训练集(真实数据的子集)的信息。而不同的可能训练数据集(真实数据的子集)之间的某些特征和噪声是不一致的,这就导致了我们的模型在很多其他的数据集上就无法获得很好的效果,也就是所谓的overfitting(过学习)。
因此,在实际的训练过程中会用到validation set,会用到诸如early stopping以及regularization等方法来避免过学习的发生,然而没有一种固定的策略方法适用于所有的task和data,所以bias和variance之间的tradeoff应该是机器学习永恒的主题吧。
最后说一点,从bias和variance的讨论中也可以看到data对于模型训练的重要性,假如我们拥有全部可能的数据,就不需要所谓的tradeoff了。但是既然这是不现实的,那么尽量获取和使用合适的数据就很重要了。
使用sklearn中的random forest和extra-trees
from sklearn.ensemble import RandomForestClassifier rf_clf = RandomForestClassifier(n_estimators=500, oob_score=True, random_state=666, n_jobs=-1) rf_clf.fit(X, y) from sklearn.ensemble import ExtraTreesClassifier et_clf = ExtraTreesClassifier(n_estimators=500, bootstrap=True, oob_score=True, random_state=666, n_jobs=-1) et_clf.fit(X, y)