简介
包括以下知识 主要学习mysql数据库
引入
数据库称为数据管理系统,这个数据管理系统我们称之为DBMS,DB(database)就是数据库的意义,M(manage)就是管理的意思,S(system)就是系统的意思,其实就是英文名的首字符缩写。市场上冒出了很多优秀的数据库管理系统,例如:mysql、oracle、db2等等,人家开发好了,你使用就行了,既然是使用别人写好的数据库管理系统,那么我们在操作的时候,就要按照人家的规范来操作,这个规范叫做sql,我们通过这个系统来操作数据的语句叫做sql语句。那么过程就是这个样子的:首先下载安装人家的数据管理系统,然后启动系统,我们的项目如果想通过这个系统来操作数据,那么就需要你的项目中字节写一个socket客户端,要满足人家这个系统的服务端的消息格式要求,然后就按照人家规定好的sql语句写好操作数据的命令,使用你的写好的客户端通过网络发送给这个存放数据的机器上的数据管理系统的服务端,服务端街道这个命令之后,解析,然后产生对应的数据操作,你要是查询数据,就将查询数来的数据原路返回给你,如果你要是修改数据,那么我服务端就在系统上修改对应的数据。这就是整个操作流程了,其实这个系统就是一个基于socket编写的C/S架构的软件。
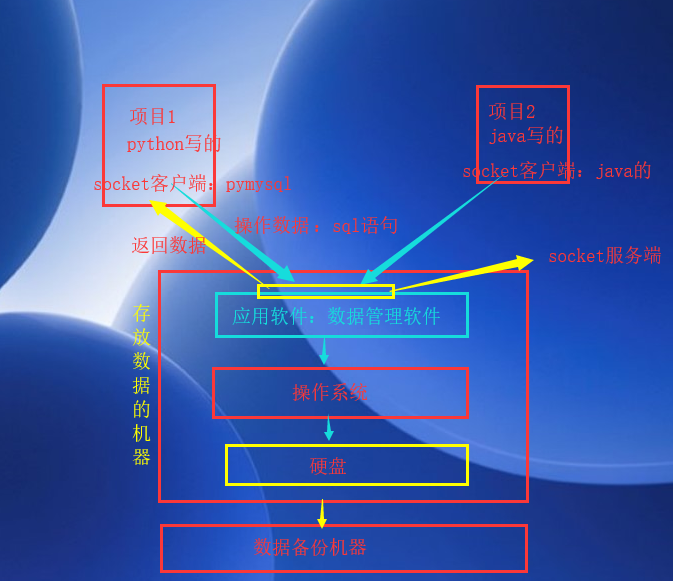
为什要用数据库有什么优势
之所以用数据库原因如下
第一,将文件和程序存在一台机器上是很不合理的。
第二,操作文件是一件很麻烦的事
数据库的优势
1.程序稳定性 :这样任意一台服务所在的机器崩溃了都不会影响数据和另外的服务。
2.数据一致性 :所有的数据都存储在一起,所有的程序操作的数据都是统一的,就不会出现数据不一致的现象
解决了多个服务同时使用数据的一致性间题
3.并发 :数据库可以良好的支持并发,所有的程序操作数据库都是通过网络,而数据库本身支持并发的网络操作,不需要我们自己写socket 解决了并发问题
4.效率 :使用数据库对数据进行增删改查的效率要高出我们自己处理文件很多 操作文件的效率和便捷问题
数据库分类
目前的数据库可以分为两个大类:关系型数据库和非关系型数据库
MySQL、Oracle、SQLite、Access、MS SQL Server
#数据库分类:
关系型数据库:mysql oracle. sglserver. sgllite accesse 表的形式 关联性强 模糊查询 查询稍慢
非关系型数据库:redis. mongodb. memcache(内存级别) 键值对形式 利用键查询快 利用值查询慢
关系型数据库
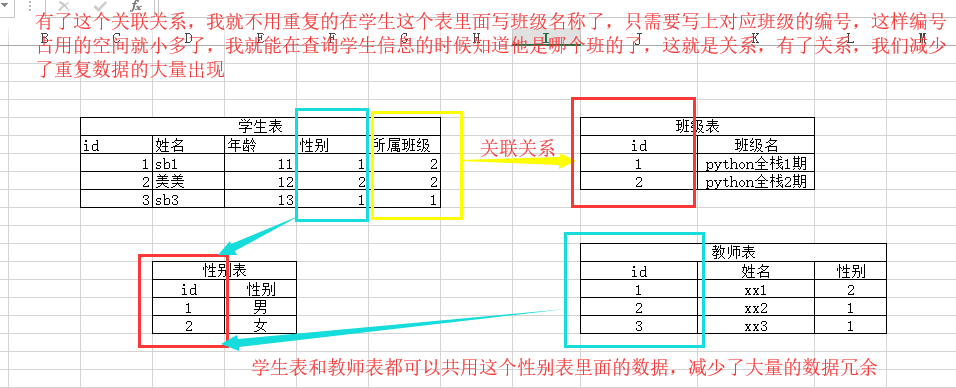
解释:关系型数据库模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式,不是excel,但是和excel的形式很像),结合下图来看一下,
操作关系型数据库的命令,我们称之为SQL,看解释
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ "S-Q-L"),是一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。
结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统, 可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
1986年10月,美国国家标准协会对SQL进行规范后,以此作为关系式数据库管理系统的标准语言(ANSI X3. 135-1986),1987年得到国际标准组织的支持下成为国际标准。不过各种通行的数据库系统在其实践过程中都对SQL规范作了某些编改和扩充。所以,实际上不同数据库系统之间的SQL不能完全相互通用
常见的关系型数据库介绍
2.1.1 oracle数据库
Oracle前身叫SDL、由Larry Ellison和两个变成任意在1977创办,他们开发了主机的拳头产品,在市场上大量销售。Oracle公司是最早开发关系型数据库的厂商之一,其产品支持最广泛的操作系统平台。目前Oracle关系数据库产品的市场占有率数一数二 。
Oracle公司是目前全球最大的数据库软件公司,也是近年业务增长极为迅速的软件提供与服务商
主要应用范围:传统大企业、大公司、政府、金融、证券等。
版本升级:oracle8i,oracle9i,oracle10g,oracle11g,oracle12c
2.1.2 MySQL
MySQL被广泛的应用在Internet上的大中小型网站中。由于体积小、速度快、总体拥有成本低,开放源代码
2.1.3 MariaDB数据库
MAriaDB数据库管理系统是MySQL数据库的一个分支,主要由开元社区维护,采用GPL授权许可。开发这个MariaDB的原因之一是:甲骨文公司收购了MySQL后,有MySQL闭源的潜在风险,因此MySQL开元社区采用分支的方式来避开这个风险。
MariaDB基于事务的Maria存储引擎,替换了MySQL的MyISAM的存储引擎,它使用了Percona的XtraDB(InnoDB的变体)这个版本还包括了PrimeBase XT (PBXT)和Federated X存储引擎。
2.1.4 SQL Server数据库
Microsoft SQL Server是微软公司开发的大型关系数据库系统。SQL Server的功能比较全面,效率高,可以作为中型企业或单位的数据库平台。SQL Server可以与Winodws操作系统紧密集成,不论是应用程序开发速度还是系统事务处理运行速度,都得到较大的提升,对于在Windows平台上开发的各种企业级信息管理系统来说,不论是C/S(客户机/服务器)架构还是B/S(浏览器/服务器)架构。SQL Server都是一个很好的选择。SQL Server的缺点是只能在Windows系统下运行
2.1.5 Access数据库
Access是入门级小型桌面数据库,性能安全性都很一般,可供个人管理或小型企业只用
Access不是数据库语言,只是一个数据库程序,目前最新版本为Office 2007,其特点主要如下:
(1)完善地管理各种数据库对象,具有强大的数据组织,用户管理、安全检查等功能
(2)强大的数据处理功能,在一个工作组级别的网络环境中,使用Access开发的多用户管理系统具有传统的XSASE(DBASE、FoxBASE的统称)数据库系统所无法实现的客户服务器(Ckient/Server)结构和响应的数据库安全机制,Access具备了许多先进的大型数据管理管理系统所具备的特征。
(3)可以方便地生成各种数据对象,利用存储的数据建立窗体和报表
(4)作为Office套件的一部分,可以与Office集成,实现无缝连接
(5)能够利用Web检索和发布数据,实现与Internet的连接,Access主要适用于中小企业应用系统,或作为客户机/服务器系统中的客户端数据库。
2.1.6 其他不常用关系型数据库
DB2,PostgreSQL,Informix,Sybase等。这些关系型数据库逐步的淡化了普通运维的实现,特别是互联网公司几乎见不到
非关系型数据库
非关系型数据库也被成为NoSQL数据库,NOSQL的本意是“Not Olnly SQL”
指的是非关系型数据库,而不是“No SQL”的意思,因此,NoSQL的产生并不是要彻底地否定关系型数据库,而是作为传统关系型数据库的一个有效补充。NOSQL数据库在特定的场景下可以发挥出难以想象的高效率和高性能。
随着互联网Web2.0网站的星期,传统的关系型数据库在应付web2,0网站,特别是对于规模日益扩大的海量数据,超大规模和高并发的微博、微信、SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题。
例如:传统的关系型数据库IO瓶颈、性能瓶颈都难以有效突破,于是出现了大批针对特定场景,以高性能和使用便利为目的功能特异化的数据库产品。NOSQL(非关系型)类的数据就是在这样的情景下诞生并得到了非常迅速的发展
高性能、高并发、对数据一致性要求不高
开源的NoSQL体系,如Facebook的Cassandra,Apache的HBase,也得到了广泛认同,Redis,mongb也逐渐越来越受到各类大中小型公司的欢迎和追捧
NOSQL非关系型数据库小结:
1、NOSQL不是否定关系数据库,而是作为关系数据库的一个重要补充
2、NOSQL为了高性能、高并发而生,忽略影响高性能,高并发的功能
3、NOSQL典型产品memcached (纯内存),redis(持久化缓存),mongodb(文档的数据库)
常见的非关系型数据库
2.2.1 memcached(key-value)
Memcaced是一个开源的、高性能的、具有分布式内存对象的缓存系统。通过它可以减轻数据库负载,加速动态的web应用,最初版本由LiveJoumal 的Brad Fitzpatrick在2003年开发完成。目前全球有非常多的用户都在使用它来架构主机的大负载网站或提升主机的高访问网站的响应速度。注意:Memcache 是这个项目的名称,而Memcached是服务端的主程序文件名。
缓存一般用来保存一些进程被存取的对象或数据,通过缓存来存取对象或数据要比在磁盘上存取块很多,前者是内存,后者是磁盘、Memcached是一种纯内存缓存系统,把经常存取的对象或数据缓存在memcached的内存中,这些被缓存的数据被程序通过API的方式被读取,memcached里面的数据就像一张巨大的hash表,数据以key-value对的方式存在。Memcached通过缓存经常被存取的对象或数据,从而减轻频繁读取数据库的压力,提高网站的响应速度,构建出快速更快的可扩展的Web应用。
官网:http://memcached.org/
由于memcached为纯内存缓存软件,一旦重启所有数据都会丢失,因此,新浪网基于Memcached开发了一个开源项目Memcachedb。通过为Memcached增加Berkeley DB的特久化存储机制和异步主复制机制,使Memcached具备了事务恢复能力、持久化数据能力和分布式复制能力,memcached非常适合需要超高性能读写速度、持久化保存的应用场景,但是最近几年逐渐被其他的持久化产品替代如Redis
Memcached小结:
1、key-value行数据库
2、纯内存数据库
3、持久化memcachedb(sina)
2.2.2 Redis(key-value)
和Memcached类似,redis也是一个key-value型存储系统。但redis支持的存储value类型相对更多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)等。这些数据类型都支持push/pop、add/remove及取交集、并集和差集及更丰富的操作,而且这些操作都是原子性的。为了保证效率,redis的数据都是缓存在内存中。区别是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在基础上实现了master-slave(主从)同步。
redis是一个高性能的key-value数据库。redis的出现、很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Python、Ruby、Erlang、PHP客户端,使用方便。
官方:http://www.redis.io/documentation
redis特点:
1)支持内存缓存,这个功能相当于memcached
2)支持持久化存储,这个功能相当于memcachedb,ttserver
3)数据库类型更丰富。比其他key-value库功能更强
4)支持主从集群、分布式
5)支持队列等特殊功能
应用:缓存从存取memcached更改存取redis
2.2.3 MongoDB(Document-oriented)
MongoDB是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能最丰富,最像关系数据库的。他支持的数据库结构非常松散,类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongodb最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
特点:
高性能、易部署、易使用、存储数据非常方便
主要功能特性:
1.面向集合存储,易存储对象类型的数据
2.“面向集合”(Collenction-Orented)意思是数据库被分组存储在数据集中,被称为一个集合(Collenction)每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档,集合的概念类似关系型数据库(RDBMS)里的表(table)不同的是它不需要定义任何模式(schema)
3.模式自由
模式自由(schema-free)意为着存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。
4.支持动态查询
5.支持完全索引,包含内部对象
6.支持查询
7.支持复制和故障恢复
8.使用高效的二进制数据存储,包括大型对象
9.自动处理碎片、以支持云计算层次的扩展性
2.2.4 Cassandra(Column-oriented)
Apache Cassndra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于存储特别大的数据。Facebook目前在使用此系统。
主要特点:
1.分布式
2.基于column的结构化
3.高伸展性
4.Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成一个分布式网络服务,对Cassandra的一个写操作,会被复制到其他节点上去,对Cassandra的读操作。也会被路由到某个节点上面去读取。
Cassandir是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynomie(分布式的key-value存储系统)更丰富,Cassandra最初由Facebook开发,后转变成了开源项目。
2.2.5 其他不常用非关系型数据库
HBase、MemcacheDB、BerkeleyDB、Tokyo CabinetTokyo Tyrant(ttserver)
ttserver 持久化输出,缺点存储2千万条 性能下降(由日本人发明)
MySQL下载安装
以windows来举例。
mysql下载地址:https://dev.mysql.com/downloads,如果你在mysql官网下载的是zip压缩包,看操作,注意和上面第一种方法的下载网址不同:
然后按照下面的选择来下载,发现是zip压缩包对吧,zip压缩包解压之后就能用,上面的msi还需要安装一下,安装的时候可以选择很多的依赖环境一起安装:
点击download进来:
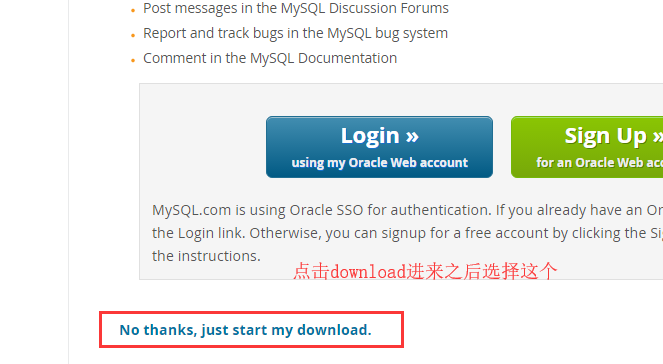
下载完成以后进行安装:
1. 解压MySQL压缩包,将以下载的MySQL压缩包解压到自定义目录下。我放在D:Program FilesMySQL
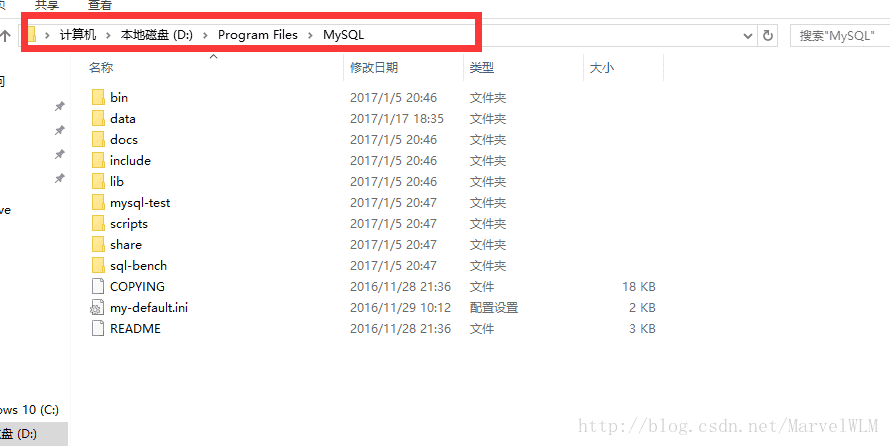
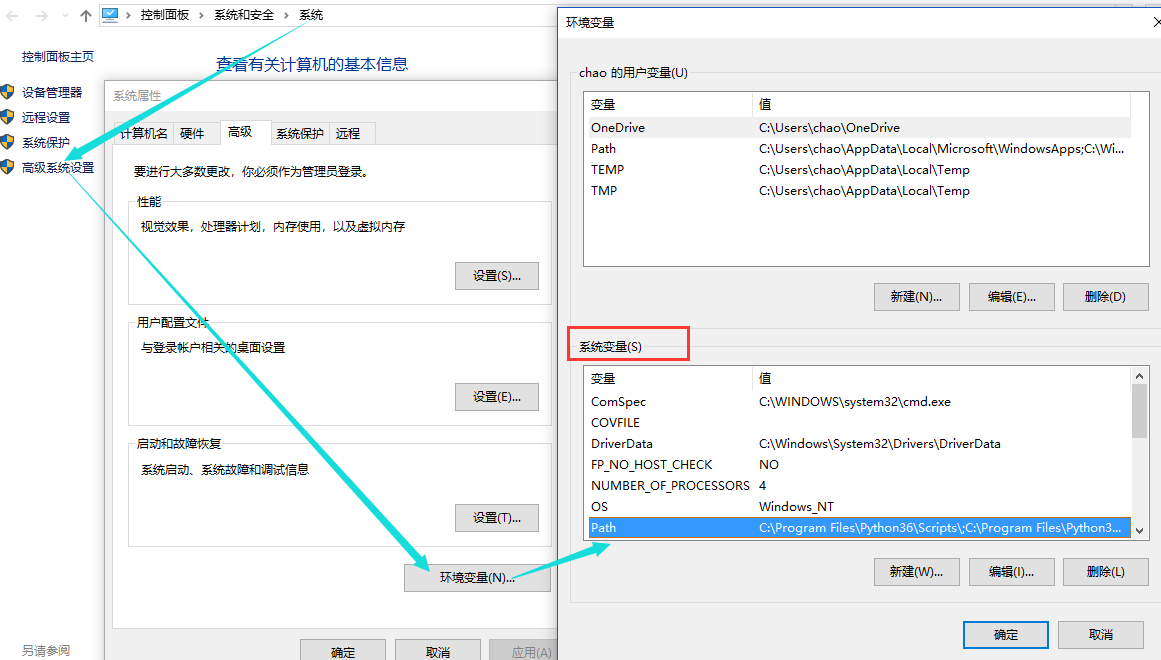
2. 解压完成之后其实就可以用了,但是为了方便使用,也就是在cmd启动mysql的时候,就不用加上全路径了,所以添加一下环境变量,将bin这个文件夹添加到环境变量,bin这个文件夹中有mysqld服务端,有mysql自带的一个客户端,所以添加了环境变量之后,在cmd中直接就可以使用了。
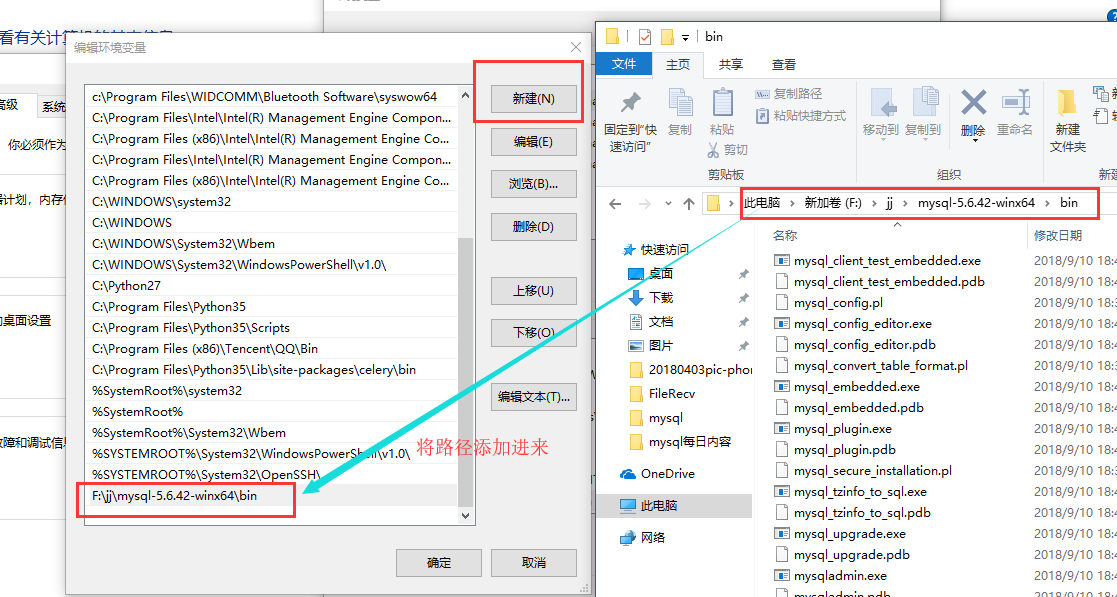
这样就将我们的mysql服务端(mysqld)和mysql自带的一个客户端(供用户在本机测试用的,也是cmd窗口下使用的,客户端叫做mysql,后面操作的时候会使用到)
然后我们直接在cmd窗口就可以启动mysql服务端了,并且可以在任务管理起里面查看。
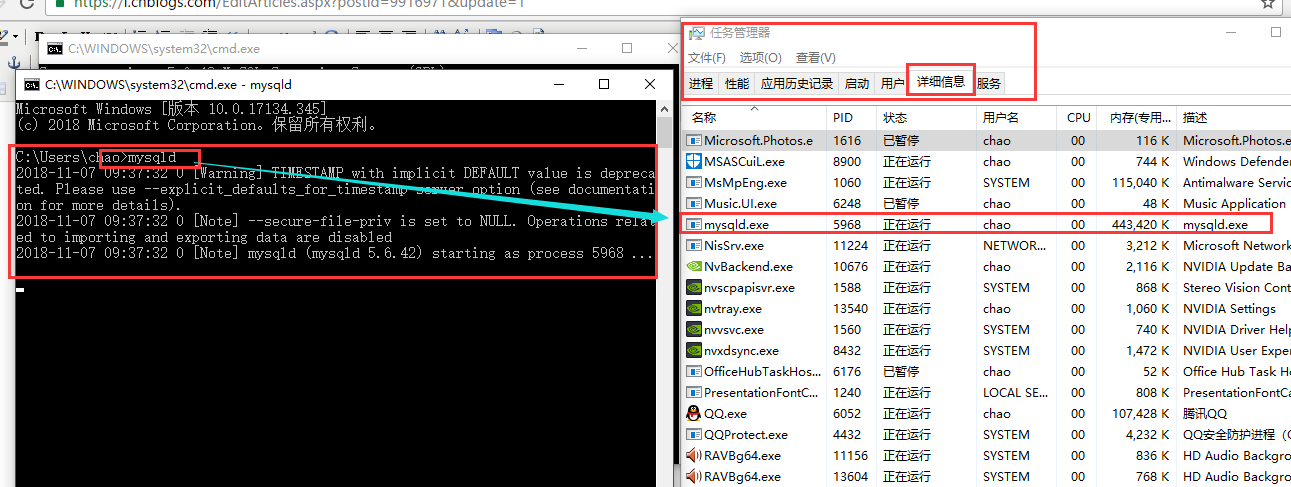
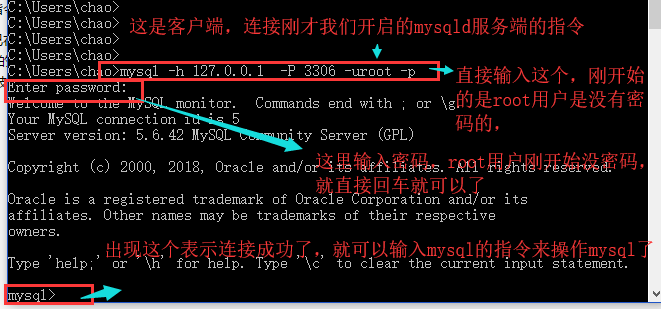
然后我们再启动一个cmd窗口来使用一下mysql客户端,然后连接一下我们开启的服务端,就可以成功了。
连接指令是:mysql -h 服务端IP地址 -P(大写) 3306(mysql服务端默认端口) -uroot(用户,这里我使用root用户来测了) -p密码 。注意:如果这样直接输入密码的话,密码和前面的-p中间不要有空格。
我自己在本机进行测试的,所以我写的mysql服务端的IP地址为我本机的回环地址127.0.0.1,其实如果是自己测试本机的mysql服务端,我们可以不用写ip地址和端口的,直接写mysql -uroot -p,但是连接别的电脑的mysql的时候一定要写IP地址和端口,并且不能用root用户去远程连接别的电脑的mysql服务端,并且要注意mysql服务器上的防火墙是否允许3306能够被外人连接,如果想让别人连,要更改防火墙设置,让他允许3306端口被连接,或者直接关闭防火墙(不建议直接关闭,测试的时候可以用),否则会报错。
ip地址除了写127.0.0.1之外,还可以写localhost,或者自己本机的ip地址,但是写本机的ip地址的时候,服务端会将你的客户端视为外部设备,不允许你这样登陆。
自己本机测试连接的时候,完全可以不用写ip地址和端口
到目前为止,我们就已经可以连接并使用mysql数据库了,但是你发现,关闭mysql服务端比较麻烦,启动的时候我们直接输入的mysqld回车就启动了
关闭的方式有两种:
1.通过任务管理器来关闭服务端:
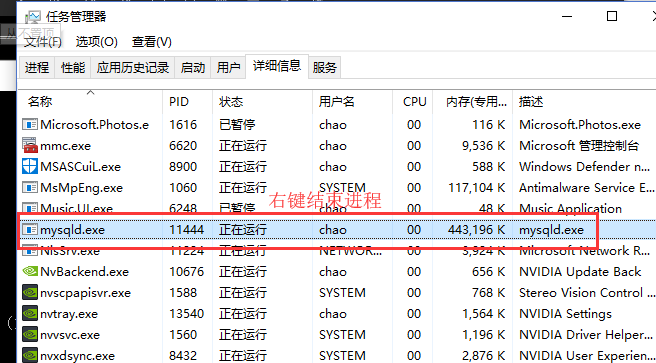
2.通过cmd指令来关闭mysql服务端

所以我们可以通过系统服务的方式来控制mysql服务的开启或者关闭,那么就需要将mysql服务加入到系统服务中,来看一下怎么制作成系统服务:
打开cmd窗口,注意:必须以管理员身份打开cmd窗口,在左下角的地方找到这个圆圈,点击,然后输入cmd,匹配出来命令提示符,然后右键点击,以管理员身份打开
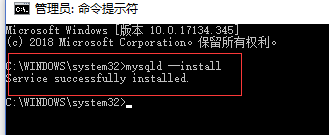
然后输入 mysqld --install 服务名(可以给这个服务一个名字,直接跟在这个指令的后面,不写也可以,会默认有一个,后面可以查看到)
这样就添加系统服务了
然后win键+r 打开运行窗口,里面输入services.msc来打开系统服务列表
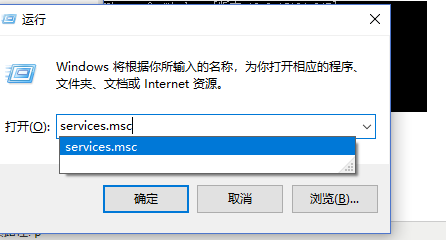
就可以看到mysqld服务了,如果没有就点击上面的刷新按钮
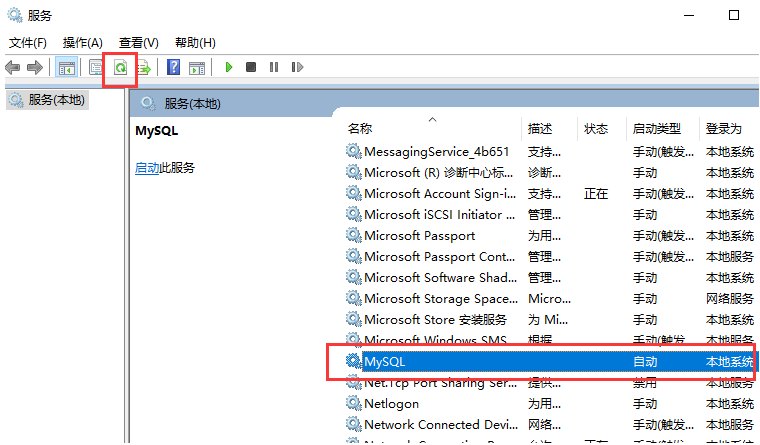
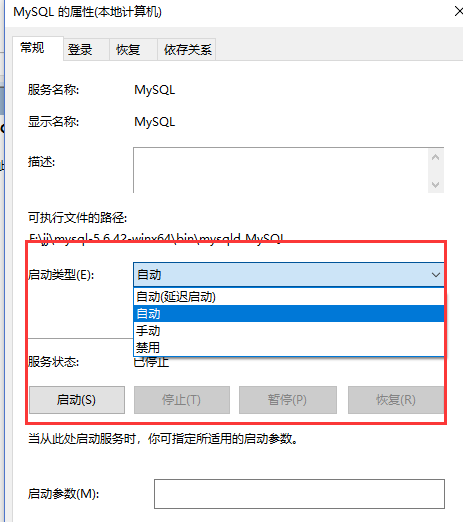
选中MySQL服务这一项,我们就可以直接右键查看功能,功能里面有启动和关闭,就可以通过系统服务的形式来启动和关闭MySQL服务了,这个服务是默认开启的,我们也可以自行设置是否自动开机启动等等的行为,左键双击一下这个服务你就看到下面的窗口了。
添加了系统服务以后,我们在启动和关闭这个mysql服务,就可以在cmd窗口下使用两个指令就搞定了:
启动指令:net start mysql
关闭指令:net stop mysql
并且不能再使用 mysqld指令直接启动了。

还可以通过指令来移除刚才添加的系统服务:
cmd下移除服务命令为:mysqld remove
简单总结
#1、下载:MySQL Community Server 5.7.16
http://dev.mysql.com/downloads/mysql/
#2、解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:mysql-5.7.16-winx64
#3、添加环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】
#4、初始化
mysqld --initialize-insecure
#5、启动MySQL服务
mysqld # 启动MySQL服务
#6、启动MySQL客户端并连接MySQL服务
mysql -u root -p # 连接MySQL服务器
#7、将mysql添加系统服务
注意:--install前,必须用mysql启动命令的绝对路径
# 制作MySQL的Windows服务,在终端执行此命令:
"c:mysql-5.7.16-winx64inmysqld" --install
# 移除MySQL的Windows服务,在终端执行此命令:
"c:mysql-5.7.16-winx64inmysqld" --remove
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
# 启动MySQL服务
net start mysql
# 关闭MySQL服务
net stop mysql
mysql 删除
net stop mysql 停mysqL服务
mysqld remove删除服务
#把安装软件也删掉
#删除环境变量
#清除注册表/重启计算机
3.删除相关注册表信息
在Win7开始菜单栏搜索 regedit 进入注册表编辑器(在cmd下输入此命令也是可以打开的)
路径1:HKEY_LOCAL_MACHINESYSTEMControlSet001serviceseventlogApplicationMySQL
路径1:HKEY_LOCAL_MACHINESYSTEMControlSet002serviceseventlogApplicationMySQL
删除整个MySQL文件夹即可
mysql安装
路径
1.路径不能有中文
2.路径中不能有特殊字符
修改配置文件
1.编码utf-8
2.所有的配置项后面不要有特殊的符号
3.修改两个路径basedir datadir
检测文件的扩展名设置
工具-->文件夹选项-->查看-->扩展名 不要隐藏
配置环境变量
在系统变量中的path中添加 mysql的安装目录的bin的路径 列如C:mysqlmysql-5.6.45-winx64in
以管理员的身份重新打开一个cmd
安装MySQL服务
以管理员身份打开cmd窗口后,将目录切换到你解压文件的bin目录,输入mysqld install 回车运行
启动mysql服务
以管理员身份在cmd中输入:net start mysql
服务启动成功之后,就可以登录了,输入mysql -u root -p(第一次登录没有密码,直接按回车过)
set password = password('123'); # 给当前数据库设置密码 123密码
切换目录
d: 切换到d盘
c: 切换到c盘
cd C:mysql-5.6.44-winx64in到此目录
mysql找不到服务或系统找不到指定路径或无法启动mysql服务的解决方法
https://blog.csdn.net/XP1990/article/details/79542680
解决方法:删除系统中MySQL服务,命令为 SC DELETE MYSQL;执行之后,你会发现系统服务列表中,MySQL已经消失。
配置文件
注意
配置文件必须无空格,必须utf-8 所有的配置项后面不要有特殊的符号**
修改两个路径basedir datadir
basedir 对应mysql的安装目录
datadir对应mysql的安装目录的data路径
my.ini
[client]
#设置mysql客户端默认字符集
default-character-set=utf8
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
# 设置默认账户密码
user = 'root'
password = '123'
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=D:mysqlmysql-5.6.44-winx64
# 设置mysql数据库的数据的存放目录
datadir=D:mysqlmysql-5.6.44-winx64data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
#设置严格模式
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
mysql的创建登录修改删除用户的操作
创建用户和授权
https://www.cnblogs.com/clschao/articles/10050473.html
自己的电脑 管理员用户
# 登录方式 mysq 进入客户端
# 需要使用管理员root用户登陆 之前不输入msql
# mysql -uroot -p # mysql5.6默认是没有密码的
# #遇到password直接按回车键
#第2种 mysql -u用户名 -p用户密码
# mysql> set password = password('123'); # 给当前数据库设置密码 123密码
# 使用公司的数据库 管理员会创建-个账号给你用
# 自己的数据库借给别人用 也可以创建一个账号给别人
# mysql -uroot -p # mysql5.6默认是没有密码的
# #遇到password直接按回车键
#第2种 mysql -u用户名 -p用户密码
MySQL客户端连接服务端时的完整指令
mysql -h 127.0.0.1 -P 3306 -u root -p
修改密码
4.1第一种修改密码方式,当你忘记密码的时候使用这种方式修改
如果密码忘了怎么办?
1 停掉MySQL服务端(net stop mysql)
2 切换到MySQL安装目录下的bin目录下,然后手动指定启动程序来启动mysql服务端,指令: mysqld.exe --skip-grant-tables
3 重新启动一个窗口,连接mysql服务端,
4 修改mysql库里面的user表里面的root用户记录的密码:
update user set password = password('666') where user='root';
5 关掉mysqld服务端,指令:
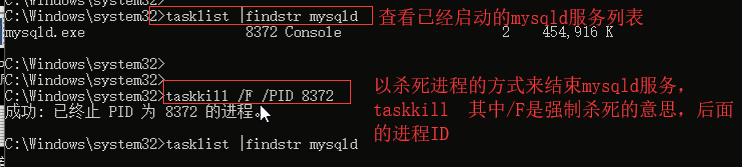
tasklist|findstr mysqld #查看mysqld 的id
taskkill /F /PID 进程号 #关闭进程
6 正常启动服务端(net start mysql)
4.2第二种当你没有忘记密码的时候,想要去修改密码建议使用这种方式,因为简单
mysqladmin -uroot -p1234 password 123
创建子账号
#创建账号
# mysql> create user 'saoqiang'@'192.168.13.%' identified by '123';# 指示网段
# mysql> create user 'eva'@'192.168.10.5' # 指示某机器可以连接
# mysql> create user 'eva'@'%' identified by '123'; #指示所有机器都可以连接
# mysql> show grants for 'eva'@'192.168.10.5';查看某个用户的权限
# # 创建账号并授权
# mysql> grant all on *.* to 'eva'@'%' identified by '123'
# 查看所有用户
#select user,host from mysql.user;
#mysql> select user(); #查看当前用户名
#mysql> exit # 也可以用q quit退出
用户授权
# 给账号授权 登录情况下(*代表所有)增删改查all所有 select查看
# mysql> grant all on *.* to 'eva'@'%';
# mysql> grant all on *.* to '用户名'@'对应用户名IP地址';
# mysql> grant select on *.* to 'eva'@'%';#查看
# mysql> grant all on 数据库.表 to '用户名'@'地址'; # 给一个存在的eva账号授权
# mysql> flush privileges; # 刷新使授权立即生效
# # 创建账号并授权
# mysql> grant all on *.* to 'eva'@'%' identified by '123'
删除子用户
drop user '骚强'@'host'; #删除已存在的用户 host 代表他的id
实列
drop user '骚强'@'127.01.0.1'; #删除已存在的用户 host 代表他的id
远程登陆他人账户
# 远程登陆 未登录情况下
# $ mysql -uroot -p123 -h 192.168.10.3 #对方的ip
mysql -uroot -p1031 -h 192.168.16.153
MySQL库和表的操作
库操作
创建库
1.1 语法
CREATE DATABASE 数据库名 charset utf8;
1.2 数据库命名规则
可以由字母、数字、下划线、@、#、$
区分大小写
唯一性
不能使用关键字如 create select
不能单独使用数字
最长128位
其他操作
1 查看数据库
show databases;
show create database db1;
select database();
2 选择数据库
USE 数据库名
3 删除数据库
DROP DATABASE 数据库名;
4 修改数据库
alter database db1 charset utf8;
存储引擎
存储引擎介绍
存储引擎即表类型,mysql根据不同的表类型会有不同的处理机制。
首先确定一点,存储引擎的概念是MySQL里面才有的,不是所有的关系型数据库都有存储引擎这个概念,后面我们还会说,但是现在要确定这一点。
在讲清楚什么是存储引擎之前,我们先来个比喻,我们都知道录制一个视频文件,可以转换成不同的格式,例如mp4,avi,wmv等,而存在我们电脑的磁盘上也会存在于不同类型的文件系统中如windows里常见的ntfs、fat32,存在于linux里常见的ext3,ext4,xfs,但是,给我们或者用户看懂实际视频内容都是一样的。直观区别是,占用系统的空间大小与清晰程度可能不一样。
那么数据库表里的数据存储在数据库里及磁盘上和上述的视频格式及存储磁盘文件的系统格式特征类似,也有很多种存储方式。
但是对于用户和应用程序来说同样一张表的数据,无论用什么引擎来存储,用户能够看到的数据是一样的。不同储引擎存取,引擎功能,占用空间大小,读取性能等可能有区别。说白了,存储引擎就是在如何存储数据、提取数据、更新数据等技术方法的实现上,底层的实现方式不同,那么就会呈现出不同存储引擎有着一些自己独有的特点和功能,对应着不同的存取机制。
因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即:对表的存储、操作等的实现方法不同),表是什么,表本质上就是磁盘上的文件。
其实MySQL支持多种存储引擎,每种引擎有着一些自己独特的功能,用户在使用的时候,可以根据自己的业务场景来使用不同的存储引擎,其中MySQL最常用的存储引擎为:MyISAM和InnoDB。
在详细介绍这些存储引擎之前,我们先来看看MySQL的整个工作流程,看一下存储引擎在哪里,MySQL都做了哪些事情。
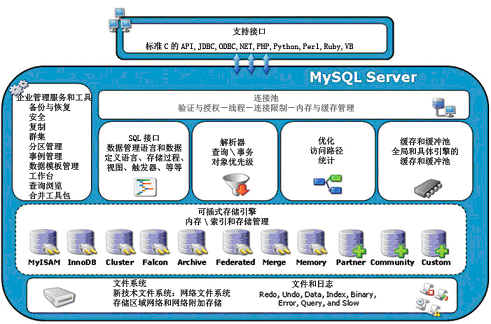
总结
存储引擎 -- 存储数据的方式
一张表含有如下
数据
表的结构
索引(查询的时候使用的一个目录结构)
面试题
你了解mysql的存储引擎么?
你的项目用了什么存储引擎,为什么?
innodb
多个用户操作的过程中对同一张表的数据同时做修改
innodb支持行级锁,所以我们使用了这个存储引擎
为了适应程序未来的扩展性,扩展新功能的时候可能会用到...,涉及到要维护数据的完整性
项目中有一两张xx xx表,之间的外键关系是什么,一张表的修改或者删除比较频繁,怕出错所以做了外键约束
数据的存储方式 -- 存储引擎engines innodb常用 myisam memory
使用不同的存储引擎,数据是以不同的方式存储的
show engines; 查看存储引擎
mysql支持哪些存储引擎?
mysql5.6支持的存储引擎包括InnoDB、MyISAM、MEMORY、CSV、BLACKHOLE、FEDERATED、MRG_MYISAM、ARCHIVE、PERFORMANCE_SCHEMA。其中NDB和InnoDB提供事务安全表,其他存储引擎都是非事务安全表。
最常见
Innodb Myisam Memory
存储引擎分类
先看几条指令
show engines;#查看MySQL所有的引擎,
show variables like "storage_engine%";查看当前正在使用的引擎
MyISAM引擎
特点
MyISAM引擎特点:
1.不支持事务
事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功要么全失败。
2.表级锁定
数据更新时锁定整个表:其锁定机制是表级锁定,也就是对表中的一个数据进行操作都会将这个表锁定,其他人不能操作这个表,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。
3.读写互相阻塞
不仅会在写入的时候阻塞读取,MyISAM还会再读取的时候阻塞写入,但读本身并不会阻塞另外的读。
4.只会缓存索引
MyISAM可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。
5.读取速度较快
占用资源相对较少
6.不支持外键约束,但只是全文索引
# Myisam存储引擎 mysql5.5之前的默认的存储引擎
# 数据和索引不存储在一起 3个文件
# 数据索引表结构
# 数据持久化
# 只支持表锁
InnoDB引擎
特点
InnoDB引擎
介绍:InnoDB引擎是MySQL数据库的另一个重要的存储引擎,正称为目前MySQL AB所发行新版的标准,被包含在所有二进制安装包里。和其他的存储引擎相比,InnoDB引擎的优点是支持兼容ACID的事务(类似于PostGreSQL),以及参数完整性(即对外键的支持)。Oracle公司与2005年10月收购了Innobase。Innobase采用双认证授权。它使用GNU发行,也允许其他想将InnoDB结合到商业软件的团体获得授权。
InnoDB引擎特点:
1.支持事务:支持4个事务隔离界别,支持多版本读。
2.行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是表锁,注意间隙锁的影响。
3.读写阻塞与事务隔离级别相关(有多个级别,这就不介绍啦~)。
4.具体非常高效的缓存特性:能缓存索引,也能缓存数据。
5.整个表和主键与Cluster方式存储,组成一颗平衡树。(了解)
6.所有SecondaryIndex都会保存主键信息。(了解)
7.支持分区,表空间,类似oracle数据库。
8.支持外键约束,不支持全文索引(5.5之前),以后的都支持了。
9.和MyISAM引擎比较,InnoDB对硬件资源要求还是比较高的。
小结:三个重要功能:Supports transactions,row-level locking,and foreign keys
# Innodb存储引擎 mysql5.6之后的默认的存储引擎
# 数据和索引存储在一起 2个文件
# 数据索引表结构
# 数据持久化
# 支持事务 : 为了保证数据的完整性,将多个操作变成原子性操作 : 保持数据安全
# 支持行级锁 : 修改的行少的时候使用 : 修改数据频繁的操作
# 支持表级锁 : 批量修改多行的时候使用 : 对于大量数据的同时修改 加锁
# 支持外键 : 约束两张表中的关联字段不能随意的添加删除 : 能够降低数据增删改的出错率
Memory存储引擎
# Memory存储引擎
# 数据存储在内存中, 1个文件
# 表结构
# 数据断电消失

创建表时指定引擎的命令
create table t1(id int)engine=innodb; #指定innodb
create table t2(id int)engine=myisam; #指定myisam
事务介绍
简单地说,事务就是指逻辑上的一组SQL语句操作,组成这组操作的各个SQL语句,执行时要么全成功要么全失败。
例如:你给我转账5块钱,流程如下
a.从你银行卡取出5块钱,剩余计算money-5
b.把上面5块钱打入我的账户上,我收到5块,剩余计算money+5.
上述转账的过程,对应的sql语句为:
update 你_account set money=money-5 where name='你';
update 我_account set money=money+5 where name='我';
上述的两条SQL操作,在事务中的操作就是要么都执行,要么都不执行,不然钱就对不上了。
这就是事务的原子性(Atomicity)。
事务的四大特性:
1.原子性(Atomicity)
事务是一个不可分割的单位,事务中的所有SQL等操作要么都发生,要么都不发生。
2.一致性(Consistency)
事务发生前和发生后,数据的完整性必须保持一致。
3.隔离性(Isolation)
当并发访问数据库时,一个正在执行的事务在执行完毕前,对于其他的会话是不可见的,多个并发事务之间的数据是相互隔离的。也就是其他人的操作在这个事务的执行过程中是看不到这个事务的执行结果的,也就是他们拿到的是这个事务执行之前的内容,等这个事务执行完才能拿到新的数据。
4.持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的。如果出了错误,事务也不允撤销,只能通过'补偿性事务'。
表操作
创建表
建表语法
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
#注意:
1. 在同一张表中,字段名是不能相同
2. 宽度和约束条件可选、非必须,宽度指的就是字段长度约束,例如:char(10)里面的10
3. 字段名和类型是必须的
表操作简单示例
mysql> create database db1 charset utf8;
mysql> use db1;
mysql> create table t1(
-> id int,
-> name varchar(50),
-> sex enum('male','female'),
-> age int(3)
-> );
mysql> show tables; #查看db1库下所有表名
mysql> desc t1;
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
mysql> select id,name,sex,age from t1;
Empty set (0.00 sec)
mysql> select * from t1;
Empty set (0.00 sec)
mysql> select id,name from t1;
Empty set (0.00 sec)
插入数据简单操作
mysql> insert into t1 values
-> (1,'chao',18,'male'),
-> (2,'sb',81,'female')
-> ;
mysql> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | chao | 18 | male |
| 2 | sb | 81 | female |
+------+------+------+--------+
mysql> insert into t1(id) values
-> (3),
-> (4);
mysql> select * from t1;
+------+------+------+--------+
| id | name | age | sex |
+------+------+------+--------+
| 1 | chao | 18 | male |
| 2 | sb | 81 | female |
| 3 | NULL | NULL | NULL |
| 4 | NULL | NULL | NULL |
+------+------+------+--------+
查看表结构
看语法
mysql> describe t1; #查看表结构,可简写为:desc 表名
+-------+-----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| sex | enum('male','female') | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-----------------------+------+-----+---------+-------+
mysql> show create table t1G; #查看表详细结构,可加G
基础数据类型
数值类型
整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT
作用:存储年龄,等级,id,各种号码等

注意:对于整型来说,数据类型后面的宽度并不是存储长度限制,而是显示限制,假如:int(8),那么显示时不够8位则用0来填充,够8位则正常显示,通过zerofill来测试,存储长度还是int的4个字节长度。默认的显示宽度就是能够存储的最大的数据的长度,比如:int无符号类型,那么默认的显示宽度就是int(10),有符号的就是int(11),因为多了一个符号,所以我们没有必要指定整数类型的数据,没必要指定宽度,因为默认的就能够将你存的原始数据完全显示。
浮点型
定点数类型 DEC,等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、温度、体重、体质参数等
1.FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
单精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值为255,d最大值为30,例如:float(255,30)
有符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38
精确度:
**** 随着小数的增多,精度变得不准确 ****
2.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
双精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值也为255,d最大值也为30
有符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
无符号:
2.2250738585072014E-308 to 1.7976931348623157E+308
精确度:
****随着小数的增多,精度比float要高,但也会变得不准确 ****
3.decimal[(m[,d])] [unsigned] [zerofill]
定义:
准确的小数值,m是整数部分+小数部分的总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。比float和double的整数个数少,但是小数位数都是30位
精确度:
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decimal能够存储精确值的原因在于其内部按照字符串存储。
精度从高到低:decimal、double、float
decimal精度高,但是整数位数少
float和double精度低,但是整数位数多
float已经满足绝大多数的场景了,但是什么导弹、航线等要求精度非常高,所以还是需要按照业务场景自行选择,如果又要精度高又要整数位数多,那么你可以直接用字符串来存。
浮点型测试示例
mysql> create table t1(x float(256,31));
ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30.
mysql> create table t1(x float(256,30));
ERROR 1439 (42000): Display width out of range for column 'x' (max = 255)
mysql> create table t1(x float(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t2(x double(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t3(x decimal(66,31));
ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30.
mysql> create table t3(x decimal(66,30));
ERROR 1426 (42000): Too-big precision 66 specified for 'x'. Maximum is 65.
mysql> create table t3(x decimal(65,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| t1 |
| t2 |
| t3 |
+---------------+
3 rows in set (0.00 sec)
mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1
Query OK, 1 row affected (0.01 sec)
mysql> insert into t2 values(1.1111111111111111111111111111111);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(1.1111111111111111111111111111111);
Query OK, 1 row affected, 1 warning (0.01 sec)
mysql> select * from t1; #随着小数的增多,精度开始不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111164093017600000000000000 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111200000000000000 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111111111111111111 |
+----------------------------------+
1 row in set (0.00 sec)
日期类型
类型:DATE,TIME,DATETIME ,TIMESTAMP,YEAR
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
简单介绍
YEAR
YYYY(范围:1901/2155)2018
DATE
YYYY-MM-DD(范围:1000-01-01/9999-12-31)例:2018-01-01
TIME
HH:MM:SS(范围:'-838:59:59'/'838:59:59')例:12:09:32
DATETIME
YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00/9999-12-31 23:59:59 Y)例: 2018-01-01 12:09:32
TIMESTAMP
YYYYMMDD HHMMSS(范围:1970-01-01 00:00:00/2037 年某时)
mysql的日期格式对字符串采用的是'放松'政策,可以以字符串的形式插入。
日期类型测试示例
year:
mysql> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4)
mysql> insert into t10 values
-> (1900),
-> (1901),
-> (2155),
-> (2156);
mysql> select * from t10;
+-----------+
| born_year |
+-----------+
| 0000 |
| 1901 |
| 2155 |
| 0000 |
+-----------+
date,time,datetime:
mysql> create table t11(d date,t time,dt datetime);
mysql> desc t11;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| d | date | YES | | NULL | |
| t | time | YES | | NULL | |
| dt | datetime | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
mysql> insert into t11 values(now(),now(),now());
mysql> select * from t11;
+------------+----------+---------------------+
| d | t | dt |
+------------+----------+---------------------+
| 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 |
+------------+----------+---------------------+
timestamp:
mysql> create table t12(time timestamp);
mysql> insert into t12 values();
mysql> insert into t12 values(null);
mysql> select * from t12;
+---------------------+
| time |
+---------------------+
| 2017-07-25 16:29:17 |
| 2017-07-25 16:30:01 |
+---------------------+
============注意啦,注意啦,注意啦===========
1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
2. 插入年份时,尽量使用4位值
3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
>=70,以19开头,比如71,结果1971
mysql> create table t12(y year);
mysql> insert into t12 values
-> (50),
-> (71);
mysql> select * from t12;
+------+
| y |
+------+
| 2050 |
| 1971 |
+------+
============综合练习===========
mysql> create table student(
-> id int,
-> name varchar(20),
-> born_year year,
-> birth date,
-> class_time time,
-> reg_time datetime);
mysql> insert into student values
-> (1,'sb1',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"),
-> (2,'sb2',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"),
-> (3,'sb3',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13");
mysql> select * from student;
+------+------+-----------+------------+------------+---------------------+
| id | name | born_year | birth | class_time | reg_time |
+------+------+-----------+------------+------------+---------------------+
| 1 | sb1 | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 |
| 2 | sb2 | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 |
| 3 | sb3 | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 |
+------+------+-----------+------------+------------+---------------------+
字符串类型
类型:char,varchar
作用:名字,信息等等
官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
注意:char和varchar括号内的参数指的都是字符的长度
#char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错(严格模式下),存<10个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时,查出的结果会自动删除尾部的空格,如果你想看到它补全空格之后的内容,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH';)
#varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
检索:
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
char和varchar性能对比
以char(5)和varchar(5)来比较,加入我要存三个人名:sb,ssb1,ssbb2
**char:**
优点:简单粗暴,不管你是多长的数据,我就按照规定的长度来存,5个5个的存,三个人名就会类似这种存储:sb ssb1 ssbb2,中间是空格补全,取数据的时候5个5个的取,简单粗暴速度快
缺点:貌似浪费空间,并且我们将来存储的数据的长度可能会参差不齐
**varchar:**
varchar类型不定长存储数据,更为精简和节省空间
例如存上面三个人名的时候类似于是这样的:sbssb1ssbb2,连着的,如果这样存,请问这三个人名你还怎么取出来,你知道取多长能取出第一个吗?(超哥,我能看出来啊,那我只想说:滚犊子!)
不知道从哪开始从哪结束,遇到这样的问题,你会想到怎么解决呢?还记的吗?想想?socket?tcp?struct?把数据长度作为消息头。
所以,varchar在存数据的时候,会在每个数据前面加上一个头,这个头是1-2个bytes的数据,这个数据指的是后面跟着的这个数据的长度,1bytes能表示2**8=256,两个bytes表示2**16=65536,能表示0-65535的数字,所以varchar在存储的时候是这样的:1bytes+sb+1bytes+ssb1+1bytes+ssbb2,所以存的时候会比较麻烦,导致效率比char慢,取的时候也慢,先拿长度,再取数据。
优点:节省了一些硬盘空间,一个acsii码的字符用一个bytes长度就能表示,但是也并不一定比char省,看一下官网给出的一个表格对比数据,当你存的数据正好是你规定的字段长度的时候,varchar反而占用的空间比char要多。
其他的字符串类型:BINARY、VARBINARY、BLOB、TEXT

其他类型简单介绍
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
BLOB:
1._BLOB和_text存储方式不同,_TEXT以文本方式存储,英文存储区分大小写,而_Blob是以二进制方式存储,不分大小写。
2._BLOB存储的数据只能整体读出。
3._TEXT可以指定字符集,_BLO不用指定字符集。
枚举类型和集合类型
字段的值只能在给定范围中选择,如单选框,多选框,如果你在应用程序或者前端不做选项限制,在MySQL的字段里面也能做限制
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
示例:
枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
集合类型(set)
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
简单测试
mysql> create table consumer(
-> name varchar(50),
-> sex enum('male','female'),
-> level enum('vip1','vip2','vip3','vip4','vip5'), #在指定范围内,多选一
-> hobby set('play','music','read','study') #在指定范围内,多选多
-> );
mysql> insert into consumer values
-> ('xiaogui','male','vip5','read,study'),
-> ('taibai','female','vip1','girl');
mysql> select * from consumer;
+------+--------+-------+------------+
| name | sex | level | hobby |
+------+--------+-------+------------+
| xiaogui | male | vip5 | read,study |
| taibai | female | vip1 | |
+------+--------+-------+------------+
完整性约束
not null和default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1(
nid int not null defalut 2,
num int not null
);
先说一点:在我们插入数据的时候,可以这么写insert into tb1(nid,num) values(1,‘chao’);就是在插入输入的时候,指定字段插入数据,如果我在只给num插入值,可以这样写insert into tb1(num) values('chao');还可以插入数据的时候,指定插入数据字段的顺序:把nid和num换个位置,但是对应插入的值也要换位置。注意:即便是你只给一个字段传值了,那么也是生成一整条记录,这条记录的其他字段的值如果可以为空,那么他们就都是null空值,如果不能为空,就会报错。
简单测试
==================not null====================
mysql> create table t1(id int); #id字段默认可以插入空
mysql> desc t1;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t1 values(); #可以插入空
mysql> create table t2(id int not null); #设置字段id不为空
mysql> desc t2;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> insert into t2 values(); #不能插入空
ERROR 1364 (HY000): Field 'id' doesn't have a default value
==================default====================
#设置id字段有默认值后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
mysql> create table t3(id int default 1);
mysql> alter table t3 modify id int not null default 1;
==================综合练习====================
mysql> create table student(
-> name varchar(20) not null,
-> age int(3) unsigned not null default 18,
-> sex enum('male','female') default 'male',
-> hobby set('play','study','read','music') default 'play,music'
-> );
mysql> desc student;
+-------+------------------------------------+------+-----+------------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------------------------+------+-----+------------+-------+
| name | varchar(20) | NO | | NULL | |
| age | int(3) unsigned | NO | | 18 | |
| sex | enum('male','female') | YES | | male | |
| hobby | set('play','study','read','music') | YES | | play,music | |
+-------+------------------------------------+------+-----+------------+-------+
mysql> insert into student(name) values('chao');
mysql> select * from student;
+------+-----+------+------------+
| name | age | sex | hobby |
+------+-----+------+------------+
| chao| 18 | male | play,music |
+------+-----+------+------------+
unique
独一无二,唯一属性:id,身份证号等
简单测试
============设置唯一约束 UNIQUE===============
方法一:
create table department1(
id int,
name varchar(20) unique,
comment varchar(100)
);
方法二:
create table department2(
id int,
name varchar(20),
comment varchar(100),
constraint uk_name unique(name)
);
mysql> insert into department1 values(1,'IT','技术');
Query OK, 1 row affected (0.00 sec)
mysql> insert into department1 values(1,'IT','技术');
ERROR 1062 (23000): Duplicate entry 'IT' for key 'name'
primary key
从约束角度看primary key字段的值不为空且唯一。
简单测试
============单列做主键===============
#方法一:not null+unique
create table department1(
id int not null unique, #主键
name varchar(20) not null unique,
comment varchar(100)
);
mysql> desc department1;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | UNI | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec)
#方法二:在某一个字段后用primary key
create table department2(
id int primary key, #主键
name varchar(20),
comment varchar(100)
);
mysql> desc department2;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.00 sec)
#方法三:在所有字段后单独定义primary key
create table department3(
id int,
name varchar(20),
comment varchar(100),
constraint pk_name primary key(id); #创建主键并为其命名pk_name
mysql> desc department3;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| comment | varchar(100) | YES | | NULL | |
+---------+--------------+------+-----+---------+-------+
rows in set (0.01 sec
auto_increment
之前我们插入数据的时候,id也需要自己来写,是不是很麻烦啊,我们是不是想,只要有一条记录就直接插入进去啊,不需要考虑说,你现在存储到第多少条数据了,对不对,所以出现了一个叫做auto_increment的属性
约束字段为自动增长,被约束的字段必须同时被key约束,也就是说只能给约束成key的字段加自增属性,默认起始位置为1,步长也为1.
简单测试
#不指定id,则自动增长
create table student(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') default 'male'
);
mysql> desc student;
+-------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | YES | | male | |
+-------+-----------------------+------+-----+---------+----------------+
mysql> insert into student(name) values
-> ('egon'),
-> ('alex')
-> ;
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
| 2 | alex | male |
+----+------+------+
#也可以指定id
mysql> insert into student values(4,'asb','female');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(7,'wsb','female');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+------+--------+
| id | name | sex |
+----+------+--------+
| 1 | egon | male |
| 2 | alex | male |
| 4 | asb | female |
| 7 | wsb | female |
+----+------+--------+
#对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
mysql> delete from student;
Query OK, 4 rows affected (0.00 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> insert into student(name) values('ysb');
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 8 | ysb | male |
+----+------+------+
#应该用truncate清空表,比起delete一条一条地删除记录,truncate是直接清空表,在删除大表时用它
mysql> truncate student;
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student(name) values('egon');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+------+
| id | name | sex |
+----+------+------+
| 1 | egon | male |
+----+------+------+
1 row in set (0.00 sec)
设置严格模式
设置严格模式:
不支持对not null字段插入null值
不支持对自增长字段插入”值
不支持text字段有默认值
直接在mysql中生效(重启失效):
mysql>set sql_mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION";
配置文件添加(永久失效):
sql-mode="STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION"
表其他操作
修改表
看语法
语法:
1. 修改表名
ALTER TABLE 表名
RENAME 新表名;
2. 增加字段
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…], #注意这里可以通过逗号来分割,一下添加多个约束条件
ADD 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] FIRST; #添加这个字段的时候,把它放到第一个字段位置去。
ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;#after是放到后的这个字段的后面去了,我们通过一个first和一个after就可以将新添加的字段放到表的任意字段位置了。
3. 删除字段
ALTER TABLE 表名
DROP 字段名;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…]; #change比modify还多了个改名字的功能,这一句是只改了一个字段名
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件…];#这一句除了改了字段名,还改了数据类型、完整性约束等等的内容
给一个字段添加外键属性的语句:alter table 表2名 add foreign key(表2的一个字段) references 表1名(表1的一个字段);
注意一点:在mysql里面表名是不区分大小写的,如果你将一个名为t1的(小写的t1)改名为一个T1(大写的T1),是完全没用的,因为在数据库里面表名都是小写的。
简单测试
示例:
1. 修改存储引擎
mysql> alter table service
-> engine=innodb;
2. 添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; //添加name字段之后
mysql> alter table student10
-> add sex enum('male','female') default 'male' first; //添加到最前面
3. 删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4. 修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; //修改为主键
5. 增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6. 对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7. 增加主键
mysql> alter table student1
-> modify name varchar(10) not null primary key;
8. 增加主键和自动增长
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9. 删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;
查看所有表
show tables;
删除表
drop table 表名;
清空表
delete from 表名;
truncate 表名; #会将auto_increment的起始数据重置为1。
单表数据的操作
增加
看语法
1. 插入完整数据(顺序插入)
语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n); #指定字段来插入数据,插入的值要和你前面的字段相匹配
语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n); #不指定字段的话,就按照默认的几个字段来插入数据
2. 指定字段插入数据
语法:
INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
3. 插入多条记录
语法:#插入多条记录用逗号来分隔
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
4. 插入查询结果
语法:
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …; #将从表2里面查询出来的结果来插入到我们的表中,但是注意查询出来的数据要和我们前面指定的字段要对应好
更新
看语法
语法:
UPDATE 表名 SET
字段1=值1, #注意语法,可以同时来修改多个值,用逗号分隔
字段2=值2,
WHERE CONDITION; #更改哪些数据,通过where条件来定位到符合条件的数据
示例:
UPDATE mysql.user SET password=password(‘123’)
where user=’root’ and host=’localhost’; #这句话是对myslq这个库中的user表中的user字段为'root'并且host字段为'localhost'的这条记录的password字段的数据进行修改,将passord字段的那个数据改为password('123')这个方法对123加工后的密码数据,password()这个方法是mysql提供的密码进行加密用的方法。
定位到某个记录,并把这个记录中的某项内容更改掉
删除
看语法
语法:
DELETE FROM 表名
WHERE CONITION; #删除符合条件的一些记录
DELETE FROM 表名;如果不加where条件,意思是将表里面所有的内容都删掉,但是清空所有的内容,一般我们用truncate ,能够将id置为零,delete不能将id置零,再插入数据的时候,会按照之前的数据记录的id数继续递增
示例:
DELETE FROM mysql.user
WHERE password=’123’;
练习:
更新MySQL root用户密码为mysql123
删除除从本地登录的root用户以外的所有用户
单查询操作
我们在工作中,多数的场景都是对数据的增删改操作少,读数据的操作多,所以我们的重点就在读取数据这里了。我们先来把单表查询学习一下。
单表查询语法
看语法
#查询数据的本质:mysql会到你本地的硬盘上找到对应的文件,然后打开文件,按照你的查询条件来找出你需要的数据。下面是完整的一个单表查询的语法
select * from,这个select * 指的是要查询所有字段的数据。
SELECT distinct 字段1,字段2... FROM 库名.表名 #from后面是说从库的某个表中去找数据,mysql会去找到这个库对应的文件夹下去找到你表名对应的那个数据文件,找不到就直接报错了,找到了就继续后面的操作
WHERE 条件 #从表中找符合条件的数据记录,where后面跟的是你的查询条件
GROUP BY field(字段) #分组
HAVING 筛选 #过滤,过滤之后执行select后面的字段筛选,就是说我要确定一下需要哪个字段的数据,你查询的字段数据进行去重,然后在进行下面的操作
ORDER BY field(字段) #将结果按照后面的字段进行排序
LIMIT 限制条数 #将最后的结果加一个限制条数,就是说我要过滤或者说限制查询出来的数据记录的条数
以上语句中关键字的执行顺序
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.将分组的结果进行having过滤
5.执行select
6.去重
7.将结果按条件排序:order by
8.限制结果的显示条数
简单查询练习
先来创建表和插入一些数据
#我们来创建一个员工表,然后对员工表进行一个简单的查询,来看一下效果,下面是员工表的字段
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部,全都是老师
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
简单查询练习
查询所有员工的id,姓名年龄
SELECT id,name,sex,age FROM employee;
查询所有字段数据
SELECT * FROM employee;
查询员工的姓名和工资
SELECT name,salary FROM employee;
where条件
where语句中可以使用:
之前我们用where 后面跟的语句是不是id=1这种类型的啊,用=号连接的,除了=号外,还能使用其他的,看下面:
- 比较运算符:> < >= <= <> !=
- between 80 and 100 值在80到100之间
- in(80,90,100) 值是80或90或100
- like 'egon%'
pattern可以是%或_,
%表示任意多字符
_表示一个字符
- 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
简单操作
#1:单条件查询
SELECT name FROM employee
WHERE post='sale'; #注意优先级,我们说where的优先级是不是比select要高啊,所以我们的顺序是先找到这个employee表,然后按照post='sale'的条件,然后去表里面select数据
#2:多条件查询
SELECT name,salary FROM employee
WHERE post='teacher' AND salary>10000;
#3:关键字BETWEEN AND 写的是一个区间
SELECT name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000; #就是salary>=10000 and salary<=20000的数据
SELECT name,salary FROM employee
WHERE salary NOT BETWEEN 10000 AND 20000; #加个not,就是不在这个区间内,薪资小于10000的或者薪资大于20000的,注意没有等于,
#4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS) 判断null只能用is
SELECT name,post_comment FROM employee
WHERE post_comment IS NULL;
SELECT name,post_comment FROM employee
WHERE post_comment IS NOT NULL;
SELECT name,post_comment FROM employee
WHERE post_comment=''; 注意''是空字符串,不是null,两个是不同的东西,null是啥也没有,''是空的字符串的意思,是一种数据类型,null是另外一种数据类型
ps:
执行
update employee set post_comment='' where id=2;
再用上条查看,就会有结果了
#5:关键字IN集合查询
SELECT name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ; #这样写是不是太麻烦了,写一大堆的or,下面我们用in这个简单的写法来搞
SELECT name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
SELECT name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
#6:关键字LIKE模糊查询,模糊匹配,可以结合通配符来使用
通配符’%’ #匹配任意所有字符
SELECT * FROM employee
WHERE name LIKE 'eg%';
通配符’_’ #匹配任意一个字符
SELECT * FROM employee
WHERE name LIKE 'al__'; #注意我这里写的两个_,用1个的话,匹配不到alex,因为al后面还有两个字符ex。
where条件咱们就说完了,这个where条件到底怎么运作的,我们来说一下:我们以select id,name,age from employee where id>7;这个语句来说一下
首先先找到employee表,找到这个表之后,mysql会拿着where后面的约束条件去表里面找符合条件的数据,然后遍历你表中所有的数据,查看一下id是否大于7,逐条的对比,然后只要发现id比7大的,它就会把这一整条记录给select,但是select说我只拿id、name、age这个三个字段里面的数据,然后就打印了这三个字段的数据,然后where继续往下过滤,看看id是不是还有大于7的,然后发现一个符合条件的就给select一个,然后重复这样的事情,直到把数据全部过滤一遍才会结束。这就是where条件的一个工作方式。
小练习
1. 查看岗位是teacher的员工姓名、年龄
2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄
3. 查看岗位是teacher且薪资在9000-1000范围内的员工姓名、年龄、薪资
4. 查看岗位描述不为NULL的员工信息
5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资
6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资
7. 查看岗位是teacher且名字是jin开头的员工姓名、年薪
答案
select name,age from employee where post = 'teacher';
select name,age from employee where post='teacher' and age > 30;
select name,age,salary from employee where post='teacher' and salary between 9000 and 10000;
select * from employee where post_comment is not null;
select name,age,salary from employee where post='teacher' and salary in (10000,9000,30000);
select name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000);
select name,salary*12 from employee where post='teacher' and name like 'jin%';
分组查询GROUP BY
1、首先明确一点:分组发生在where之后,即分组是基于where之后得到的记录而进行的
2、分组指的是:将所有记录按照某个相同字段进行归类,比如针对员工信息表的职位分组,或者按照性别进行分组等
3、为何要分组呢?是因为我们有时候会需要以组为单位来统计一些数据或者进行一些计算的,对不对,比方说下面的几个例子
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据,只是个小窍门,但是不能表示所有的情况,看上面第三个分组,没有'每'字,这个就需要我们通过语句来自行判断分组依据了
我们能用id进行分组吗,能,但是id是不是重复度很低啊,基本没有重复啊,对不对,这样的字段适合做分组的依据吗?不适合,对不对,依据性别分组行不行,当然行,因为性别我们知道,是不是就两种啊,也可能有三种是吧,这个重复度很高,对不对,分组来查的时候才有更好的意义
4、大前提:
可以按照任意字段分组,但是分组完毕后,比如group by post,只能查看post字段,如果想查看组内信息,需要借助于聚合函数
注意一点,在查询语句里面select 字段 from 表,这几项是必须要有的,其他的什么where、group by等等都是可有可无的
GROUP BY一般都会与聚合函数一起使用,聚合是什么意思:聚合就是将分组的数据聚集到一起,合并起来搞事情,拿到一个最后的结果。
小练习
查询每个岗位的人数
答案
select post,count(id) as count from employee group by post;
#按照岗位分组,并查看每个组有多少人,每个人都有唯一的id号,我count是计算一下分组之后每组有多少的id记录,通过这个id记录我就知道每个组有多少人了
聚合函数
聚合函数一般配合着分组来用,进行一些统计。
SELECT COUNT(*) FROM employee; #count是统计个数用的
SELECT COUNT(*) FROM employee WHERE depart_id=1; #后面跟where条件的意思是统计一下满足depart_id=1这个的所有记录的个数
SELECT MAX(salary) FROM employee; #max()统计分组后每组的最大值,这里没有写group by,那么就是统计整个表中所有记录中薪资最大的,薪资的值
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee; #平均值
SELECT SUM(salary) FROM employee; #总和
SELECT SUM(salary) FROM employee WHERE depart_id=3;
另外在学一个concat()函数:自定义显示格式
CONCAT() 函数用于连接字符串
示例:
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary #我想让name这个字段显示的字段名称是中文的姓名,让salary*12显示的是中文的年薪,
FROM employee;#看结果:通过结果你可以看出,这个concat就是帮我们做字符串拼接的,并且拼接之后的结果,都在一个叫做Annual_salary的字段中了
+---------------------------------------+
| Annual_salary |
+---------------------------------------+
| 姓名: egon 年薪: 87603.96 |
| 姓名: alex 年薪: 12000003.72 |
| 姓名: wupeiqi 年薪: 99600.00 |
| 姓名: yuanhao 年薪: 42000.00 |
.....
+---------------------------------------+
小练习
1. 查询岗位名以及各岗位内包含的员工个数
2. 查询公司内男员工和女员工的个数
3. 查询岗位名以及各岗位的平均薪资
4. 查询岗位名以及各岗位的最高薪资
5. 查询岗位名以及各岗位的最低薪资
6. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资。 #这道题我们自己提炼一下分组依据,是不是就是性别啊
答案
#题目1:
mysql> select post,count(id) from employee group by post;
+-----------------------------------------+-----------+
| post | count(id) |
+-----------------------------------------+-----------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+-----------------------------------------+-----------+
#题目2:
mysql> select sex,count(id) from employee group by sex;
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
#题目3:
mysql> select post,avg(salary) from employee group by post;
+-----------------------------------------+---------------+
| post | avg(salary) |
+-----------------------------------------+---------------+
| operation | 16800.026000 |
| sale | 2600.294000 |
| teacher | 151842.901429 |
| 老男孩驻沙河办事处外交大使 | 7300.330000 |
+-----------------------------------------+---------------+
#题目4:
mysql> select post,max(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | max(salary) |
+-----------------------------------------+-------------+
| operation | 20000.00 |
| sale | 4000.33 |
| teacher | 1000000.31 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目5:
mysql> select post,min(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | min(salary) |
+-----------------------------------------+-------------+
| operation | 10000.13 |
| sale | 1000.37 |
| teacher | 2100.00 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目6:
mysql> select sex,avg(salary) from employee group by sex;
+--------+---------------+
| sex | avg(salary) |
+--------+---------------+
| male | 110920.077000 |
| female | 7250.183750 |
+--------+---------------+
HAVING过滤
讲having之前,我们补充一个点:之前我们写的查询语句是这样的:select id,name from employee;实际上我们在select每个字段的时候,省略了一个表名,有的人可能会这样写,select employee.id,employee.name from employee;你会发现查询出来的结果是一样的,但是如果你要将查询出来的结果表,起一个新表名的话,带着表名这样写就错了
select employee.id,employee.name from employee as tb1;这样执行会下面的报错:
mysql> select employee.id,employee.name from employee as tb1;
ERROR 1054 (42S22): Unknown column 'employee.id' in 'field list'
因为这个语句先执行的是谁啊,是不是我们的from啊,那么后面的as也是比select要先执行的,所以你先将表employee起了个新名字叫做tb1,然后在tb1里面取查询数据,那么tb1里面找不到employee.id这个字段,就会报错,如果我们查询的时候不带表名,你as来起一个新的表名也是没问题的,简单提一下这个内容,知道就好了
HAVING与WHERE不一样的地方在于!!!!!!
having的语法格式和where是一模一样的,只不过having是在分组之后进行的进一步的过滤,where不能使用聚合函数,having是可以使用聚合函数的
执行优先级从高到低:where > group by > having
1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,having是可以使用聚合函数
简单测试
统计各部门年龄在30岁及以上的员工的平均薪资,并且保留平均工资大于10000的部门
答案:select post,avg(salary) as new_sa from employee where age>=30 group by post having avg(salary) > 10000;
看结果:
+---------+---------------+
| post | new_sa |
+---------+---------------+
| teacher | 255450.077500 |
+---------+---------------+
1 row in set (0.00 sec)
然后我们看这样一句话:select * from employee having avg(salary) > 10000;
只要一运行就会报错:
mysql> select * from employee having avg(salary) > 10000;
ERROR 1140 (42000): Mixing of GROUP columns (MIN(),MAX(),COUNT(),...) with no GROUP columns is illegal if there is no GROUP BY clause
是因为having只能在group by后面运行
小练习
1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
3. 查询各岗位平均薪资大于10000的岗位名、平均工资
4. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
答案
#题1:
mysql> select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
+-----------------------------------------+--------------------+-----------+
| post | group_concat(name) | count(id) |
+-----------------------------------------+--------------------+-----------+
| 老男孩驻沙河办事处外交大使 | egon | 1 |
+-----------------------------------------+--------------------+-----------+
#题目2:
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| operation | 16800.026000 |
| teacher | 151842.901429 |
+-----------+---------------+
#题目3:
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000;
+-----------+--------------+
| post | avg(salary) |
+-----------+--------------+
| operation | 16800.026000 |
+-----------+--------------+
去重distinct
将查询的结果进行去重:select distinct post from employee; 注意distinct去重要写在查询字段的前面,不然会报错,关于distinct使用时的其他问题看下面的总结
有时需要查询出某个字段不重复的记录,这时可以使用mysql提供的distinct这个关键字来过滤重复的记录,但是实际中我们往往用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段,distinct 想写在其他字段后面需要配合聚合函数来写。
mysql> select id,count(distinct post) from employee;
ERROR 1140 (42000): Mixing of GROUP columns (MIN(),MAX(),COUNT(),...) with no GROUP columns is illegal if there is no GROUP BY clause
报错了:是因为distinct不能返回其他的字段,只能返回目标字段
mysql> select count(distinct post) from employee;
+----------------------+
| count(distinct post) |
+----------------------+
| 4 |
+----------------------+
1 row in set (0.00 sec)
排序ORDER BY
直接看示例吧
按单列排序
SELECT * FROM employee ORDER BY salary; #默认是升序排列
SELECT * FROM employee ORDER BY salary ASC; #升序
SELECT * FROM employee ORDER BY salary DESC; #降序
按多列排序
但是你看,如果我们按照age来排序,你看看是什么效果:
mysql> SELECT * FROM employee ORDER BY age;
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| id | name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
| 17 | 程咬铜 | male | 18 | 2015-04-11 | operation | NULL | 18000.00 | 403 | 3 |
| 16 | 程咬银 | female | 18 | 2013-03-11 | operation | NULL | 19000.00 | 403 | 3 |
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 18 | 程咬铁 | female | 18 | 2014-05-12 | operation | NULL | 17000.00 | 403 | 3 |
| 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 |
| 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
| 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
+----+------------+--------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
发现什么,按照年龄来升序排的,没问题,但是你看年龄相同的那些按什么排的,是不是看着是乱的啊,但是不管它对这种相同数据的内容怎么排序,我们是不是想如果出现相同的数据,那么这些相同的数据也按照一个依据来排列啊:
所以我们可以给相同的这些数据指定一个排序的依据,看下面:
按多列排序:先按照age升序,如果年纪相同,则按照薪资降序
SELECT * from employee
ORDER BY age, #注意排序的条件用逗号分隔
salary DESC;
小练习
1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列
答案
题目1
mysql> select * from employee ORDER BY age asc,hire_date desc;
题目2
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc;
#注意:查询语句的语法是固定上面这样写的,但是运行顺序是这样的:1、from 2、where 3、group by 4、having 5、select 6、distinct 7、order by 8、limit,我们下面要学的
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| operation | 16800.026000 |
| teacher | 151842.901429 |
+-----------+---------------+
题目3
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| teacher | 151842.901429 |
| operation | 16800.026000 |
+-----------+---------------+
限制查询的记录数LIMIT
直接看示例吧
#取出工资最高的前三位
SELECT * FROM employee ORDER BY salary DESC LIMIT 3; #默认初始位置为0,从第一条开始顺序取出三条
SELECT * FROM employee ORDER BY salary DESC LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
SELECT * FROM employee ORDER BY salary DESC LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
正则表达式查询
看示例
#之前我们用like做模糊匹配,只有%和_,局限性比较强,所以我们说一个正则,之前我们是不是学过正则匹配,你之前学的正则表达式都可以用,正则是通用的
SELECT * FROM employee WHERE name REGEXP '^ale';
SELECT * FROM employee WHERE name REGEXP 'on$';
SELECT * FROM employee WHERE name REGEXP 'm{2}';
小结:对字符串匹配的方式
WHERE name = 'egon';
WHERE name LIKE 'yua%';
WHERE name REGEXP 'on$';
练习
查看所有员工中名字是jin开头,n或者g结果的员工信息
答案
select * from employee where name regexp '^jin.*[g|n]$';
表关系
我们知道,将来我们存的数据表肯定不止一个,并且很多表之间是有关系的,那么到底有什么关系呢,我们来看看。
简单举个例子:(重点理解一下什么是foreign key)
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
那这就体现出来了三个缺点:
1.表的组织结构不清晰:员工的信息、部门的信息等等都掺在一张表里面。
2.浪费空间,每一条信息都包含员工和部门,多个员工从属一个部门,也需要每个员工的信息里都包含着部门的信息,浪费硬盘空间。
3.扩展性极差:如果想修改一个部门的信息,比如修改部门名称,那么这个包含员工和部门信息的表中的所有的包含这个部门信息的数据都需要进行修改,那么修改起来就非常麻烦,这是非常致命的缺点。
解决方法:(画一个excel表格来表示一下效果~~)
我们完全可以定义一个部门表,解耦和
我们虽然将部门表提出来了,但是员工表本身是和部门有联系的,你光把部门信息提出来还是不够的,还需要建立关联
然后让员工信息表关联该表,如何关联,即foreign key
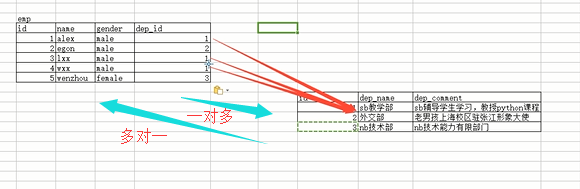
在解释一下:数据要拆到不同表里面存着,你要站在两个表的角度来看两者之间的关系,你站在部门表的角度看,一个部门包含多个员工,站在员工表看,多个员工属于一个部门,以我们上课来举个例子看:现在的多个老师可以讲一个课程python,那么老师对于课程表来说就是多对一个关系,那这是不是就是最终关系呢,我们还需要站在课程表的角度来看,多个课程能不能被一个老师教啊,这个看业务场景,你看咱们学校就不行,讲python的只能讲python,但是我们上的小学,初中,高中是不是多个课程可以被一个老师教啊,所以从老男孩的业务来看,课程表对老师表是一对一的,即便是你多个老师可以讲这一门课程,但是这一门可能对应的那几个老师只能讲这一门,不能讲其他的课程,所以他们只是单纯的多对一的关系,多个老师对应一门课程,但是小学、初中、高中的业务,多个老师可以教一门课程,同样这多个老师每个老师又可以教多门课程,那么从课程表角度来看,多个课程也能从属一个老师,所以是多对多的关系:看下图
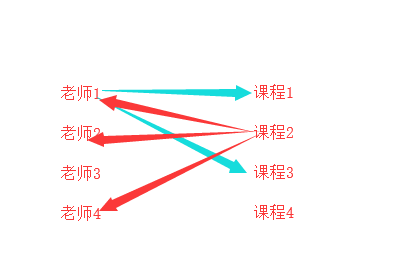
一对多的关系
我们在看看员工和部门这个多对一的关系表:
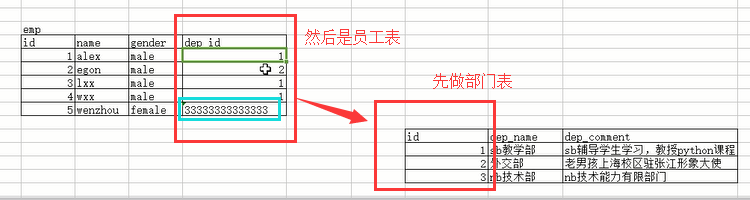
如果我们没有做强制的约束关系,那么在员工表里面那个部门id可以随便写,即便是部门表里面没有这个id号,它也是可以写的,但是这样写就错了,因为业务不允许,并且这个数据完全没用,根本就不存在这个部门,哪里来的这个部门的员工呢,对不对,所以要做一个硬性的关系,你员工里面的部门id一定要来自于部门表的id字段。怎么来做这个硬性关系呢,通过外键foreign key,怎么叫外键,就是跟外部的一个表进行关联,建立这种硬性的关系,就叫做外键,就像我们上面这两个表似的,左边的员工表有一个字段(部门id字段)来自于右边的部门表,那么我们就可以通过数据库在员工表的部门id字段加上一个foreign key,外键关联到右边部门表的id字段,这样就建立了这种硬性的关系了,之前我们是看着两张表之间有关系,但是没有做强制约束,还是两张普通的表,操作其中任何一个,另外一个也没问题,但是加上了这种强制关系之后,他们两个的操作也就都关联起来了,具体操作看下面的代码:
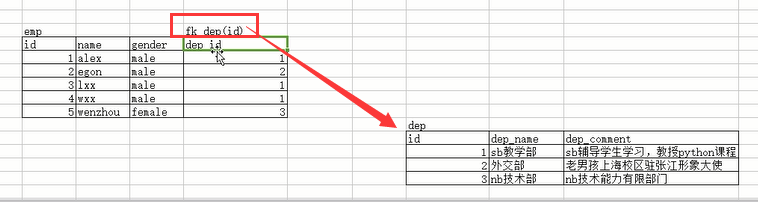
部门表是被关联的表,员工表是关联表,也就是员工表要关联部门表,对吧,如果我们先创建员工表,在创建员工表的时候加外键关系,就会报错,看效果:
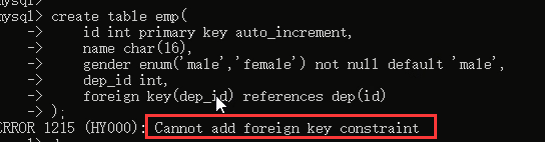
所以我们应该先建立部门表,也就是被关联的表,因为关联表中的字段的数据是来根据被关联表的被关联字段的数据而来的。
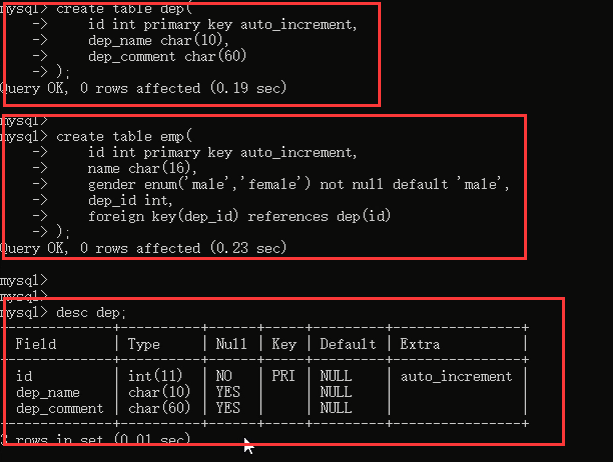
然后看一下表结构:

表创建好了,如果我们直接给员工表插入几条数据,那么会报错,因为,你的部门还没有呢,你的员工表里面的那个dep_id外键字段的数据从何而来啊?看效果:

然后我们先插入部门的数据,然后再插入员工的数据:
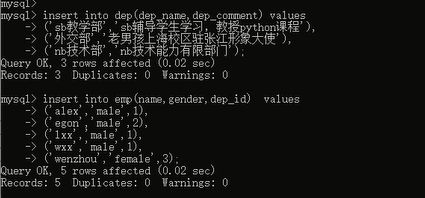
然后查看一下数据:
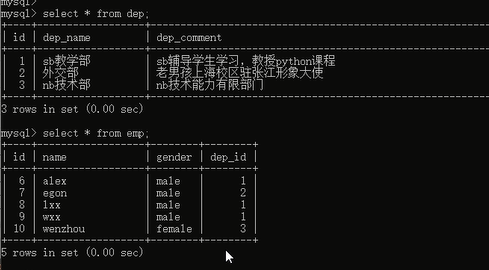
数据没问题了,但是你有没有发现一个问题,就是员工表的id从6开始的,因为我们前面插入了5条数据,失败了,虽然失败了,但是id自动增长了。
所以有引出一个问题,如果想让id从头开始,我们可以把这些数据删掉,用delete的删除是没用的,需要用truncate来删除,这是清空表的意思。
看一下delete:
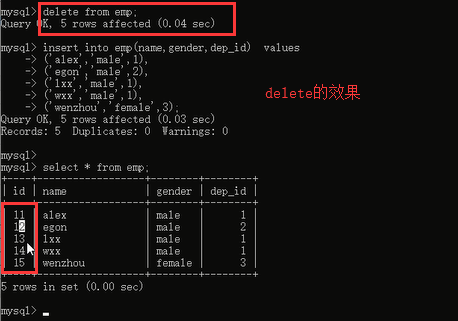
delete不是用来清空表的,是用来删除一些你想删除的符合某些条件的数据,一般用在delete from tb1 where id>20;这样的,如果要清空表,让id置零,使用truncate
再看一下truncate:
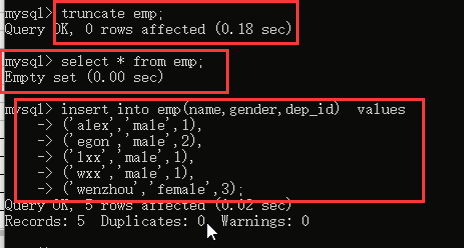
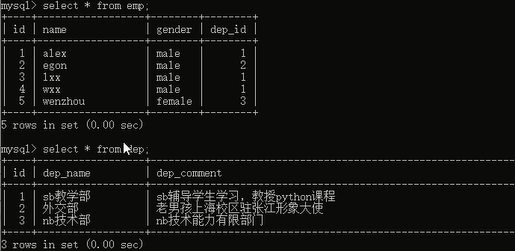
然后查看一下数据看看:
我们来看一下,如果对关联的表进行修改的话会有什么效果,首先我们先修改一下部门表的id字段中的某个数据,将id的值改一下

报错了,那我们改一改员工表里面的外键字段dep_id,改它的值来试试:

还是报错了!我靠,那我试试删除一下试试,解散一个部门,删除他的数据:

报错了!不让你删除,因为你删除之后,员工表里面的之前属于这个部门的记录找不到对应的部门id了,就报错了
那我删除一下员工表里面关于这个要被解散的部门的员工数据,按理说是不是应该没问题啊,来看看效果:
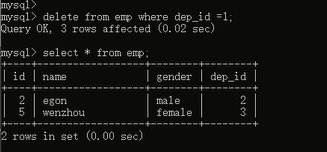
删除成功了,完全没问题啊,那么关于这个部门的所有员工数据都被删除了,也就是说,你这个部门下面没有任何员工了,没有了限制了相当于,所以我们尝试一下看看现在能不能删除部门表里面的这个部门了
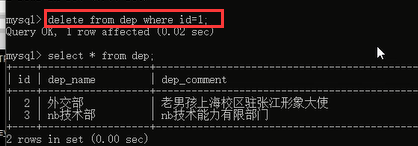
ok~可以删除了
虽然我们修改部门表或者员工表里面的部门id,但是我们可以删除,但是删除这个被关联表部门表的数据的时候由于有关联关系的存在,所以删除的时候也很麻烦,要先将关联数据删除,才能删除被关联的表的数据。
刚才我们删除了教学部这个部门,当我们想解散这个部门的时候,首先想到的是什么,是不是我们的部门表,想直接操作部门表进行删除,对吧,想修改部门的id号,是不是首先想到的也是操作部门表进行修改,把部门的id修改了,但是我们由于关联关系的存在,不得不考虑关联表中的数据,对不对,所以操作就变得很麻烦了,有没有简单的方法呢?我们想做的是不是说,我想删除一个部门,直接删除部门表里面的数据就行了,是不是达到这个效果,删除一个部门的时候,与这个部门关联的所有的员工表的那些数据都跟着删除,或者我更新部门表中一个部门的id号,那么关联的员工表中的关联字段的部门id号跟着自动更新了,
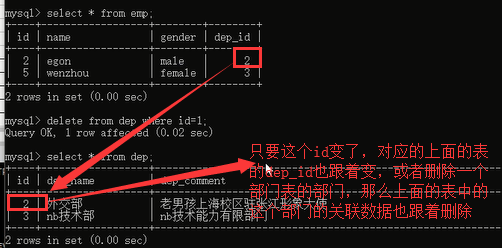
看一下解决办法:
首先我们把之前的两个表删除了,能先删除部门表吗?如果删了部门表,你的员工表是不是找不到对应关系了,你说会不会报错啊,所以先删除员工表:
1.先删除关联表,再删除被关联表,然后我们重新建立两个表,然后建表的时候说一下咱们的解决方案。
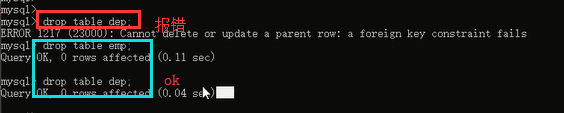
2.重建表,我们现在要解决的问题是:我们要达到一个在做某个表(被关联表)更新或者删除操作的时候,关联表的数据同步的进行更新和删除的效果,所以我们在建表的时候,可以加上两个功能:同步更新和同步删除:看看如何实现:在建立关联关系的时候,加上这两句: on delete cascade和 on update cascade
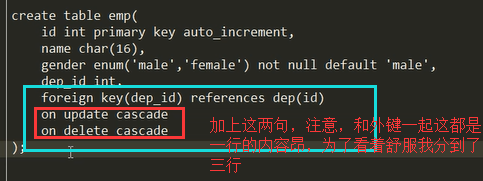
然后把我们之间的表和数据都插入进去:然后再进行更新删除操作:
然后我们再直接删除部门表里面的数据的时候,你看看结果:
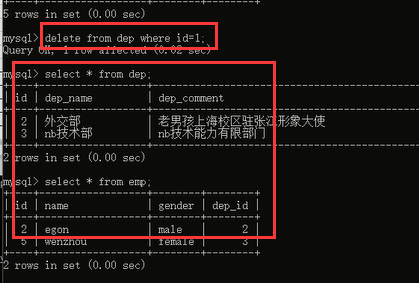
成功了,并且员工表里面关联部门表id的数据也都删除了,是不是达到了我们刚才想要实现的效果呀
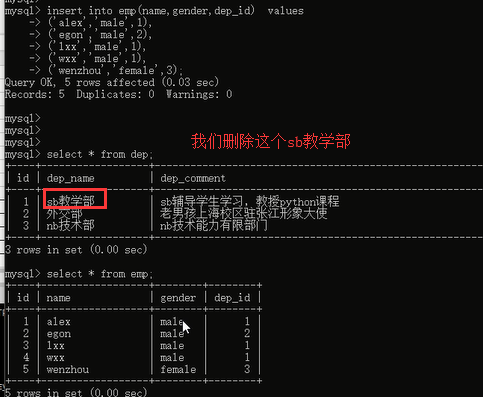
下面我们来看一下更新操作,我们之前说更新一个部门的id号,注意一个问题昂,我更新部门的名称,你说有影响吗?肯定没有啊,因为我员工表并不是关联的部门的名称字段,而是关联的部门的id字段,你改部门名称没关系,我通过你的id照样找到你,但是你如果改了id号,那么我员工表里面的id号和你不匹配了,我就没法找到你,所有当你直接更新部门的id的时候,我就给你报错了,大哥,你想改的是关联字段啊,考虑一下关联表的数据们的感受行不行。我们来看一下加上 on update cascade之后的效果:
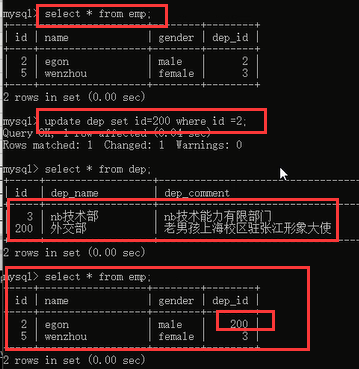
将部门id为2的部门的id改成了200,完全ok,员工表里面之前关联id为2的部门的数据都改成了关联id为200的数据了。说明同步更新也是没问题的。
我们总结一下foreign key的下面几个约束作用:
1、先要建立被关联的表才能建立关联表
2、在插入数据记录的时候,要先想被关联表中插入数据,才能往关联表里面插入数据
3、更新或者删除数据的时候,都需要考虑关联表和被关联表的关系
解决方案:
a.删除表的时候,先删除关联表,再删除被关联表
b.重建表的时候,在加外键关联的时候加上这两句:on delete cascade 和 on update cascade
简单测试
表类型必须是innodb存储引擎,且被关联的字段,即references指定的另外一个表的字段,必须保证唯一
create table department(
id int primary key,
name varchar(20) not null
)engine=innodb;
#dpt_id外键,关联父表(department主键id),同步更新,同步删除
create table employee(
id int primary key,
name varchar(20) not null,
dpt_id int,
constraint fk_name foreign key(dpt_id) #这句话的意思是constraint 是声明我们要建立一个约束啦,fk_name是约束的名称,foreign key是约束的类型,整体的意思是,我要创建一个名为fk_name的外键关联啦,这个constraint就是一个声明的作用,在创建外键的时候不加constraint fk_name也是没问题的。先理解一下就行了,后面我们会细讲的。
references department(id)
on delete cascade
on update cascade
)engine=innodb;
#先往父表department中插入记录
insert into department values
(1,'欧德博爱技术有限事业部'),
(2,'艾利克斯人力资源部'),
(3,'销售部');
#再往子表employee中插入记录
insert into employee values
(1,'chao',1),
(2,'alex1',2),
(3,'alex2',2),
(4,'alex3',2),
(5,'李坦克',3),
(6,'刘飞机',3),
(7,'张火箭',3),
(8,'林子弹',3),
(9,'加特林',3)
;
#删父表department,子表employee中对应的记录跟着删
mysql> delete from department where id=3;
mysql> select * from employee;
+----+-------+--------+
| id | name | dpt_id |
+----+-------+--------+
| 1 | chao | 1 |
| 2 | alex1 | 2 |
| 3 | alex2 | 2 |
| 4 | alex3 | 2 |
+----+-------+--------+
#更新父表department,子表employee中对应的记录跟着改
mysql> update department set id=22222 where id=2;
mysql> select * from employee;
+----+-------+--------+
| id | name | dpt_id |
+----+-------+--------+
| 1 | chao | 1 |
| 3 | alex2 | 22222 |
| 4 | alex3 | 22222 |
| 5 | alex1 | 22222 |
+----+-------+--------+
多对多的关系
我们上面大致提了一下多对多的关系,下面我们通过一个例子来细讲一下,这个例子就用-->书和出版社的关系来看吧:

上面是一对多没问题,我们再来看看书和作者的关系:

一本书可以有多个作者,一个作者可不可以写多本书,两者之间是不是站在谁的角度去看都是一个一对多的关系啊,那这就是多对多的关系,那我们创建表的时候,需要将两个表都加一个foreign key的字段,但是你添加字段的时候,你想想,能直接给两个表都这一个foreign key字段吗,两个谁先创建,谁后创建,是不是都不行啊,两个表的创建是不是都依赖着另外一张表啊,所以我们之前的加外键字段的方式对于这种多对多的关系是不是就不好用啦,怎么办,我们需要通过第三张表来缓和一下两者的关系,通过第三张表来创建双方的关系
我们先创建书表和作者表,然后创建第三张表,第三张表就需要有一个字段外键关联书表,还有一个字段外键关联作者表

然后我们如果想查一下alex出了哪些书,你可以怎么查,想一下,首先在author作者表里面找一个alex的id是多少,alex的id为2,然后找一个第三张表里面author_id为2的数据中book的id,然后拿着这些book的id去book表里面找对应的book名称,你就能够知道alex这个作者出了哪几本书了,对不对,这就是一个多表查询的一个思路
来我们创建一下试试看(学了foreign key,这个东西是不是很简单啊,两个foreign key嘛~~)
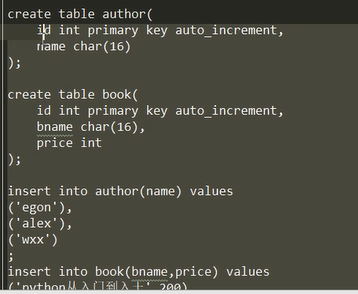
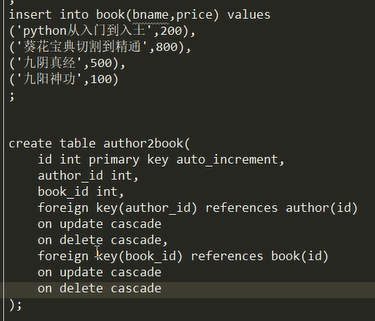
建立前两张表,插入数据,建立第三张表
然后给第三张表插入一些数据:
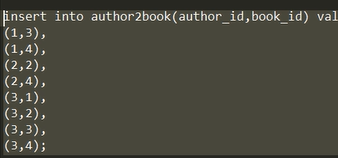
查看一下数据:
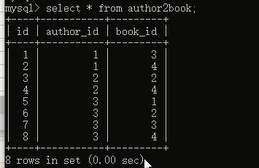
数据就创建好了,多对多就讲完了
一对一关系
我们来以咱们学校的学生来举例:
最开始你只是一个客户,可能还处于咨询考虑的阶段,还没有转化为学生,也有的客户已经转换为学生了,说白了就是你交钱了,哈哈
那我们来建两个表:客户表和学生表
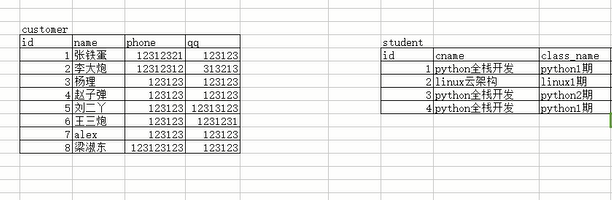
客户表里面存着客户的信息,学生表里面存着客户转换为学生之后的学生信息,那么这两个表是什么关系呢?你想一下,学生是不是从客户转换过来的,那么一个学生能对应多个用户的信息吗?当然是不能的,那么一个客户能对应多个学生的信息吗,当然也是不能的,那么他们两个就是一对一的关系,那这个关系该怎么建立呢?我们知道通过外键可以建立关系,如果在客户表里面加外键关联学生表的话,那说明你的学生表必须先被创建出来,这样肯定是不对的,因为你的客户表先有的,才能转换为学生,那如果在学生表加外键关联客户表的话,貌似是可以的,不过一个学生只对应一个客户,那么这个关系怎么加呢,外键我们知道是一对多的,那怎么搞?我们可以把这个关联字段设置成唯一的,不就可以了吗,我既和你有关联,我还不能重复,那就做到了我和你一对一的关联关系。
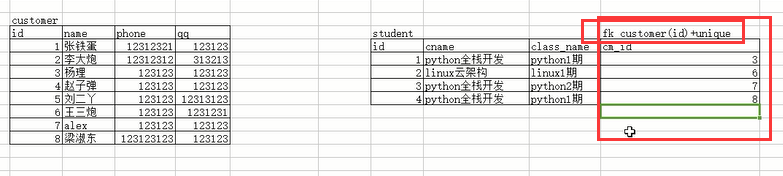
表关系总结
分析步骤:
#1、先站在左表的角度去找
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
#2、再站在右表的角度去找
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
#3、总结:
#多对一:
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
#多对多
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
#一对一:
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可
外键约束的模式
外键约束有三种约束模式(都是针对父表的约束):
模式一: district 严格约束(默认的 ),父表不能删除或者更新已经被子表数据引用的记录
模式二:cascade 级联模式:父表的操作,对应的子表关联的数据也跟着操作 。
模式三:set null:置空模式,父表操作之后,子表对应的数据(外键字段)也跟着被置空。
通常的一个合理的约束模式是:删除的时候子表置空;更新的时候子表级联。
指定模式的语法:foreign key(外键字段)references 父表(主键字段)on delete 模式 on update 模式;
注意:删除置空的前提条件是 外键字段允许为空,不然外键会创建失败。
外键虽然很强大,能够进行各种约束,但是外键的约束降低了数据的可控性和可拓展性。通常在实际开发时,很少使用外键来约束。
多表操作
在企业中其实很多时候都不会加上foreign key外键约束的,因为操作起来有很多限制的地方,我们在上面的操作中已经看到了,所以企业中有两种方式,一种加外键,一种不加外键,但是不管加不加外键,我们下面要进行的多表操作,都是可以的。下面的多表操作讲解,我们以无外键,也就是不加foreign key的方式来进行多表之间的数据操作。
首先说一下,我们写项目一般都会建一个数据库,那数据库里面是不是存了好多张表啊,不可能把所有的数据都放到一张表里面,肯定要分表来存数据,这样节省空间,数据的组织结构更清晰,解耦和程度更高,但是这些表本质上是不是还是一个整体啊,是一个项目所有的数据,那既然分表存了,就要涉及到多个表连接查询了,比如说员工信息一张表,部门信息一张表,那如果我想让你帮我查一下技术部门有哪些员工的姓名,你怎么办,单独找员工表能实现吗,不能,单独找部门表也无法实现,因为部门表里面没有员工的信息,对不对,所以就涉及到部门表和员工表来关联到一起进行查询了,好,那我们来建立这么两张表:
表和数据准备
#建表
#部门表
create table department(
id int,
name varchar(20)
);
#员工表,之前我们学过foreign key,强行加上约束关联,但是我下面这个表并没有直接加foreign key,这两个表我只是让它们在逻辑意义上有关系,并没有加foreign key来强制两表建立关系,为什么要这样搞,是有些效果要给大家演示一下
#所以,这两个表是不是先建立哪个表都行啊,如果有foreign key的话,是不是就需要注意表建立的顺序了。那我们来建表。
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#给两个表插入一些数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'); #注意这一条数据,在下面的员工表里面没有对应这个部门的数据
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204) #注意这条数据的dep_id字段的值,这个204,在上面的部门表里面也没有对应的部门id。所以两者都含有一条双方没有涉及到的数据,这都是为了演示一下效果设计的昂
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
笛卡尔积
当我们直接select多张表的时候,就会出现一个笛卡尔积现象,看示例
mysql> select * from department,employee; #表用逗号分隔,看我查询时表的顺序,先department后employee,所以你看结果表的这些字段,是不是就是我们两个表字段并且哪个表在前面,哪个表的字段就在前面
+------+--------------+----+------------+--------+------+--------+
| id | name | id | name | sex | age | dep_id |
+------+--------------+----+------------+--------+------+--------+
| 200 | 技术 | 1 | egon | male | 18 | 200 |
| 201 | 人力资源 | 1 | egon | male | 18 | 200 |
| 202 | 销售 | 1 | egon | male | 18 | 200 |
| 203 | 运营 | 1 | egon | male | 18 | 200 |
| 200 | 技术 | 2 | alex | female | 48 | 201 |
| 201 | 人力资源 | 2 | alex | female | 48 | 201 |
| 202 | 销售 | 2 | alex | female | 48 | 201 |
| 203 | 运营 | 2 | alex | female | 48 | 201 |
| 200 | 技术 | 3 | wupeiqi | male | 38 | 201 |
| 201 | 人力资源 | 3 | wupeiqi | male | 38 | 201 |
| 202 | 销售 | 3 | wupeiqi | male | 38 | 201 |
| 203 | 运营 | 3 | wupeiqi | male | 38 | 201 |
| 200 | 技术 | 4 | yuanhao | female | 28 | 202 |
| 201 | 人力资源 | 4 | yuanhao | female | 28 | 202 |
| 202 | 销售 | 4 | yuanhao | female | 28 | 202 |
| 203 | 运营 | 4 | yuanhao | female | 28 | 202 |
| 200 | 技术 | 5 | liwenzhou | male | 18 | 200 |
| 201 | 人力资源 | 5 | liwenzhou | male | 18 | 200 |
| 202 | 销售 | 5 | liwenzhou | male | 18 | 200 |
| 203 | 运营 | 5 | liwenzhou | male | 18 | 200 |
| 200 | 技术 | 6 | jingliyang | female | 18 | 204 |
| 201 | 人力资源 | 6 | jingliyang | female | 18 | 204 |
| 202 | 销售 | 6 | jingliyang | female | 18 | 204 |
| 203 | 运营 | 6 | jingliyang | female | 18 | 204 |
+------+--------------+----+------------+--------+------+--------+
24 rows in set (0.12 sec)
我们让employee表在前面看看结果,注意看结果表的字段
mysql> select * from employee,department;
+----+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 1 | egon | male | 18 | 200 | 201 | 人力资源 |
| 1 | egon | male | 18 | 200 | 202 | 销售 |
| 1 | egon | male | 18 | 200 | 203 | 运营 |
| 2 | alex | female | 48 | 201 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 2 | alex | female | 48 | 201 | 202 | 销售 |
| 2 | alex | female | 48 | 201 | 203 | 运营 |
| 3 | wupeiqi | male | 38 | 201 | 200 | 技术 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 202 | 销售 |
| 3 | wupeiqi | male | 38 | 201 | 203 | 运营 |
| 4 | yuanhao | female | 28 | 202 | 200 | 技术 |
| 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 4 | yuanhao | female | 28 | 202 | 203 | 运营 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 |
| 5 | liwenzhou | male | 18 | 200 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 203 | 运营 |
| 6 | jingliyang | female | 18 | 204 | 200 | 技术 |
| 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 |
| 6 | jingliyang | female | 18 | 204 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | 203 | 运营 |
+----+------------+--------+------+--------+------+--------------+
24 rows in set (0.00 sec)
关于笛卡儿积:我们看一下上面的这些数据,有什么发现,首先看到这些字段都显示出来了,并且数据变得很多,我们来看一下,这么多条数据都是怎么来的,为什么会出现这么条数据,笛卡儿积这是一个数据名词,你可以去研究研究~~
因为我们要进行连表查询,那么mysql并不知道你想要如何连接两个表的关系进行查询,那么mysql会将你两个表数据的所有组合关系都给你拼接成一条数据来显示,这样你就可以想查哪个关联关系的数据就查哪个了,如果还是不太理解看一下下面的图:

咱们为了更好的管理数据,为了节省空间,为了数据组织结构更清晰,将数据拆分到了不同表里面,但是本质上是不是还是一份数据,一份重复内容很多的很大的数据,所以我们即便是分表了,但是咱们是不是还需要找到一个方案把两个本来分开的表能够合并到一起来进行查询,那你是不是就可以根据部门找员工,根据员工找部门了,对不对,但是我们合并两个表的时候,如何合并,根据什么来合并,通过笛卡儿积这种合并有没有浪费,我们其实想做的是不是说我们的员工表中dep_id这个字段中的数据和部门表里面的id能够对应上就可以了,因为我们知道我们设计表的时候,是通过这两个字段来给两个表建立关系的,对不对,看下图:

我们的目标就是将两个分散出去的表,按照两者之间有关系的字段,能对应上的字段,把两者合并成一张表,这就是多表查询的一个本质。那么笛卡儿积干了什么事儿,就是简单粗暴的将两个表的数据全部对应了一遍,用处就是什么呢,它肯定就能保证有一条是对应准的,你需要做的事情就是在笛卡儿积的基础上只过滤出我们需要的那些数据就行了,笛卡儿积不是咱们最终要得到的结果,只是给你提供了一个基础,它不管对应的对不对,全部给你对应一遍,然后你自己去筛选就可以了,然后基于笛卡儿积我们来找一下对应的数据,看看能不能找到:
#我们要找的数据就是员工表里面dep_id字段的值和部门表里面id字段的值能对应上的那些数据啊,所以你看下面的写法:
mysql> select * from employee,department where employee.dep_id=department.id;
+----+-----------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+-----------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
+----+-----------+--------+------+--------+------+--------------+
5 rows in set (0.14 sec)
拿到了我们想要的结果。
但是你看,我们左表employee表中的dep_id为204的那个数据没有了,右表department表的id为203的数据没有了,因为我们现在要的就是两表能对应上的数据一起查出来,那个204和203双方对应不上。
#再看一个需求,我要查出技术部的员工的名字
mysql> select name from employee,department where employee.dep_id=department.id and department.name='技术';
ERROR 1052 (23000): Column 'name' in field list is ambiguous
#上面直接就报错了,因为select后面直接写的name,在两个表合并起来的表中,是有两个name字段的,直接写name是不行的,要加上表名,再看:
mysql> select employee.name from employee,department where employee.dep_id=department.id and department.name='技术';
+-----------+
| name |
+-----------+
| egon |
| liwenzhou |
+-----------+
2 rows in set (0.09 sec)
结果就没问题了
但是你看上面的代码有没有什么不太好的地方,虽然我们能够完成我们的事情,但是代码可读性不好,所以以后不要这么写,但是看图:

所以mysql为我们提供了一些专门做连表操作的方法,这些方法语义更加的明确,你一看就知道那些代码是连表的,那些代码是查询的,其实上面的连表也是个查询操作,但是我们为了区分明确,连表专门用连表的方法,查询就专门用查询的方法。那这些专门的方法都是什么呢,看后面的内容。
连表查询
内连接 inner join
看题:请查出技术部的员工的名字
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
+----+------------+--------------+
外连接之左连接
优先显示左表全部记录
看示例:
#以左表为准,即找出所有员工信息,当然包括没有部门的员工
#本质就是:在内连接的基础上增加左边有右边没有的结果 #注意语法:
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 6 | jingliyang | NULL | #通过null来补充
+----+------------+--------------+
外链接之右连接
优先显示右表全部记录
看示例
#以右表为准,即找出所有部门信息,包括没有员工的部门
#本质就是:在内连接的基础上增加右边有左边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;
+------+-----------+--------------+
| id | name | depart_name |
+------+-----------+--------------+
| 1 | egon | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 5 | liwenzhou | 技术 |
| NULL | NULL | 运营 |
+------+-----------+--------------+
全外连接:
显示左右两个表全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#查看结果
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
+------+------------+--------+------+--------+------+--------------+
子查询
子查询其实就是将你的一个查询结果用括号括起来,这个结果也是一张表,就可以将它交给另外一个sql语句,作为它的一个查询依据来进行操作。
来,我们简单来个需求:技术部都有哪些员工的姓名,都显示出来: 1、看一下和哪个表有关,然后from找到两个表 2、进行一个连表操作 3、基于连表的结果来一个过滤就可以了
#我们之前的做法是:先连表
mysql> select * from employee inner join department on employee.dep_id = department.id;
+----+-----------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+-----------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
+----+-----------+--------+------+--------+------+--------------+
5 rows in set (0.10 sec)
#然后根据连表的结果进行where过滤,将select*改为select employee.name
mysql> select employee.name from employee inner join department on employee.dep_id = department.id where department.name='技术';
+-----------+
| name |
+-----------+
| egon |
| liwenzhou |
+-----------+
2 rows in set (0.09 sec)
然后看一下子查询这种方式的写法:它的做法就是解决完一个问题,再解决下一个问题,针对我们上面的需求,你想,我们的需求是不是说找技术部门下面有哪些员工对不对,如果你直接找员工表,你能确定哪个dep_id的数值表示的是技术部门吗,不能,所以咱们是不是应该先确定一个技术部门对应的id号是多少,然后根据部门的id号,再去员工表里面查询一下dep_id为技术部门对应的部门表的那个id号的所有的员工表里面的记录:好,那我们看一下下面的操作:
#首先从部门表里面找到技术部门对应的id
mysql> select id from department where name='技术';
+------+
| id |
+------+
| 200 |
+------+
1 row in set (0.00 sec)
#那我们把上面的查询结果用括号括起来,它就表示一条id=200的数据,然后我们通过员工表来查询dep_id=这条数据作为条件来查询员工的name
mysql> select name from employee where dep_id = (select id from department where name='技术');
+-----------+
| name |
+-----------+
| egon |
| liwenzhou |
+-----------+
2 rows in set (0.00 sec)
上面这些就是子查询的一个思路,解决一个问题,再解决另外一个问题,你子查询里面可不可以是多个表的查询结果,当然可以,然后再通过这个结果作为依据来进行过滤,然后我们学一下子查询里面其他的内容,往下学。
子查询的一些其他用法
#1:子查询是将一个查询语句嵌套在另一个查询语句中。
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等
小练习
1、带IN关键字的子查询
#查询员工平均年龄在25岁以上的部门名,可以用连表,也可以用子查询,我们用子查询来搞一下
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#连表来搞一下上面这个需求
select department.name from department inner join employee on department.id=employee.dep_id
group by department.name
having avg(age)>25;
总结:子查询的思路和解决问题一样,先解决一个然后拿着这个的结果再去解决另外一个问题,连表的思路是先将两个表关联在一起,然后在进行group by啊过滤啊等等操作,两者的思路是不一样的
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from employee);
2、带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec)
#查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
3、带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询。还可以写not exists,和exists的效果就是反的
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)
mysqldump数据库备份
我们在工作中可能需要将数据库进行备份,那么就可以用到我们的mysqldump指令。
语法
mysqldump -uroot -p -B crm2> xxxxxx.sql
看示例
数据库和数据准备
1.首先我们先创建一个名为crm2的库
mysql> create database crm2;
mysql> show create database crm2;
2.切换到crm2库下
mysql> use crm2;
3.创建两张表,student表和class表
mysql> create table tb1(id int primary key,name char(8) not null,age int,class_id int not null);
Query OK, 0 rows affected (0.63 sec)
mysql> create table class(id int primary key,cname char(20) not null);
Query OK, 0 rows affected (0.34 sec)
4.给两张表插入一些数据
mysql> insert into class values(1,'一班'),(2,'二班');
mysql> insert into student values(1,'Jaden',18,1),(2,'太白',45,1),(3,'彦涛',30,2);
5.查看一下两个表的数据
mysql> select * from student;
+----+--------+------+----------+
| id | name | age | class_id |
+----+--------+------+----------+
| 1 | Jaden | 18 | 1 |
| 2 | 太白 | 45 | 1 |
| 3 | 彦涛 | 30 | 2 |
+----+--------+------+----------+
3 rows in set (0.00 sec)
mysql> select * from class;
+----+--------+
| id | cname |
+----+--------+
| 1 | 一班 |
| 2 | 二班 |
+----+--------+
2 rows in set (0.00 sec)
1.mysqldump -uroot -p -B crm2> 备份的sql文件存放路径
例如:mysqldump -uroot -p -B crm2> f:数据库备份练习crm2.sql
备份完成之后,我们删除一下数据库crm2,然后再执行下面的数据库恢复指令。
2.在cmd窗口下执行:mysql -uroot -p < f:数据库备份练习crm2.sql
3.查看一下是否恢复了:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| crm2 |
| d1 |
| mysql |
| performance_schema |
| test |
+--------------------+
mysql> use crm2;
Database changed
mysql> show tables;
+----------------+
| Tables_in_crm2 |
+----------------+
| class |
| student |
+----------------+
2 rows in set (0.00 sec)
mysql> select * from class;
+----+--------+
| id | cname |
+----+--------+
| 1 | 一班 |
| 2 | 二班 |
+----+--------+
2 rows in set (0.00 sec)
mysql> desc student;
+----------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | char(8) | NO | | NULL | |
| age | int(11) | YES | | NULL | |
| class_id | int(11) | NO | | NULL | |
+----------+---------+------+-----+---------+-------+
4 rows in set (0.02 sec)
数据恢复了,上面我们就完成了一个简单数据库备份和恢复的过程。
# 备份表 :homwork库中的所有表和数据
# mysqldump -uroot -p123 homework > D:s23day42a.sql
# 备份单表
# mysqldump -uroot -p123 homework course > D:s23day42a.sql
# 备份库 :
# mysqldump -uroot -p123 --databases homework > D:s23day42db.sql
# 恢复数据:
# 进入mysql 切换到要恢复数据的库下
# sourse D:s23day42a.sql
mysqldump
语法:mysqldump -u用户名 -p -B(又不用自己创库) -d 库名>路径(g:avav.sql)
备份:mysqldump -uroot -p -B -d 库名>(g:avav.sql)
语法mysql -uroot -p < (g:avav.sql)
还原:mysql -uroot -p < 路径(g:avav.sql)
锁事务
本节内容,我们准备学一下MySQL数据库中的锁和事务,以及一些sql题的练习。
学习过并发编程之后,我们知道任务是可以并发执行的,那么如果我们并发操作共享数据的时候,会造成数据不安全的问题,怎么解决呢?加锁,而MySQL数据库已经给我们提供了锁,下面我们来学习一下。
数据库锁定机制简单来说,就是数据库为了保证数据的一致性,而使各种共享资源在被并发访问变得有序所设计的一种规则。对于任何一种数据库来说都需要有相应的锁定机制,所以MySQL自然也不能例外。MySQL数据库由于其自身架构的特点,存在多种数据存储引擎,每种存储引擎所针对的应用场景特点都不太一样,为了满足各自特定应用场景的需求,每种存储引擎的锁定机制都是为各自所面对的特定场景而优化设计,所以各存储引擎的锁定机制也有较大区别。MySQL各存储引擎使用了三种类型(级别)的锁定机制:表级锁定,行级锁定。
锁
我们知道mysql中支持很多个存储引擎,在不同的存储引擎下所能支持的锁是不同的,我们通过MyISAM和InnoDB来进行一下对比。
表级锁定(table-level)
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,致使并大度大打折扣。
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
行级锁定
行级锁定最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力而提高一些需要高并发应用系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
乐观锁和悲观锁
乐观锁,顾名思义,对加锁持有一种乐观的态度,即先进行业务操作,不到最后一步不进行加锁,"乐观"的认为加锁一定会成功的,在最后一步更新数据的时候在进行加锁,乐观锁的实现方式一般为每一条数据加一个版本号,具体流程是这样的:
1)、创建一张表时添加一个version字段,表示是版本号,如下:
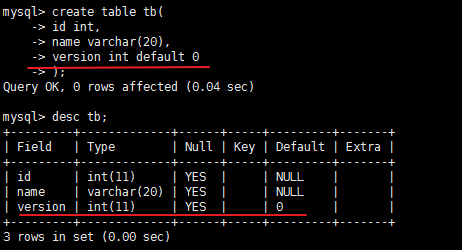
2)、修改数据的时候首先把这条数据的版本号查出来,update时判断这个版本号是否和数据库里的一致,如果一致则表明这条数据没有被其他用户修改,若不一致则表明这条数据在操作期间被其他客户修改过,此时需要在代码中抛异常或者回滚等。伪代码如下:
update tb set name='yyy' and version=version+1 where id=1 and version=version;
1. SELECT name AS old_name, version AS old_version FROM tb where ...;
2. 根据获取的数据进行业务操作,得到new_dname和new_version
3. UPDATE SET name = new_name, version = new_version WHERE version = old_version
if (updated row > 0) {
// 乐观锁获取成功,操作完成
} else {
// 乐观锁获取失败,回滚并重试
}
update其实在不在事物中都无所谓,在内部是这样的:update是单线程的,及如果一个线程对一条数据进行 update操作,会获得锁,其他线程如果要对同一条数据操作会阻塞,直到这个线程update成功后释放锁。
悲观锁,正如其名字一样,悲观锁对数据加锁持有一种悲观的态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
首先我们需要set autocommit=0,即不允许自动提交
用法:select * from tablename where id = 1 for update;
申请前提:没有线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞。
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
假设有一张商品表 shop,它包含 id,商品名称,库存量三个字段,表结构如下:
插入如下数据:
并发导致数据一致性的问题:
如果有A、B两个用户需要购买id=1的商品,AB都查询商品数量是1000,A购买后修改商品的数量为999,B购买后修改数量为999。
用乐观锁的解决方案:
每次获取商品时,不对该商品加锁。在更新数据的时候需要比较程序中的库存量与数据库中的库存量是否相等,如果相等则进行更新,反之程序重新获取库存量,再次进行比较,直到两个库存量的数值相等才进行数据更新。伪代码如下:
//不加锁
select id,name,stock where id=1;
//业务处理
begin;
update shop set stock=stock-1 where id=1 and stock=stock;
commit;
悲观锁方案:
每次获取商品时,对该商品加排他锁。也就是在用户A获取获取 id=1 的商品信息时对该行记录加锁,期间其他用户阻塞等待访问该记录。悲观锁适合写入频繁的场景。代码如下:
begin;
select id,name,stock as old_stock from shop where id=1 for update;
update shop set stock=stock-1 where id=1 and stock=old_stock;
commit;
我们可以看到,首先通过begin开启一个事物,在获得shop信息和修改数据的整个过程中都对数据加锁,保证了数据的一致性。
事务
事务介绍
简单地说,事务就是指逻辑上的一组SQL语句操作,组成这组操作的各个SQL语句,执行时要么全成功要么全失败。
例如:你给我转账5块钱,流程如下
a.从你银行卡取出5块钱,剩余计算money-5
b.把上面5块钱打入我的账户上,我收到5块,剩余计算money+5.
上述转账的过程,对应的sql语句为:
update 你_account set money=money-5 where name='你';
update 我_account set money=money+5 where name='我';
上述的两条SQL操作,在事务中的操作就是要么都执行,要么都不执行,不然钱就对不上了。
这就是事务的原子性(Atomicity)。
事务的四大特性
1.原子性(Atomicity)
事务是一个不可分割的单位,事务中的所有SQL等操作要么都发生,要么都不发生。
2.一致性(Consistency)
事务发生前和发生后,数据的完整性必须保持一致。
3.隔离性(Isolation)
当并发访问数据库时,一个正在执行的事务在执行完毕前,对于其他的会话是不可见的,多个并发事务之间的数据是相互隔离的。也就是其他人的操作在这个事务的执行过程中是看不到这个事务的执行结果的,也就是他们拿到的是这个事务执行之前的内容,等这个事务执行完才能拿到新的数据。
4.持久性(Durability)
一个事务一旦被提交,它对数据库中的数据改变就是永久性的。如果出了错误,事务也不允撤销,只能通过'补偿性事务'。
事务
原子性
其对数据的修改,要么全部成功,要么全部都不成功。
一致性
事务开始到结束的时间段内,数据都必须保持一致状态。
隔离性
数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的"独立"环境执行。
持久性
事务完成后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
我们可以在mysql事务处理过程中定义保存点(SAVEPOINT),然后回滚到指定的保存点前的状态。
定义保存点,以及回滚到指定保存点前状态的语法如下。
1.定义保存点---savepoint 保存点名;
2.回滚到指定保存点---rollback to savepoint 保存点名:
MySQL中事务操作指令
看语法:
BEGIN或START TRANSACTION;显式地开启一个事务;
COMMIT; 也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改成为永久性的;
ROLLBACK; 有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改;
事务简单实例
create table user(
id int primary key auto_increment,
name char(32),
balance int
);
insert into user(name,balance)
values
('wsb',1000),
('chao',1000),
('ysb',1000);
#原子操作
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='chao'; #中介拿走10元
update user set balance=1090 where name='ysb'; #卖家拿到90元
commit; #只要不进行commit操作,就没有保存下来,没有刷到硬盘上
#出现异常,回滚到初始状态
start transaction;
update user set balance=900 where name='wsb'; #买支付100元
update user set balance=1010 where name='chao'; #中介拿走10元
uppdate user set balance=1090 where name='ysb'; #卖家拿到90元,出现异常没有拿到
rollback; #如果上面三个sql语句出现了异常,就直接rollback,数据就直接回到原来的状态了。但是执行了commit之后,rollback这个操作就没法回滚了
commit;
实列 开启一个事务
开启事务,给数据加锁
# begin;#开始
# select id from t1 where name = 'alex' for update;
# update t1 set id = 2 where name = 'alex';
# commit;#结束
实列 开启回滚
mysql> begin; -- 或者 start transaction;#开启事务
mysql> INSERT INTO user VALUES ('3','one','0','');#向表user中插入2条数据
mysql> INSERT INTO user VALUES ('4,'two','0','');#向表user中插入2条数据
mysql> select * from user;#查询user表
mysql> savepoint test;#指定保存点,保存点名为test
mysql> INSERT INTO user VALUES ('5','three','0','');#向表user中插入第3条数据
mysql> select * from user;#查表
mysql> ROLLBACK TO SAVEPOINT test;#回滚到保存点test
mysql> select * from user;#查表
索引
为什么使用索引
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等,下面内容看不懂的同学也没关系,能明白这个目录的道理就行了。 那么你想,书的目录占不占页数,这个页是不是也要存到硬盘里面,也占用硬盘空间。你再想,你在没有数据的情况下先建索引或者说目录快,还是已经存在好多的数据了,然后再去建索引,哪个快,肯定是没有数据的时候快,因为如果已经有了很多数据了,你再去根据这些数据建索引,是不是要将数据全部遍历一遍,然后根据数据建立索引。你再想,索引建立好之后再添加数据快,还是没有索引的时候添加数据快,索引是用来干什么的,是用来加速查询的,那对你写入数据会有什么影响,肯定是慢一些了,因为你但凡加入一些新的数据,都需要把索引或者说书的目录重新做一个,所以索引虽然会加快查询,但是会降低写入的效率。
索引的影响
1、在表中有大量数据的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段......这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
前面提到了访问磁盘,那么这里先简单介绍一下磁盘IO和预读,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转/min,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms,也就是半圈的时间(这里有两个时间:平均寻道时间,受限于目前的物理水平,大概是5ms的时间,找到磁道了,还需要找到你数据存在的那个点,寻点时间,这寻点时间的一个平均值就是半圈的时间,这个半圈时间叫做平均延迟时间,那么平均延迟时间加上平均寻道时间就是你找到一个数据所消耗的平均时间,大概9ms,其实机械硬盘慢主要是慢在这两个时间上了,当找到数据然后把数据拷贝到内存的时间是非常短暂的,和光速差不多了);传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS(Million Instructions Per Second)的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的消耗的时间段下cpu可以执行约450万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难,所以我们要想办法降低IO次数。
索引原理
前面讲了索引的基本原理,数据库的复杂性,又讲了操作系统的相关知识,目的就是让大家了解,现在我们来看看索引怎么做到减少IO,加速查询的。任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生,看下图:

如上图,是一颗b+树,最上层是树根,中间的是树枝,最下面是叶子节点,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块或者叫做一个block块,这是操作系统一次IO往内存中读的内容,一个块对应四个扇区,可以看到每个磁盘块包含几个数据项(深蓝色所示,一个磁盘块里面包含多少数据,一个深蓝色的块表示一个数据,其实不是数据,后面有解释)和指针(黄色所示,看最上面一个,p1表示比上面深蓝色的那个17小的数据的位置在哪,看它指针指向的左边那个块,里面的数据都比17小,p2指向的是比17大比35小的磁盘块),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。除了叶子节点,其他的树根啊树枝啊保存的就是数据的索引,他们是为你建立这种数据之间的关系而存在的。
索引字段要尽量的小:通过上面的分析,我们知道IO次数取决于b+数的高度h或者说层级,这个高度或者层级就是你每次查询数据的IO次数,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
# innodb索引
# 聚集索引 只有一个主键
# 辅助索引 除了主键之外所有的索引都是辅助索引
# 回表: 只查询一个索引并不能解决查询中的问题,还需要到具体的表中去获取正行数据
# myisam索引
# 辅助索引 除了主键之外所有的索引都是辅助索引
索引的影响
1、在表中有大量数据的前提下,创建索引速度会很慢
2、在索引创建完毕后,对表的查询性能会发幅度提升,但是写性能会降低
# 创建了索引之后的效率大幅度提高
# 文件所占的硬盘资源也大幅度提高
索引的数据结构
1. 平衡树 b树
树状图是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
特点:每个结点有零个或多个子结点;没有父结点的结点称为根结点;每一个非根结点有且只有一个父结点;除了根结点外,每个子结点可以分为多个不相交的子树
2. b+树
B+树是通过二叉查找树,再由平衡二叉树,B树演化而来
特性:
- 数据只存储在叶子节点
- 在叶子节点之间加入了双向地址连接,更方便的在子节点之间进行数据的读取
- 最左匹配特性
- 索引字段越小查询速度越快
- B+树的高度一般都在2~4层
- B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),
- 其他的树根啊树枝啊保存的就是数据的索引
数据库中的
聚集索引与辅助索引相同的是:不管是聚集索引还是辅助索引,其内部都是B+树的形式,即高度是平衡的,叶子结点存放着所有的数据。
聚集索引与辅助索引不同的是:叶子结点存放的是否是一整行的信息
叶子结点存放的是索引值和主键**
回表: 只查询一个索引并不能解决查询中的问题,还需要到具体的表中去获取整行数据
索引字段要尽量的小
.索引的最左匹配特性
MySQL的常用索引
索引的种类
主键索引PRIMARY:又称为聚集索引,每张表有且只能有一个,主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
普通索引INDEX:加速查找,可以有多个
唯一索引:主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
联合索引:多个字段联合起来作为索引
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
使用InnoDB存储引擎的时候,每建一个表,就需要给一个主键,是因为这个主键是InnoDB存储引擎的.idb文件来组织存储数据的依据或者说方式,也就是说InnoDB存储引擎在存储数据的时候默认就按照索引的那种树形结构来帮你存。这种索引,我们就称为聚集索引,也就是在聚集数据组织数据的时候,就用这种索引。InnoDB这么做就是为了加速查询效率,因为你经常会遇到基于主键来查询数据的情况,并且通常我们把id字段作为主键,第一点是因为id占用的数据空间不大,第二点是你经常会用到id来查数据。如果你的表有两个字段,一个id一个name,id为主键,当你查询的时候如果where后面的条件是name=多少多少,那么你就没有用到主键给你带来的加速查询的效果(需要主键之外的辅助索引),如果你用where id=多少多少,就会按照我们刚才上面说的哪种树形结构来给你找寻数据了(当然不仅仅有这种树形结构的数据结构类型),能够快速的帮你定位到数据块。这种聚集索引的特点是它会以id字段作为依据,去建立树形结构,但是叶子节点存的是你表中的一条完整记录,一条完整的数据。
聚集索引
聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
聚集索引的好处之二:范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
# priamry key 的创建自带索引效果 非空 + 唯一 + 聚集索引
自己不创建 系统默认创建
#如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。
#如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。
好处
聚集索引的好处之一:它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
聚集索引的好处之二:范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
- 叶子结点存放的是一整行的信息
- 由于实际的数据也是聚集索引的一部分,并且数据只能按照一棵B+树进行排序,所以每张表只能有一个聚集索引就是主键,(1、如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引;2、如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引)
聚集索引的优点:
- 它对主键的排序查找和范围查找速度非常快,叶子节点的数据就是用户所要查询的数据。如用户需要查找一张表,查询最后的10位用户信息,由于B+树索引是双向链表,所以用户可以快速找到最后一个数据页,并取出10条记录
- 范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可
辅助索引
表中除了聚集索引外其他索引都是辅助索引(Secondary Index,也称为非聚集索引)(unique key啊、index key啊),与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全部数据。
叶子节点存放的是对应的那条数据的主键字段的值,除了包含键值以外,每个叶子节点中的索引行中还包含一个书签(bookmark),其实这个书签你可以理解为是一个{'name字段',name的值,主键id值}的这么一个数据
通过辅助索引的叶子节点不能直接拿到age的值,需要通过辅助索引的叶子节点中保存的主键id的值再去通过聚集索引来找到完整的一条记录,然后从这个记录里面拿出age的值,这种操作有时候也成为回表操作,就是从头再回去查一遍,这种的查询效率也很高,
- 叶子结点存放的是索引值和主键
- 回表: 只查询一个索引并不能解决查询中的问题,还需要到具体的表中去获取整行数据
覆盖索引
设置字典name为辅助索引 查到他为name 就是覆盖索引
简单来说就是是设置什么查到什么
索引的两大类型hash与btree
#我们可以在创建上述索引的时候,为其指定索引类型,分两类
hash类型的索引:查询单条快,范围查询慢
btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
#不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
索引的优缺点
# 优点 : 查找速度快
# 缺点 : 浪费空间,拖慢写的速度
# 不要在程序中创建无用的索引
创建删除索引
#方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[unique | fulltext | spatial ] index | kye
[索引名] (字段名)
);
实列
#方式一
create table t1(
id int,
name char,
age int,
sex enum('male','female'),
unique key uni_id(id),
index ix_name(name) #index没有key
);
#方法二:CREATE在已存在的表上创建索引
sreate [unique | fulltext | spatial ] index 索引名
on 表名 (字段名) ;
实列
create index ix_age on t1(age);
#方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名) ;
实列
alter table t1 add index ix_sex(sex);
#删除索引:DROP INDEX 索引名 ON 表名字;
实列
drop index ix_sex on t1;
另一种方式解释
主键索引:
创建的时候添加:
Create table t1(
Id int primary key,
)
Create table t1(
Id int,
Primary key(id)
)
表创建完了之后添加
Alter table 表名 add primary key(id)
删除主键索引:
Alter table 表名 drop primary key;
唯一索引:
Create table t1(
Id int unique,
)
Create table t1(
Id int,
Unique key uni_name (id)
)
表创建好之后添加唯一索引:
alter table s1 add unique key u_name(id);
删除唯一索引:
Alter table s1 drop index u_name;
普通索引:
创建:
Create table t1(
Id int,
Index index_name(id)
)
表创建好之后添加普通索引:
Alter table s1 add index index_name(id);
Create index index_name on s1(id);
删除普通索引:
Alter table s1 drop index u_name;
DROP INDEX 索引名 ON 表名字;
将上面添加索引的字段变为多个就成了联合索引,例如:
联合主键索引
Create table t1(
Id int,
name char(10),
Primary key(id,name)
)
联合唯一索引
Create table t1(
Id int,
name char(10),
Unique key uni_name (id,name)
)
联合普通索引
Create table t1(
Id int,
name char(10),
Index index_name(id,name)
)
创建表完成之后,再添加联合索引的方式和上面的给单个字段添加索引的方式相同。
测试索引
数据准备
#1. 准备表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,实现批量插入记录,存储过程没什么特别的,将下面的代码到mysql中运行一下就可以了,注意,可能会花费挺长时间,因为数据量比较大,有300万条数据。
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'egon','male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3. 查看存储过程
show create procedure auto_insert1G
#4. 调用存储过程
call auto_insert1();
测试示例
- 在没有索引的前提下测试查询速度。
mysql> select * from s1 where id=333333333;
Empty set (0.33 sec)
在表中已经存在大量数据的前提下,为某个字段段建立索引,建立速度会很慢
或者用alter table s1 add primary key(id);加主键,建索引很慢的。

在索引建立完毕后,以该字段为查询条件时,查询速度提升明显

正确命中索引
并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,我们在添加索引时,必须遵循以下问题
-
范围问题,或者说条件不明确,条件中出现这些符号或关键字:>、>=、<、<=、!= 、between...and...、like

如果你写where id >1 and id <1000000;你会发现,随着你范围的增大,速度会越来越慢,会成倍的体现出来。
-
尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0。
-
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
#1、and与or的逻辑 条件1 and 条件2:所有条件都成立才算成立,但凡要有一个条件不成立则最终结果不成立 条件1 or 条件2:只要有一个条件成立则最终结果就成立 #2、and的工作原理 条件: a = 10 and b = 'xxx' and c > 3 and d =4 索引: 制作联合索引(d,a,b,c) 工作原理: #如果是你找的话,你会怎么找,是不是从左到右一个一个的比较啊,首先你不能确定a这个字段是不是有索引,即便是有索引,也不一定能确保命中索引了(所谓命中索引,就是应用上了索引),mysql不会这么笨的,看下面mysql是怎么找的: 索引的本质原理就是先不断的把查找范围缩小下来,然后再进行处理,对于连续多个and:mysql会按照联合索引,从左到右的顺序找一个区分度高的索引字段(这样便可以快速锁定很小的范围),加速查询,即按照d—>a->b->c的顺序 #3、or的工作原理 条件: a = 10 or b = 'xxx' or c > 3 or d =4 索引: 制作联合索引(d,a,b,c) 工作原理: 只要一个匹配成功就行,所以对于连续多个or:mysql会按照条件的顺序,从左到右依次判断,即a->b->c->d -
索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’)
-
最左匹配特性(针对联合索引的)
最左前缀:顾名思义,就是最左优先,上一个博客中数据库我们创建了UNIQUE KEY
uk_device(device_id,user_id,token)多列索引,相当于创建了(device_id)单列索引,(device_id,user_id)组合索引以及(device_id,user_id,token)组合索引。结论是索引键是(a_b_c)seclect * from table where a=' ';以下情况:
1:a= 可以命中索引,b= 不可以命中索引,c= 不可以命中索引。
2:a=‘’ and b=‘’可以命中,a=‘’ and c=‘’ 可以命中索引。
3:b=’‘and a=’‘可以命中索引, b=‘‘ and c=’‘ 不可以命中索引。
4:c=’‘ and a=’‘ 可以命中 索引,c=’‘ and b=’‘不可命中索引。
如何命中索引
在条件中不能带运算或者函数,必须是"字段 = 值"
4.数据对应的范围小一点
# between and > < >= <= != not in
6.多条件的情况
# and 只要有一个条件列是索引列就可以命中索引
# or 只有所有的条件列都是索引才能命中索引
# 字段 能够尽量的固定长度 就固定长度
不能命中索引条件
# 1.所查询的列不是创建了索引的列
# 2.在条件中带运算或者函数 不能命中,必须是"字段 = 值"
# 3.如果创建索引的列的内容重复率高也不能有效利用索引
# 重复率不超过10%的列比较适合做索引
# 4.数据对应的范围如果太大的话,也不能有效利用索引
# between and > < >= <= != not in
# 5.like如果把%放在最前面也不能命中索引
# 6.多条件的情况
# and 只要有一个条件列是索引列就可以命中索引
# or 只有所有的条件列都是索引才能命中索引
什么是联合索引
什么是联合索引
联合主键 联合唯一
# 7.联合索引
# 在多个条件相连的情况下,使用联合索引的效率要高于使用单字段的索引
# where a=xx and b=xxx;
创建联合索引
# 对a和b都创建索引 - 联合索引
# create index 索引名 on 表名(字段1,字段2)
# create index ind_mix on s1(id,email)
# 1.创建索引的顺序id,email 条件中从哪一个字段开始出现了范围,索引就失效了
# select * from s1 where id=1000000 and email like 'eva10000%' 命中索引
# select count(*) from s1 where id > 2000000 and email = 'eva2000000' 不能命中索引
# 2.联合索引在使用的时候遵循最左前缀原则
# select count(*) from s1 where email = 'eva2000000@oldboy';
# 3.联合索引中只有使用and能生效,使用or失效
# 字段 能够尽量的固定长度 就固定长度
# varchar 尽量往后面放
mysql 神器 explain
# 查看sql语句的执行计划
# explain select * from s1 where id < 1000000;
# 是否命中了索引,命中的索引的类型
关于explain,如果大家有兴趣,可以看看这篇博客,他总结的挺好的:http://www.cnblogs.com/yycc/p/7338894.html
开启慢日志
知道mysql可以开启慢日志
# 慢日志是通过配置文件开启
# 如果数据库在你手里 你自己开
# 如果不在你手里 你也可以要求DBA帮你开
7表联查速度慢怎么办?
# 1.表结构
# 尽量用固定长度的数据类型代替可变长数据类型
# 把固定长度的字段放在前面
# 2.数据的角度上来说
# 如果表中的数据越多 查询效率越慢
# 列多 : 垂直分表
# 行多 : 水平分表
# 3.从sql的角度来说
# 1.尽量把条件写的细致点儿 where条件就多做筛选
# 2.多表尽量连表代替子查询
# 3.创建有效的索引,而规避无效的索引
# 4.配置角度上来说
# 开启慢日志查询 确认具体的有问题的sql
# 5.数据库
# 读写分离
# 解决数据库读的瓶颈
利用pymysql操作数据库
我们要学的pymysql就是用来在python程序中如何操作mysql,本质上就是一个套接字客户端,只不过这个套接字客户端是在python程序中用的,既然是客户端套接字,应该怎么用,是不是要连接服务端,并且和服务端进行通信啊,让我们来学习一下pymysql这个模块
安装
pip3 install pymysql
使用
我们通过一个登陆认证,也就是验证用户名和密码是否在用户表中存在来使用一下pymysql
首先我们创建一个用户表,名为userinfo表,其中有用户名(name)和密码字段(password),然后在表中存放一些数据。
然后在我们的python脚本中写上以下内容,就可以完成我们的登陆认证了
import pymysql
user=input('用户名: ').strip()
pwd=input('密码: ').strip()
#链接,指定ip地址和端口,本机上测试时ip地址可以写localhost或者自己的ip地址或者127.0.0.1,然后你操作数据库的时候的用户名,密码,要指定你操作的是哪个数据库,指定库名,还要指定字符集。不然会出现乱码
conn=pymysql.connect(host='localhost',port=3306,user='root',password='123',database='student',charset='utf8')
cursor=conn.cursor() #这就想到于mysql自带的那个客户端的游标mysql> 在这后面输入指令,回车执行
sql='select * from userinfo where name="%s" and password="%s"' %(user,pwd)
res=cursor.execute(sql) #执行sql语句,返回sql查询成功的记录数目,是个数字,是受sql语句影响到的记录行数
#all_data=cursor.fetchall() #获取返回的所有数据,注意凡是取数据,取过的数据就没有了,结果都是元祖格式的
#many_data=cursor.fetchmany(3) #一下取出3条数据,
#one_data=cursor.fetchone() #按照数据的顺序,一次只拿一个数据,下次再去就从第二个取了,因为第一个被取出去了,取一次就没有了,结果也都是元祖格式的
if res:
print('登录成功')
else:
print('登录失败')
cursor.close() #关闭游标
conn.close() #关闭连接
sql注入
所谓sql注入,就是通过将一些特殊符号写入到我们的sql语句中,使我们的sql语句失去了原有的作用。比如绕开我们的认证机制,在不知道用户名和密码的情况下完成登录。
基于上一节的示例,我们看一下sql注入怎么搞事情的。
以下还是上述示例的代码
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='666',
database='crm',
charset='utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
uname = input('请输入用户名:')
pword = input('请输入密码:')
sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword)
res = cursor.execute(sql) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不
print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1
if res:
print('登陆成功')
else:
print('用户名和密码错误!')
但是我们来看下面的操作,如果将在输入用户名的地方输入一个 chao'空格然后--空格然后加上任意的字符串,就能够登陆成功,也就是只知道用户名的情况下,他就能登陆成功的情况:
uname = input('请输入用户名:')
pword = input('请输入密码:')
sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword)
print(sql)
res = cursor.execute(sql) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不
print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1
if res:
print('登陆成功')
else:
print('用户名和密码错误!')
#运行看结果:居然登陆成功
请输入用户名:chao' -- xxx
请输入密码:
select * from userinfo where username='chao' -- xxx' and password='';
1
登陆成功
我们来分析一下:
此时uname这个变量等于什么,等于chao' -- xxx,然后我们来看我们的sql语句被这个字符串替换之后是个什么样子:
select * from userinfo where username='chao' -- xxx' and password=''; 其中chao后面的这个',在进行字符串替换的时候,我们输入的是chao',这个引号和前面的引号组成了一对,然后后面--在sql语句里面是注释的意思,也就是说--后面的sql语句被注释掉了。也就是说,拿到的sql语句是select * from userinfo where username='chao';然后就去自己的数据库里面去执行了,发现能够找到对应的记录,因为有用户名为chao的记录,然后他就登陆成功了,但是其实他连密码都不知道,只知道个用户名。。。,他完美的跳过了你的认证环节。
然后我们再来看一个例子,直接连用户名和密码都不知道,但是依然能够登陆成功的情况:
请输入用户名:xxx' or 1=1 -- xxxxxx
请输入密码:
select * from userinfo where username='xxx' or 1=1 -- xxxxxx' and password='';
3
登陆成功
我们只输入了一个xxx' 加or 加 1=1 加 -- 加任意字符串
看上面被执行的sql语句你就发现了,or 后面跟了一个永远为真的条件,那么即便是username对不上,但是or后面的条件是成立的,也能够登陆成功。
出现这样的问题,我们怎么解决的?通过pymysql给我们提供的execute方法可以解决,看示例:
之前我们的sql语句是这样写的:
sql = "select * from userinfo where username='%s' and password='%s';"%(uname,pword)
以后再写的时候,sql语句里面的%s左右的引号去掉,并且语句后面的%(uname,pword)这些内容也不要自己写了,按照下面的方式写
sql = "select * from userinfo where username=%s and password=%s;"
难道我们不传值了吗,不是的,我们通过下面的形式,在excute里面写参数:
#cursor.execute(sql,[uname,pword]) ,其实它本质也是帮你进行了字符串的替换,只不过它会将uname和pword里面的特殊字符给过滤掉。
看下面的例子:
uname = input('请输入用户名:') #输入的内容是:chao' -- xxx或者xxx' or 1=1 -- xxxxx
pword = input('请输入密码:')
sql = "select * from userinfo where username=%s and password=%s;"
print(sql)
res = cursor.execute(sql,[uname,pword]) #res我们说是得到的行数,如果这个行数不为零,说明用户输入的用户名和密码存在,如果为0说名存在,你想想对不
print(res) #如果输入的用户名和密码错误,这个结果为0,如果正确,这个结果为1
if res:
print('登陆成功')
else:
print('用户名和密码错误!')
#看结果:
请输入用户名:xxx' or 1=1 -- xxxxx
请输入密码:
select * from userinfo where username=%s and password=%s;
0
用户名和密码错误!
commit方法
当我们通过pymysql来执行增删改动作的时候,需要commit以下才能生效。
sql='insert into userinfo(name,password) values(%s,%s);'
res=cursor.executemany(sql,[("root","123456"),("lhf","12356"),("eee","156")]) #执行sql语句,返回sql影响成功的行数,一次插多条记录
print(res)
#上面的几步,虽然都有返回结果,也就是那个受影响的函数res,但是你去数据库里面一看,并没有保存到数据库里面,
conn.commit() #必须执行conn.commit,注意是conn,不是cursor,执行这句提交后才发现表中插入记录成功,没有这句,上面的这几步操作其实都没有成功保存。
mysq注入
就是利用mysql 语法 使其 查询条件永远为真
解决方案 让mysql帮我们拼接
import pymysql
conn = pymysql.connect(host='127.0.0.1', user='root', password="123",
database='day43')
cur = conn.cursor()
user = "akhksh' or 1=1 ;-- "
password = '*******'
sql = "select * from userinfo where username = %s and password =%s;"
print(sql)
cur.execute(sql,(user,password))
ret = cur.fetchone()
print(ret)
cur.close()
conn.close()
查询
# 光标会记录位置 取得那就会记录此时的位置
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='',
database='daycs',
charset='utf8',
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "select * from book;"
ret = cursor.execute(sql)#ret 受影响的行数
print(ret)#ret 受影响的行数
cursor.scroll(1,'absolute') #绝对移动,按照数据最开始位置往下移动1条
print(cursor.fetchmany()) #取出多条 默认取出1条
# print(cursor.fetchone()) #取出单条
# print(cursor.fetchall()) #取出所有的
cursor.scroll(3,'absolute') #绝对移动,按照数据最开始位置往下移动3条
cursor.scroll(3,'relative') #相对移动,按照当前光标位置往下移动3条
cursor.close()#关闭游标
conn.close()#关闭连接
增
# 光标会记录位置 取得那就会记录此时的位置
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='',
database='daycs',
charset='utf8',
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = "insert into book values(%s,'eg','知识没有用出版社',200,'2047-7-5');"
ret = cursor.execute(sql,('独孤九'))
print(ret)#ret 受影响的行数
conn.commit()# 增删改都必须进行提交操作(commit)
操作文件 建表
文件内容
倚天屠龙记 egon 北京工业地雷出版社 70 20190701
九阳神功 alex 人民音乐不好听出版社 5 20180704
九阴真经 yuan 北京工业地雷出版社 62 20170712
九阴白骨爪 jinxin 人民音乐不好听出版社 40 20190807
独孤九剑 alex 北京工业地雷出版社 12 20170901
降龙十巴掌 egon 知识产权没有用出版社 20 20190705
葵花宝典 yuan 知识产权没有用出版社 33 20190802
学python从开始到放弃|alex|人民大学出版社|50|20180701
学mysql从开始到放弃|egon|机械工业出版社|60|20180603
学html从开始到放弃|alex|机械工业出版社|20|20180401
学css从开始到放弃|wusir|机械工业出版社|120|20180502
学js从开始到放弃|wusir|机械工业出版社|100|20180730
利用python操作
#第一步手动创建表
# create table book(
# id int primary key ,
# book_name char(20) not null,
# author char(12) not null,
# press char(20) not null,
# price float(6,2),
# pub_date date
# );
# 写入数据
import pymysql
conn = pymysql.Connection(host='127.0.0.1', user='root', password="",
database='daycs')
cur = conn.cursor()#右边
with open('book.txt',encoding='utf-8') as f:
try:
for line in f:
line = line.strip()
if ' ' in line:
lst = line.split(' ')
elif '|' in line:,
lst = line.split('|')
sql = 'insert into book(book_name,author,press,price,pub_date) values (%s,%s,%s,%s,%s);'
cur.execute(sql,lst)
except Exception:
conn.rollback()#操作不成功 回滚
conn.commit()
cur.close()
conn.close()
# select book_name,price from book where author = 'egon'
# 2.找出最贵的图书的价格
# select max(price) from book;
# select price,book_name from book order by price desc limit 1;
# 3.求所有图书的均价
# select avg(price) from book;
# 4.将所有图书按照出版日期排序
# select * from book order by pub_date;
# 5.查询alex写的所有书的平均价格
# select avg(price) from book where author = 'alex'
# 扩展: 求所有人自己出版的图书的平均价格
# select author,avg(price) from book group by author
# 扩展: 求所有人自己出版的图书的平均价格>30的所有人
# select author from book group by author having avg(price)>30
# 6.查询人民音乐不好听出版社出版的所有图书
# select * from book where press = '人民音乐不好听出版社';
# 7.查询人民音乐出版社出版的alex写的所有图书和价格
# select * from book where press = '人民音乐不好听出版社' and author = 'alex';
# 8.找出出版图书均价最高的作者
# select author,avg(price) as avg_p from book group by author order by avg_p desc limit 1;
# 9.找出最新出版的图书的作者和出版社
# select author,press from book order by pub_date desc limit 1;
# 10.显示各出版社出版的所有图书
# select press,group_concat(book_name) from book group by press;
# 11.查找价格最高的图书,并将它的价格修改为50元
# select max(price) from book;
# update book set price = 50 where price = 70
# 12.删除价格最低的那本书对应的数据
# select min(price) from book;
# delete from book where price = 5;
# 13.将所有alex写的书作者修改成alexsb
# update book set author = 'alexsb' where author = 'alex';
# 14.select year(publish_date) from book
# 自己研究上面sql语句中的year函数的功能,完成需求:
# 将所有2017年出版的图书从数据库中删除
# delete from book where year(publish_date) = 2017;
第三节 DBUtils
DBUtils是Python的一个用于实现数据库连接池的模块。
此连接池有两种连接模式:
模式一:为每个线程创建一个连接,线程即使调用了close方法,也不会关闭,只是把连接重新放到连接池,供自己线程再次使用。当线程终止时,连接自动关闭。
POOL = PersistentDB(
creator=pymysql, # 使用链接数据库的模块
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
closeable=False,
# 如果为False时, conn.close() 实际上被忽略,供下次使用,再线程关闭时,才会自动关闭链接。如果为True时, conn.close()则关闭链接,那么再次调用pool.connection时就会报错,因为已经真的关闭了连接(pool.steady_connection()可以获取一个新的链接)
threadlocal=None, # 本线程独享值得对象,用于保存链接对象,如果链接对象被重置
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8'
)
def func():
conn = POOL.connection(shareable=False)
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
conn.close()
func()
模式二:创建一批连接到连接池,供所有线程共享使用。
PS:由于pymysql、MySQLdb等threadsafety值为1,所以该模式连接池中的线程会被所有线程共享。
import time
import pymysql
import threading
from DBUtils.PooledDB import PooledDB, SharedDBConnection
POOL = PooledDB(
creator=pymysql, # 使用链接数据库的模块
maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数
mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建
maxcached=5, # 链接池中最多闲置的链接,0和None不限制
maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错
maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制
setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
ping=0,
# ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8'
)
def func():
# 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常
# 否则
# 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。
# 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。
# 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,再封装到PooledDedicatedDBConnection中并返回。
# 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。
conn = POOL.connection()
# print(th, '链接被拿走了', conn1._con)
# print(th, '池子里目前有', pool._idle_cache, '
')
cursor = conn.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
conn.close()
func()
如果没有连接池,使用pymysql来连接数据库时,单线程应用完全没有问题,但如果涉及到多线程应用那么就需要加锁,一旦加锁那么连接势必就会排队等待,当请求比较多时,性能就会降低了。
加锁的情况:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
import threading
from threading import RLock
LOCK = RLock()
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8')
def task(arg):
with LOCK:
cursor = CONN.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
print(result)
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
不加锁的情况,会报错:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
import threading
CONN = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
database='pooldb',
charset='utf8')
def task(arg):
cursor = CONN.cursor()
cursor.execute('select * from tb1')
result = cursor.fetchall()
cursor.close()
print(result)
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
本节作业
-
通过pymysql完成下面表的数据的增长改查
看表结构。
create table t1(
id int primary key auto_increment,
name char(10) not null unique,
age int default
)