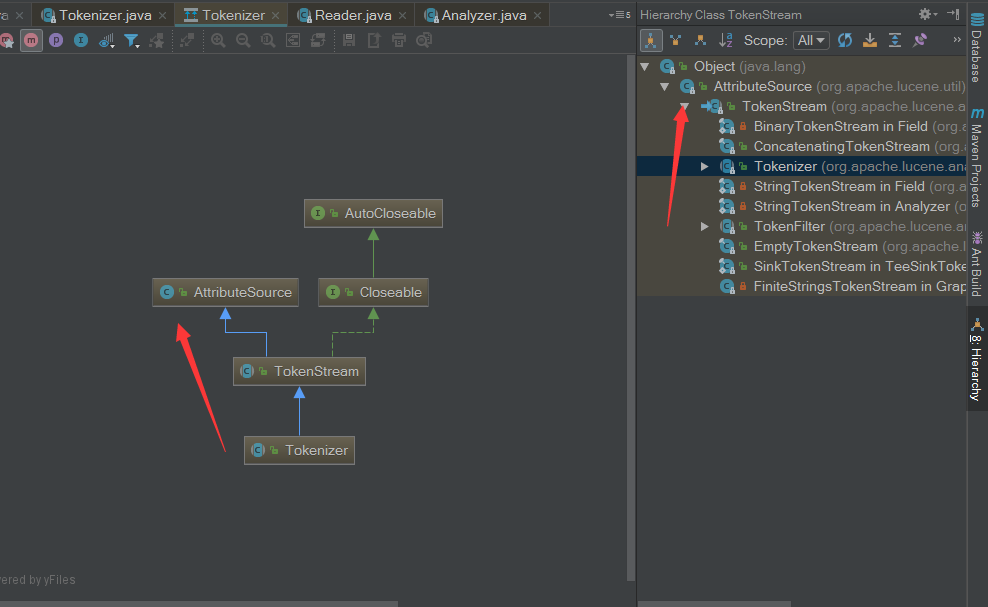
看一下继承图,Tokenizer和TokenFilter都是继承于TokenStream,TokenStream继承了AttributeSource
package com.lucene.demo.analizer;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenFilter;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.util.Attribute;
import org.apache.lucene.util.AttributeImpl;
import org.apache.lucene.util.AttributeReflector;
import java.io.IOException;
public class SansamAnalyzer extends Analyzer{
/**
*
*/
@Override
protected TokenStreamComponents createComponents(String fieldName) {
//装饰器模式,将分出的词项用filter进行处理,可以链式装饰实现多个filter
MyTokenizer myTokenizer = new MyTokenizer();
MyLowerCaseTokenFilter myLowerCaseTokenFilter = new MyLowerCaseTokenFilter(myTokenizer);
return new TokenStreamComponents(myTokenizer, myLowerCaseTokenFilter);
}
public static class MyTokenizer extends Tokenizer{
//调用AttributeSource-addAttribute方法
//维护了一个attributes Map,实现可复用
//private final Map<Class<? extends Attribute>, AttributeImpl> attributes;
//private final Map<Class<? extends AttributeImpl>, AttributeImpl> attributeImpls;
MyAttribute attribute = this.addAttribute(MyAttribute.class);
char[] buffer = new char[255];
int length = 0;
int c;
@Override
public boolean incrementToken() throws IOException {
//进行分析处理逻辑
clearAttributes();
length = 0;
while (true){
c = this.input.read();
if(c == -1){
if(length > 0){
this.attribute.setChar(buffer,length);
return true;
}else {
return false;
}
}
if(Character.isWhitespace(c)){
if(length > 0){
this.attribute.setChar(buffer,length);
return true;
}
}
buffer[length++] = (char)c;
}
}
}
public static class MyLowerCaseTokenFilter extends TokenFilter{
public MyLowerCaseTokenFilter(TokenStream s){
super(s);
}
MyAttribute attribute = this.addAttribute(MyAttribute.class);
@Override
public boolean incrementToken() throws IOException {
//获取一个分词项进行处理
boolean b = this.input.incrementToken();
if (b){
char[] chars = this.attribute.getChar();
int length = this.attribute.getLength();
if(length > 0){
for (int i = 0; i < length; i++) {
chars[i] = Character.toLowerCase(chars[i]);
}
}
}
return b;
}
}
/**
* 自定义Attribute属性接口 继承Attribute
*/
public static interface MyAttribute extends Attribute {
void setChar(char [] c, int length);
char [] getChar();
int getLength();
String getString();
}
/**
* 必须使用interface+Impl 继承AttributeImpl
*/
public static class MyAttributeImpl extends AttributeImpl implements MyAttribute {
char [] term = new char[255];
int length = 0;
@Override
public void setChar(char[] c, int length) {
this.length = length;
if(c.length > 0){
System.arraycopy(c,0,term,0,length);
}
}
@Override
public char[] getChar() {
return term;
}
@Override
public int getLength() {
return length;
}
@Override
public String getString() {
if(length > 0){
return new String(term,0,length);
}
return null;
// return new String(term); //不能直接返回 因为长度问题 默认255字符
}
@Override
public void clear() {
term = null;
term = new char[255];
this.length = 0;
}
@Override
public void reflectWith(AttributeReflector reflector) {
}
@Override
public void copyTo(AttributeImpl target) {
}
}
public static void main(String[] args) {
String text = "Hello World A b C";
try(SansamAnalyzer analyzer = new SansamAnalyzer();
//调用tokenStream()时 会先得到TokenStreamComponents对象 得到了MyLowerCaseTokenFilter 对象 观察其构造方法及此方法的返回值
TokenStream stream = analyzer.tokenStream("title",text);){
MyAttribute attribute = stream.getAttribute(MyAttribute.class);
stream.reset();
while (stream.incrementToken()){
System.out.print(attribute.getString()+" | ");
}
stream.end();
}catch (Exception e){
e.printStackTrace();
}
}
}