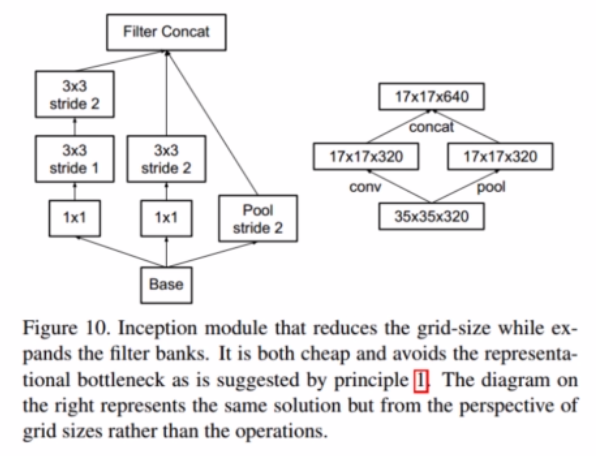
是一个高效的特征图分辨率下降方式
one-hot 带来的问题:
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
1)无法保证模型的泛化能力,容易造成过拟合;
2) 全概率和0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难adapt。会造成模型过于相信预测的类别。

AB中使用了大卷积核分成小卷积核堆叠;CDE中用了非对称卷积形式
1) CNN的分类是CNN视觉任务的基础:在分类上表现好的CNN,通常在其它视觉任务中也表现良好
2)Google很多论文的最优结果均是通过大量实验得出,一般玩家难以复现
3)非对称卷积分解在分辨率为12-20的特征图上效果较好,且用1x7和7x1进行特征提取
4)在网络训练初期,辅助分类层的加入并没有加快网络收敛,在训练后期,才加快网络的收敛
5)移除两个辅助分类层中的第一个,并不影响网络性能
6)标签平滑参数设置,让非标签的概率保持在10-4左右(参数可改一下)