数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元
素组成。数组的长度是数组类型的组成部分。因为数组的长度是数组类型的一个部
分,不同长度或不同类型的数据组成的数组都是不同的类型,因此在Go语言中很少
直接使用数组(不同长度的数组因为类型不同无法直接赋值)。
定义方式:
var a [3]int // 定义一个长度为3的int类型数组, 元素全部为0
var b = [...]int{1, 2, 3} // 定义一个长度为3的int类型数组, 元素为 1, 2, 3
var c = [...]int{2: 3, 1: 2} // 定义一个长度为3的int类型数组, 元素为 0, 2, 3
var d = [...]int{1, 2, 4: 5, 6} // 定义一个长度为6的int类型数组, 元素为 1, 2, 0, 0, 5, 6
Go语言中数组是值语义。一个数组变量即表示整个数组,它并不是隐式的指向第一
个元素的指针(比如C语言的数组),而是一个完整的值。当一个数组变量被赋值
或者被传递的时候,实际上会复制整个数组。如果数组较大的话,数组的赋值也会
有较大的开销。为了避免复制数组带来的开销,可以传递一个指向数组的指针,但
是数组指针并不是数组。
var a = [...]int{1, 2, 3} // a 是一个数组
var b = &a // b 是指向数组的指针
fmt.Println(a[0], a[1]) // 打印数组的前2个元素
fmt.Println(b[0], b[1]) // 通过数组指针访问数组元素的方式和数组类似
for i, v := range b { // 通过数组指针迭代数组的元素
fmt.Println(i, v)
}
对于数组类型来说, len 和 cap 函数返回的结果始终是一
样的,都是对应数组类型的长度。
遍历数组:
for i := range a {
fmt.Printf("a[%d]: %d
", i, a[i])
}
for i, v := range b {
fmt.Printf("b[%d]: %d
", i, v)
}
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d
", i, c[i])
}
用 for range 方式迭代的性能可能会更好一些,因为这种迭代可以保证不会出现
数组越界的情形,每轮迭代对数组元素的访问时可以省去对下标越界的判断。
用 for range 方式迭代,还可以忽略迭代时的下标:
var times [5][0]int
for range times {
fmt.Println("hello")
}
其中 times 对应一个 [5][0]int 类型的数组,虽然第一维数组有长度,但是数
组的元素 [0]int 大小是0,因此整个数组占用的内存大小依然是0。没有付出额外
的内存代价,我们就通过 for range 方式实现了 times 次快速迭代。
数组不仅仅可以用于数值类型,还可以定义字符串数组、结构体数组、函数数组、
接口数组、管道数组等等:
// 字符串数组
var s1 = [2]string{"hello", "world"}
var s2 = [...]string{"你好", "世界"}
var s3 = [...]string{1: "世界", 0: "你好", }
// 结构体数组
var line1 [2]image.Point
var line2 = [...]image.Point{image.Point{X: 0, Y: 0}, image.Poin
t{X: 1, Y: 1}}
var line3 = [...]image.Point{{0, 0}, {1, 1}}
// 图像解码器数组
var decoder1 [2]func(io.Reader) (image.Image, error)
var decoder2 = [...]func(io.Reader) (image.Image, error){
png.Decode,
jpeg.Decode,
}
// 接口数组
var unknown1 [2]interface{}
var unknown2 = [...]interface{}{123, "你好"}
// 管道数组
var chanList = [2]chan int{}
空的数组:
var d [0]int // 定义一个长度为0的数组
var e = [0]int{} // 定义一个长度为0的数组
var f = [...]int{} // 定义一个长度为0的数组
长度为0的数组在内存中并不占用空间。空数组虽然很少直接使用,但是可以用于
强调某种特有类型的操作时避免分配额外的内存空间,比如用于管道的同步操作:
c1 := make(chan [0]int)
go func() {
fmt.Println("c1")
c1 <- [0]int{}
}()
<-c1
在这里,我们并不关心管道中传输数据的真实类型,其中管道接收和发送操作只是
用于消息的同步。对于这种场景,我们用空数组来作为管道类型可以减少管道元素
赋值时的开销。当然一般更倾向于用无类型的匿名结构体代替:
c2 := make(chan struct{})
go func() {
fmt.Println("c2")
c2 <- struct{}{} // struct{}部分是类型, {}表示对应的结构体值
}()
<-c2
字符串
一个字符串是一个不可改变的字节序列,字符串通常是用来包含人类可读的文本数
据。和数组不同的是,字符串的元素不可修改,是一个只读的字节数组。每个字符
串的长度虽然也是固定的,但是字符串的长度并不是字符串类型的一部分。
Go语言字符串的底层结构在 reflect.StringHeader 中定义:
type StringHeader struct {
Data uintptr
Len int
}
字符串结构由两个信息组成:第一个是字符串指向的底层字节数组,第二个是字符
串的字节的长度。字符串其实是一个结构体,因此字符串的赋值操作也就
是 reflect.StringHeader 结构体的复制过程,并不会涉及底层字节数组的复
制。
我们可以看看字符串“Hello, world”本身对应的内存结构:
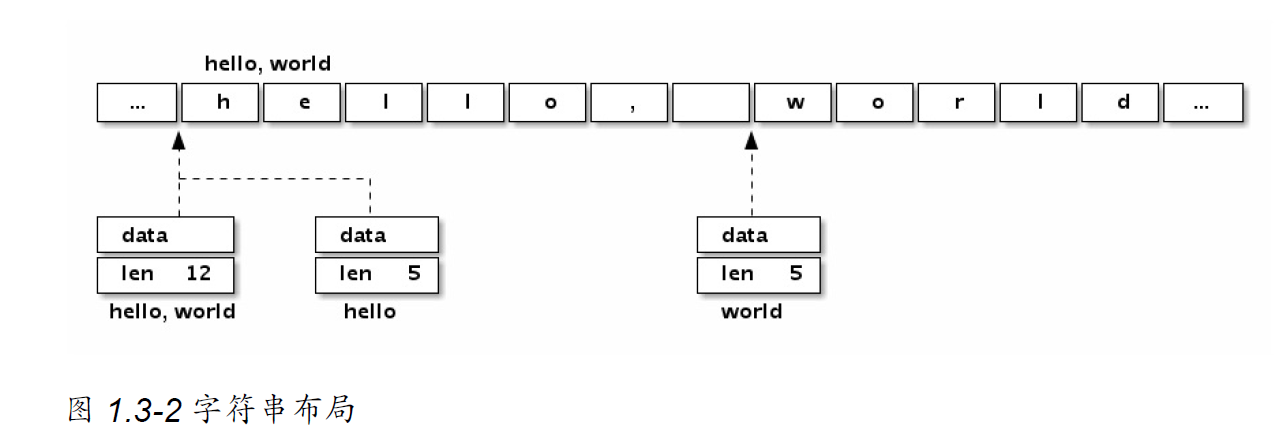
字符串虽然不是切片,但是支持切片操作,不同位置的切片底层也访问的同一块内
存数据(因为字符串是只读的,相同的字符串面值常量通常是对应同一个字符串常
量):
s := "hello, world" hello := s[:5] world := s[7:] s1 := "hello, world"[:5] s2 := "hello, world"[7:]
字符串和数组类似,内置的 len 函数返回字符串的长度。也可以通
过 reflect.StringHeader 结构访问字符串的长度
fmt.Println("len(s):", (*reflect.StringHeader)(unsafe.Pointer(&s
)).Len) // 12
fmt.Println("len(s1):", (*reflect.StringHeader)(unsafe.Pointer(&
s1)).Len) // 5
fmt.Println("len(s2):", (*reflect.StringHeader)(unsafe.Pointer(&
s2)).Len) // 5
如果不想解码UTF8字符串,想直接遍历原始的字节码,可以将字符串强制转
为 []byte 字节序列后再行遍历(这里的转换一般不会产生运行时开销):
for i, c := range []byte("世界abc") {
fmt.Println(i, c)
}
Go语言除了 for range 语法对UTF8字符串提供了特殊支持外,还对字符串
和 []rune 类型的相互转换提供了特殊的支持。
fmt.Printf("%#v
", []rune("世界")) // []int32{19990
, 30028}
fmt.Printf("%#v
", string([]rune{'世', '界'})) // 世界
从上面代码的输出结果来看,我们可以发现 []rune 其实是 []int32 类型,这里
的 rune 只是 int32 类型的别名,并不是重新定义的类型。 rune 用于表示每个
Unicode码点,目前只使用了21个bit位。
字符串相关的强制类型转换主要涉及到 []byte 和 []rune 两种类型。每个转换
都可能隐含重新分配内存的代价,最坏的情况下它们的运算时间复杂度都
是 O(n) 。不过字符串和 []rune 的转换要更为特殊一些,因为一般这种强制类
型转换要求两个类型的底层内存结构要尽量一致,显然它们底层对应
的 []byte 和 []int32 类型是完全不同的内部布局,因此这种转换可能隐含重新
分配内存的操作。
切片(slice)
切片就是一种简化版的动态数组。因为动态数组的长度是不固定,切片
的长度自然也就不能是类型的组成部分了。
切片的结构定义, reflect.SliceHeader :
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
可以看出切片的开头部分和Go字符串是一样的,但是切片多了一个 Cap 成员表示
切片指向的内存空间的最大容量(对应元素的个数,而不是字节数)。
下图是 x= []int{2,3,5,7,11} 和 y := x[1:3] 两个切片对应的内存结构。
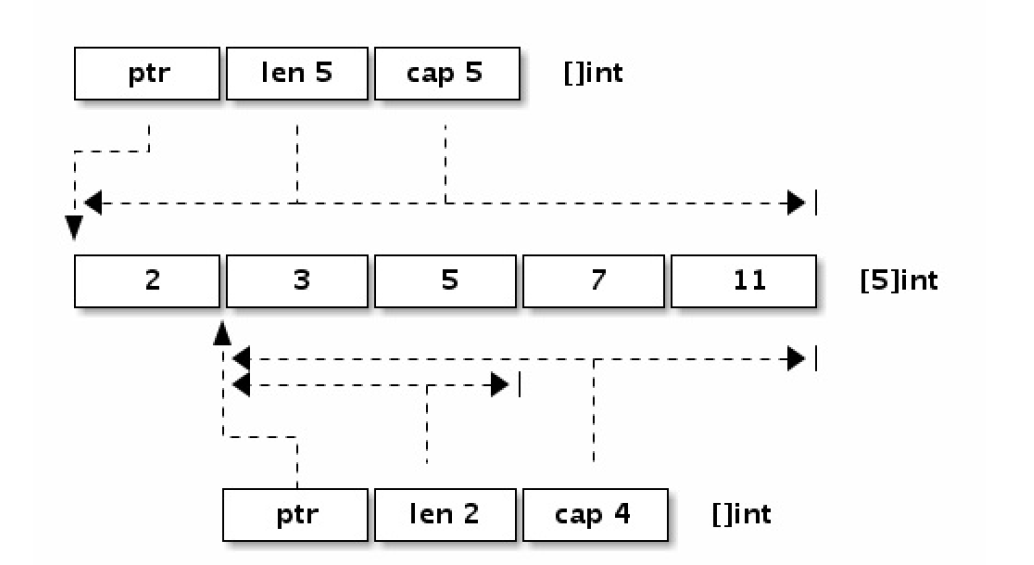
让我们看看切片有哪些定义方式:
var (
a []int // nil切片, 和 nil 相等, 一般用来表示一个不存在的切片
b = []int{} // 空切片, 和 nil 不相等, 一般用来表示一个空的集合
c = []int{1, 2, 3} // 有3个元素的切片, len和cap都为3
d = c[:2] // 有2个元素的切片, len为2, cap为3
e = c[0:2:cap(c)] // 有2个元素的切片, len为2, cap为3
f = c[:0] // 有0个元素的切片, len为0, cap为3
g = make([]int, 3) // 有3个元素的切片, len和cap都为3
h = make([]int, 2, 3) // 有2个元素的切片, len为2, cap为3
i = make([]int, 0, 3) // 有0个元素的切片, len为0, cap为3
)
和数组一样,内置的 len 函数返回切片中有效元素的长度,内置的 cap 函数返回
切片容量大小,容量必须大于或等于切片的长度。也可以通
过 reflect.SliceHeader 结构访问切片的信息(只是为了说明切片的结构,并不
是推荐的做法)。切片可以和 nil 进行比较,只有当切片底层数据指针为空时切
片本身为 nil ,这时候切片的长度和容量信息将是无效的。如果有切片的底层数
据指针为空,但是长度和容量不为0的情况,那么说明切片本身已经被损坏了(比
如直接通过 reflect.SliceHeader 或 unsafe 包对切片作了不正确的修改)。
遍历切片的方式和遍历数组的方式类似:
for i := range a {
fmt.Printf("a[%d]: %d
", i, a[i])
}
for i, v := range b {
fmt.Printf("b[%d]: %d
", i, v)
}
for i := 0; i < len(c); i++ {
fmt.Printf("c[%d]: %d
", i, c[i])
}
在对切片本身赋值或参数传
递时,和数组指针的操作方式类似,只是复制切片头信息
( reflect.SliceHeader ),并不会复制底层的数据。对于类型,和数组的最大
不同是,切片的类型和长度信息无关,只要是相同类型元素构成的切片均对应相同
的切片类型。
添加切片元素
内置的泛型函数 append 可以在切片的尾部追加 N 个元素:
var a []int
a = append(a, 1) // 追加1个元素
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
a = append(a, []int{1,2,3}...) // 追加一个切片, 切片需要解包
不过要注意的是,在容量不足的情况下, append 的操作会导致重新分配内存,可
能导致巨大的内存分配和复制数据代价。即使容量足够,依然需要用 append 函数
的返回值来更新切片本身,因为新切片的长度已经发生了变化。
除了在切片的尾部追加,我们还可以在切片的开头添加元素:
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加1个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片
在开头一般都会导致内存的重新分配,而且会导致已有的元素全部复制1次。因
此,从切片的开头添加元素的性能一般要比从尾部追加元素的性能差很多。
由于 append 函数返回新的切片,也就是它支持链式操作。我们可以将多
个 append 操作组合起来,实现在切片中间插入元素:
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内
容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 。
可以用 copy 和 append 组合可以避免创建中间的临时切片,同样是完成添加元
素的操作:
a = append(a, 0) // 切片扩展1个空间 copy(a[i+1:], a[i:]) // a[i:]向后移动1个位置 a[i] = x // 设置新添加的元素
第一句 append 用于扩展切片的长度,为要插入的元素留出空间。第二
句 copy 操作将要插入位置开始之后的元素向后挪动一个位置。第三句真实地将新
添加的元素赋值到对应的位置。操作语句虽然冗长了一点,但是相比前面的方法,
可以减少中间创建的临时切片。
用 copy 和 append 组合也可以实现在中间位置插入多个元素(也就是插入一个切
片):
a = append(a, x...) // 为x切片扩展足够的空间 copy(a[i+len(x):], a[i:]) // a[i:]向后移动len(x)个位置 copy(a[i:], x) // 复制新添加的切片
稍显不足的是,在第一句扩展切片容量的时候,扩展空间部分的元素复制是没有必
要的。没有专门的内置函数用于扩展切片的容量, append 本质是用于追加元素而
不是扩展容量,扩展切片容量只是 append 的一个副作用。
删除切片元素
根据要删除元素的位置有三种情况:从开头位置删除,从中间位置删除,从尾部删
除。其中删除切片尾部的元素最快:
a = []int{1, 2, 3}
a = a[:len(a)-1] // 删除尾部1个元素
a = a[:len(a)-N] // 删除尾部N个元素
删除开头的元素可以直接移动数据指针:
a = []int{1, 2, 3}
a = a[1:] // 删除开头1个元素
a = a[N:] // 删除开头N个元素
删除开头的元素也可以不移动数据指针,但是将后面的数据向开头移动。可以
用 append 原地完成(所谓原地完成是指在原有的切片数据对应的内存区间内完
成,不会导致内存空间结构的变化):
a = []int{1, 2, 3}
a = append(a[:0], a[1:]...) // 删除开头1个元素
a = append(a[:0], a[N:]...) // 删除开头N个元素
也可以用 copy 完成删除开头的元素:
a = []int{1, 2, 3}
a = a[:copy(a, a[1:])] // 删除开头1个元素
a = a[:copy(a, a[N:])] // 删除开头N个元素
对于删除中间的元素,需要对剩余的元素进行一次整体挪动,同样可以
用 append 或 copy 原地完成:
a = []int{1, 2, 3, ...}
a = append(a[:i], a[i+1:]...) // 删除中间1个元素
a = append(a[:i], a[i+N:]...) // 删除中间N个元素
a = a[:i+copy(a[i:], a[i+1:])] // 删除中间1个元素
a = a[:i+copy(a[i:], a[i+N:])] // 删除中间N个元素
删除开头的元素和删除尾部的元素都可以认为是删除中间元素操作的特殊情况。
切片内存技巧
切片高效操作的要点是要降低内存分配的次数,尽量保证 append 操作不会超
出 cap 的容量,降低触发内存分配的次数和每次分配内存大小。
避免切片内存泄漏
可以将感兴趣的数据复制到一个新的切片中(数据的传值是Go语
言编程的一个哲学,虽然传值有一定的代价,但是换取的好处是切断了对原始数据
的依赖):
假设切片里存放的是指针对象,那么
下面删除末尾的元素后,被删除的元素依然被切片底层数组引用,从而导致不能及
时被自动垃圾回收器回收(这要依赖回收器的实现方式):
var a []*int{ ... }
a = a[:len(a)-1] // 被删除的最后一个元素依然被引用, 可能导致GC操作被阻碍
保险的方式是先将需要自动内存回收的元素设置为 nil ,保证自动回收器可以发
现需要回收的对象,然后再进行切片的删除操作:
var a []*int{ ... }
a[len(a)-1] = nil // GC回收最后一个元素内存
a = a[:len(a)-1] // 从切片删除最后一个元素
当然,如果切片存在的周期很短的话,可以不用刻意处理这个问题。因为如果切片
本身已经可以被GC回收的话,切片对应的每个元素自然也就是可以被回收的了。
Go语言实现中非0大小数组的长度不得超过
2GB,因此需要针对数组元素的类型大小计算数组的最大长度范围( []uint8 最
大2GB, []uint16 最大1GB,以此类推,但是 []struct{} 数组的长度可以超
过2GB)。