全书目录
本文目录
第4章 服务弹性........................................................................................................ 1
4.1 负载均衡..................................................................................................... 1
4.2 超时............................................................................................................ 3
4.3 重试............................................................................................................ 5
4.4 断路器......................................................................................................... 7
4.5 池弹出....................................................................................................... 13
4.6 组合:断路器 + 池弹出 + 重试.................................................................. 16
第4章 服务弹性
请记住你的服务和应用会在不可靠网络上进行通信。过去,程序员们经常尝试使用一些框架,比如EJB、CORBA、RMI等,来将基于网络的调用简化为如同本地函数调用那样。这没法让程序员们安心,因为在没法确定应用能够应对所有网络故障的情况下,是没法相信整个系统能完全应对故障的。因此,你永远没法假设,一个通过网络被远程调用的实体能永远在期望的时间内返回所期望的内容(或者说,正如The Hitchhiker’s Guide to the Galaxy一书的作者Douglas Adams曾经说的,人们常常犯的一个错误就是低估了傻瓜的创造性)。你也不想单个服务的不正常行为成为影响整个系统的一个致命错误。
Istio带来了实现应用弹性的很多能力,但正如前文所说,这些能力来自边车代理。而且,本章会介绍的弹性功能其实不依赖于任何变成语言和运行时,不管你选择何种库或框架去实现你的服务:
-
客户端侧负载均衡:Istio增强了Kubernetes的负载均衡功能。
-
超时:等待返回N秒后就不再等待。
-
重试:如果一个pod返回503之类的错误,则尝试其它pod。
-
简单断路器:为了不让降级了的服务被请求淹没,可开启断路器拒绝更多的请求。
-
池弹出(Pool ejection):将出错了的pod从负载均衡池中移出。
接下来我们会通过示例程序介绍这些功能。本章我们依然会使用前几章中用到的customer、preference和recommendation等服务。
4.1 负载均衡
一个增加吞吐和降低延迟的核心能力是负载均衡(load balancing)。一个常见实现是使用一个集中式负载均衡器,负责接收所有客户端的连接,然后将请求分发给后端系统。这是一种非常好的实现,但是,负载均衡器可能成为整个系统的瓶颈或故障单点。负载均衡能力可以被转移至客户端,通过使用客户端侧负载均衡器。客户端侧负载均衡器可使用高级负载均衡算法来增加系统可用性、降低延迟以及增加吞吐能力。
Istio的Envoy代理和应用容器运行在同一个pod中,本身具有负载均衡能力,因此就可成为应用的客户端侧负载均衡器。它支持如下算法:
-
ROUND_ROBIN(轮询):这种算法平均分配负载,轮流将负载转发给负载均衡池中的后端。
-
RANDOM(随机):这种算法随机地将负载分配给池中的后端。
-
LEAST_CONN(最小连接数):这种算法随机地从池中选择两个后端,然后将负载转发给连接较少的那个。这是一种带权重最小请求数算法的实现。
在前面关于路由的章节中,你用到了DestionationRule和VirtualService对象去控制流量如何被导向特定pod。本章中,我们会介绍利用DestionationRule去控制特定pod的通信行为。一开始,我们会讨论如何利用Istio DestionationRule去配置负载均衡。
首先,请确保没有DestionationRule实例存在。你可使用下面的命令去删除DestionationRule和VirtualService对象:
oc delete virtualservice --all -n tutorial
oc delete destinationrule --all -n tutorial
然后,将recommendation服务的副本数扩大到3:
oc scale deployment recommendation-v2 --replicas=3 -n tutorial
过一会,所有pod都会达到正常状态,能接受请求了。现在,利用之前用到的脚本去向系统发送请求:
#!/bin/bash
while true
do curl customer-tutorial.$(minishift ip).nip.io
sleep .1
done
通过输出你能看到默认轮询负载均衡效果:
customer => ... => recommendation v1 from '99634814': 1145
customer => ... => recommendation v2 from '6375428941': 1
customer => ... => recommendation v2 from '4876125439': 1
customer => ... => recommendation v2 from '2819441432': 181
customer => ... => recommendation v1 from '99634814': 1146
customer => ... => recommendation v2 from '6375428941': 2
customer => ... => recommendation v2 from '4876125439': 2
customer => ... => recommendation v2 from '2819441432': 182
customer => ... => recommendation v1 from '99634814': 1147
现在,将负载均衡算法改为RANDOM,利用下面的Istio DestionationRule定义:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: recommendation
namespace: tutorial
spec:
host: recommendation
trafficPolicy:
loadBalancer:
simple: RANDOM
这个目标策略配置到recommendation服务的请求使用随机负载均衡算法,发生在preference服务调用recommendation服务的时候,这时候Envoy代理就成了preference pod内的客户端侧负载均衡。
我们来创建这个对象:
oc -n tutorial create -f istiofiles/destination-rule-recommendation_lb_policy_app.yml
现在,在输出中你将看到更加随机的效果:
customer => ... => recommendation v2 from '2819441432': 183
customer => ... => recommendation v2 from '6375428941': 3
customer => ... => recommendation v2 from '2819441432': 184
customer => ... => recommendation v1 from '99634814': 1153
customer => ... => recommendation v1 from '99634814': 1154
customer => ... => recommendation v2 from '2819441432': 185
customer => ... => recommendation v2 from '6375428941': 4
customer => ... => recommendation v2 from '6375428941': 5
customer => ... => recommendation v2 from '2819441432': 186
customer => ... => recommendation v2 from '4876125439': 3
在继续下面的步骤前,先做下清理和恢复工作:
oc -n tutorial delete -f
istiofiles/destination-rule-recommendation_lb_policy_app.yml
oc scale deployment recommendation-v2 --replicas=1 -n tutorial
4.2 超时
超时(Timeout)是一种让系统具有弹性和高可用性的重要手段。通过网络调用服务可能会产生不可预料的结果,其中最恶劣的是延迟。延迟是因为目标服务故障了呢,还是只是慢了一些?它确实在运行着吗?高延迟意味着这些可能都发生了。那你的服务该如何应对呢?只是徒劳等待?如果有客户在等待这个请求,等待不是一个好办法。因为等待也占用资源,可能导致其他系统也出现等待,导致一连串错误。你的网络中可能随时出现超时,你可以使用Istio服务网格去应对。
在Istio中,超时是指Envoy代理等待业务服务响应的时长。一旦超过这个时长没有得到响应,那么Envoy代理将放弃继续等待,从而保证不会无限期等待某个响应。对HTTP请求默认响应时长为15秒,也就是说如果超过15秒业务服务没有反馈,则调用失败。
回到recommendation服务的代码,找到RecommendationVerticle.java类,注释掉能产生延迟的代码行:
public void start() throws Exception {
Router router = Router.router(vertx);
router.get("/").handler(this::timeout); // adds 3 secs
router.get("/").handler(this::logging);
router.get("/").handler(this::getRecommendations);
router.get("/misbehave").handler(this::misbehave);
router.get("/behave").handler(this::behave);
vertx.createHttpServer().requestHandler(router::accept)
.listen(LISTEN_ON);
}
保存代码更改,编译、打包和重新部署:
cd recommendation/java/vertx
mvn clean package
docker build -t example/recommendation:v2 .
oc delete pod -l app=recommendation,version=v2 -n tutorial
最后一步会导致v2版本pod被重建,使用刚刚构建的recommendation服务镜像。现在,调用customer服务,你会看到服务延迟:
time curl customer-tutorial.$(minishift ip).nip.io
customer => preference => recommendation v2 from
'2819441432': 202
real 0m3.054s
user 0m0.003s
sys 0m0.003s
你可以多调用几次。Recommendation服务的v1版本不会延迟,因为这部分代码没有被修改。
上面的例子中,虽然v2版本pod中的recommendation服务在3秒后才发回响应,但这时长没有超过默认15秒,因此Envoy代理不会放弃等待,因此调用还是成功了。但是,在某些场景中,默认时长可能不太合适,因此需要调整。Istio的VirutalService类型允许你在单个服务层面动态调整超时时长。
下面的VirtualService对象定义中将调用recommendation服务的超时时长设置为1秒钟:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
timeout: 1.000s
使用下面的命令去创建VirtualService对象:
oc -n tutorial create -f
istiofiles/virtual-service-recommendation-timeout.yml
再给customer服务发出请求,你会看到请求要么成功(此时请求都路由到recommendation服务的v1版本),要么返回504错误(此时请求被路由到v2版本):
time curl customer-tutorial.$(minishift ip).nip.io
customer => 503 preference => 504 upstream request timeout
real 0m1.151s
user 0m0.003s
sys 0m0.003s
使用下面的命令去进行清理:
oc delete virtualservice recommendation -n tutorial
4.3 重试
因为网络天生的不可靠性,以及服务pod也可能会临时宕机,你可能会遇到间歇性错误,对于每周甚至每天多次部署的分布式微服务来说遇到这种错误的可能性会更大。使用Istio的重试功能,在真正处理错误之前,你可以进行多次重试。下面我们看如何利用Istio做到这一点。
首先你要做的是模拟间歇性网络出错。在recommendation服务例子中,有个特定的端点,它只是设置一个标志位;这个标志位将getRecommendations函数的返回值设置为503。要将这个misbehave标志位设置为true,进入v2 pod,然后执行下面的命令:
oc exec -it $(oc get pods|grep recommendation-v2
|awk '{ print $1 }'|head -1) -c recommendation /bin/bash
curl localhost:8080/misbehave
现在,当你请求customer服务时,你会看到一些503错误:
#!/bin/bash
while true
do
curl customer-tutorial.$(minishift ip).nip.io
sleep .1
done
customer => preference => recommendation v1 from '99634814': 200
customer => 503 preference => 503 misbehavior from '2819441432'
现在来看下VirtualService中的重试配置:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
retries:
attempts: 3
perTryTimeout: 2s
这个定义将访问recommendation服务的重试次数设为3,每次超时时间设为2秒,因此累计超时时间为6秒,加上原调用所花的时间,就是整个调用所花的时间。
创建这个对象:
oc -n tutorial create -f
istiofiles/virtual-service-recommendation-v2_retry.yml
现在再发送请求,你不会看到错误了。这意味着即使遇到了503错误,Istio会自动进行重试。
customer => preference => recommendation v1 from '99634814': 35
customer => preference => recommendation v1 from '99634814': 36
customer => preference => recommendation v1 from '99634814': 37
customer => preference => recommendation v1 from '99634814': 38
在开始下面的步骤前,先做一些清理工作:
oc delete destinationrules --all -n tutorial
oc delete virtualservices --all -n tutorial
重启v2 pod,以将 mishehave 标志位恢复为false:
oc delete pod -l app=recommendation,version=v2
4.4 断路器
现代家庭所使用的电力安全装置断路器(circuit breaker)会保护特定设备免于承受过载的电流。也许你曾经看到,当插入一个录音机、吹风机甚至加热器到一插座中后,断路器会发生跳闸。电流过载会带来危险,因为它会让电线发热,这可能会导致火灾。断路器会开启并断开线路,防止危险发生。
注意:软件系统中的“断路器”概念首次由Micheel Nygard在他的书 Releast It!中引入,现在这本书出到了第二版。
在2012年Netflix发布的Hystrix库中的断路器和隔舱(bulkhead)模式已被广泛使用。Netflix的很多库,比如Eureka(用于服务发现)、Ribbon(用于负载均衡)和Hystrix(断路器和隔舱),在业内很快流行起来,并开始用于微服务和云原生架构。Netflix OSS是在Kubernetes/OpenShift面世之前发布的,确实存在一些不足,比如它只支持Java,要求应用开发者将库封装到应用中等。图4-1提供了一个时间线,介绍从何时起软件业界开始把单体应用开发团队和大规模的几个月的瀑布开发模式开始拆分,到Netflix OSS的诞生,再到微服务属于被提出。
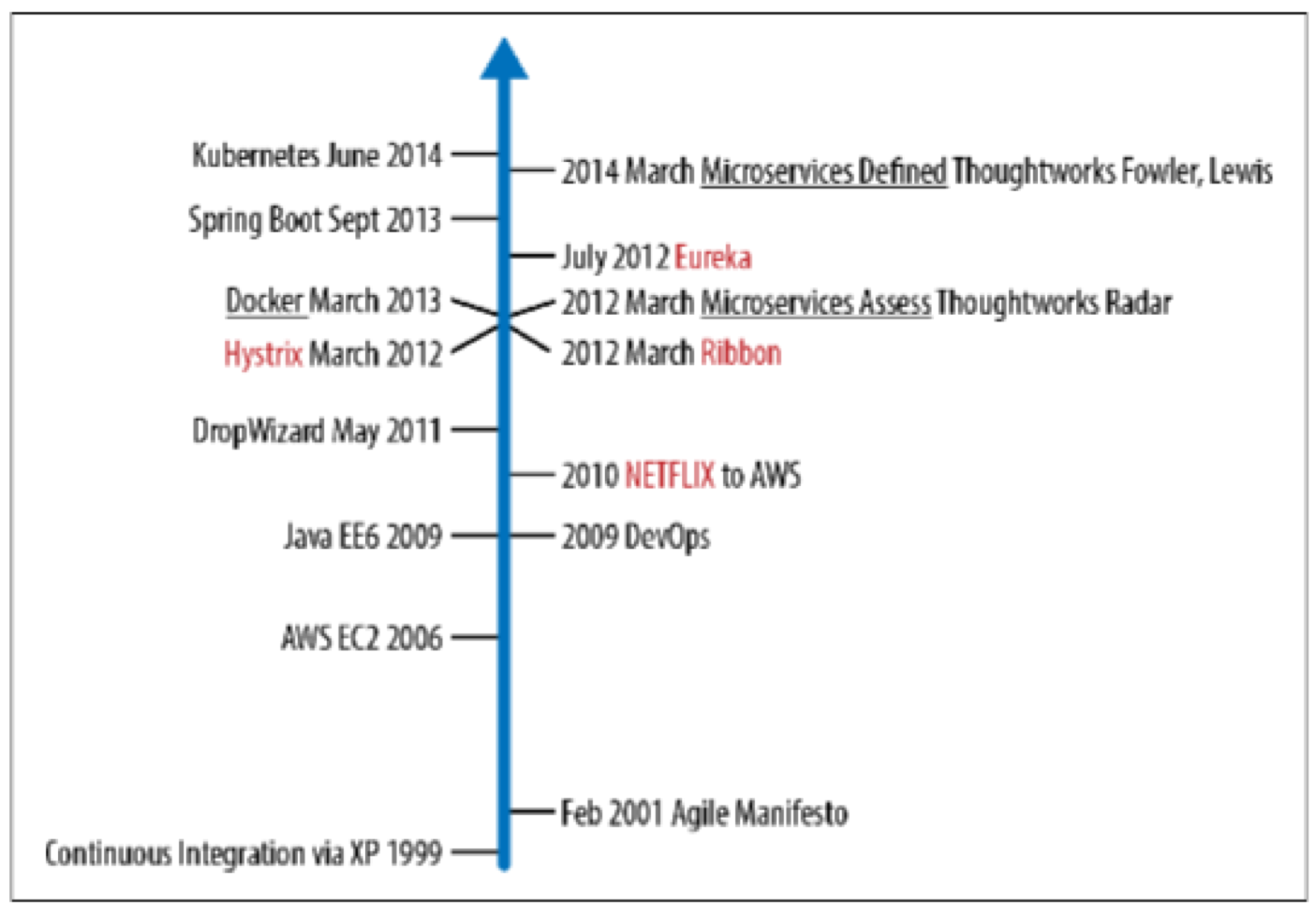
图4-1.微服务时间线
Istio将更多的弹性实现下沉到基础架构中,这样你可以将宝贵的时间和精力放到业务逻辑中去,从而创造业务差异性优势。
Istio可在连接池层面实现断路器功能。要进行测试验证,首先要确保recommendation v2版本开启了3秒的延迟。修改后的RecommendationVertical.java文件中如下面所示:
Router router = Router.router(vertx);
router.get("/").handler(this::logging);
router.get("/").handler(this::timeout); // adds 3 secs
router.get("/").handler(this::getRecommendations);
router.get("/misbehave").handler(this::misbehave);
router.get("/behave").handler(this::behave);
使用下面的Istio DestionationRule将流量导至v1和v2版本的recommendation服务:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- labels:
version: v1
name: version-v1
- labels:
version: v2
name: version-v2
使用如下命令创建DestionationRule对象:
oc -n tutorial create -f
istiofiles/destination-rule-recommendation-v1-v2.yml
然后定义VirtualService对象:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- route:
- destination:
host: recommendation
subset: version-v1
weight: 50
- destination:
host: recommendation
subset: version-v3
weight: 50
再创建VirtualService对象:
oc -n tutorial create -f
istiofiles/virtual-service-recommendation-v1_and_v2_50_50.yml
在第一章中,我们推荐你安装Siege命令行工具,它可用于通过命令行进行简单的压力测试。
我们使用20个客户端,每个发送2个并发请求给customer服务,使用下面的命令:
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io
你会看到如下输出:
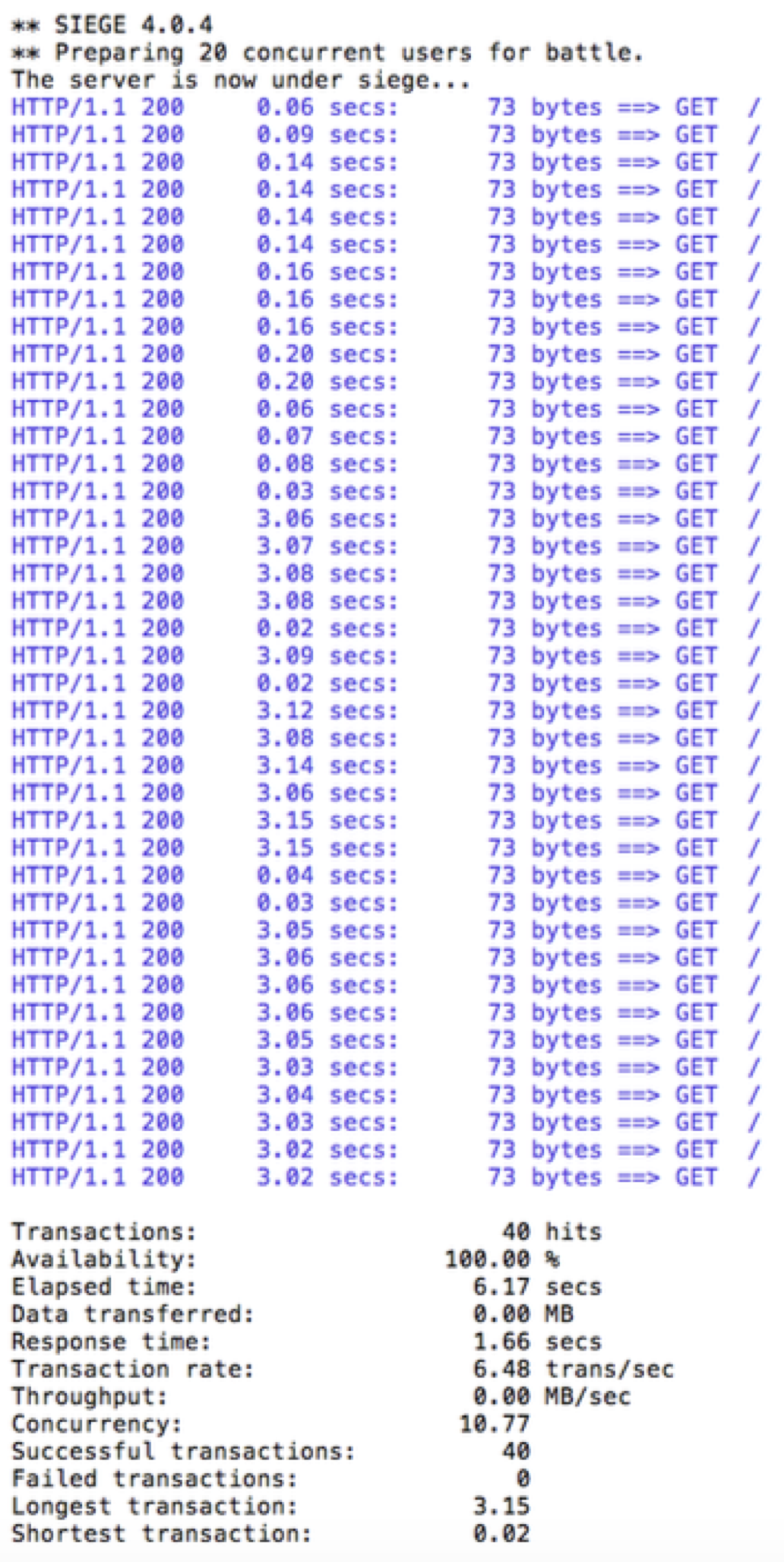
所有请求都成功了,但花的时间比较长,因为v2 pod的响应比较慢。假设生产环境中3秒的延迟是因为一个实例或pod上有太多的请求造成的,你不想大量请求都放到队列中,也不想那个实例或pod会越来越慢。此时,可以增加断路器。
要为服务创建断路器功能,创建如下DestionationRule定义:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- name: version-v1
labels:
version: v1
- name: version-v2
labels:
version: v2
trafficPolicy:
connectionPool:
http:
http1MaxPendingRequests: 1
maxRequestsPerConnection: 1
tcp:
maxConnections: 1
outlierDetection:
baseEjectionTime: 120.000s
consecutiveErrors: 1
interval: 1.000s
maxEjectionPercent: 100
接下来应用这个定义:
oc -n tutorial replace -f istiofiles/destination-rule-recommendation_cb_policy_version_v2.yml
因为前面的VirtualService将流量在v1和v2之间平分,因此,这个DestionationRule只会对一半流量起作用。这个定义限制连接数和等待请求数为1(其它设置会在第50页上的Pool Injection章节进行介绍)。
现在,再次运行siege命令:
siege -r 2 -c 20 -v customer-tutorial.$(minishift ip).nip.io

你会看到几乎所有请求都在1秒内就完成了,而且没有任何报错。你可以尝试更多次,以确认这个结果是稳定的。断路器会将任何等待请求或连接数超过阈值的连接断开。断路器的目标是快速断开。
做下环境清理:
oc delete virtualservice recommendation -n tutorial
oc delete destinationrule recommendation -n tutorial
4.5 池弹出
我们所要讨论的最后一个弹性能力,会确定不正常工作的集群节点,并在一段时间(冷却期)内不向它导入任何流量(实际上是将它从负载均衡池中弹出)。因为Istio代理是基于Envoy的,而Envory将这种实现称为异常检测(outlier detection),我们会在Istio中使用同样的术语。
想象一个场景,你的软件开发团队每周几次在在工作日的中午将各组件部署到生产环境,此时可人为删除故障pod以保证系统弹性。池弹出(Pool ejection)或异常检测是一种很有用的弹性策略,当有一组pod服务于客户端请求时。当请求被发往一个pod,而这个pod出错了(比如返回50x错误)时,Istio会在一定时间内将该pod从池中弹出。在我们的例子中,冷却期被设置为15秒。这种做法通过确保正常的pod参与请求处理,从而增加了系统总体可用性。
首先,你要确保已有了DestionationRule和VirtualService对象。我们将流量分为两半:
oc -n tutorial create -f
istiofiles/destination-rule-recommendation-v1-v2.yml
oc -n tutorial create -f
istiofiles/virtual-service-recommendation-v1_and_v2_50_50.yml
然后,将recommendation服务的v2 pod的数目扩展到2,以在负载均衡池中有多个实例:
oc scale deployment recommendation-v2 --replicas=2 -n tutorial
等待所有pod都正常运行,然后给customer服务产生一些请求:
#!/bin/bash
while true
do curl customer-tutorial.$(minishift ip).nip.io
sleep .1
done
你会看到在recommendation服务的两个版本之间做50/50的负载均衡。对于v2版本,你会看到一些请求被一个pod处理,另外的请求被另一个pod处理:
customer => ... => recommendation v1 from '99634814': 448
customer => ... => recommendation v2 from '3416541697': 27
customer => ... => recommendation v1 from '99634814': 449
customer => ... => recommendation v1 from '99634814': 450
customer => ... => recommendation v2 from '2819441432': 215
customer => ... => recommendation v1 from '99634814': 451
customer => ... => recommendation v2 from '3416541697': 28
customer => ... => recommendation v2 from '3416541697': 29
customer => ... => recommendation v2 from '2819441432': 216
要测试池弹出功能,你要让其中一个pod出错。找到v2 pod:
oc get pods -l app=recommendation,version=v2
recommendation-v2-2819441432 2/2 Running 0 1h
recommendation-v2-3416541697 2/2 Running 0 7m
进入一个pod, 执行命令,然后退出:
oc -n tutorial exec -it recommendation-v2-3416541697 -c recommendation /bin/bash
curl localhost:8080/misbehave
exit
这是一个特殊端点,它会让该pod返回503错误:
#!/bin/bash
while true
do curl customer-tutorial.$(minishift ip).nip.io
sleep .1
done
在输出中,你会看到每次recommendation-v2-3416541697收到请求后它都返回503错误:
customer => ... => recommendation v1 from '2039379827': 495
customer => ... => recommendation v2 from '2036617847': 248
customer => ... => recommendation v1 from '2039379827': 496
customer => ... => recommendation v1 from '2039379827': 497
customer => 503 preference => 503 misbehavior from '3416541697'
customer => ... => recommendation v2 from '2036617847': 249
customer => ... => recommendation v1 from '2039379827': 498
customer => 503 preference => 503 misbehavior from '3416541697'
好了,我们现在可以测试Istio的池弹出功能了。定义如下的DestionationRule对象:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
host: recommendation
subsets:
- labels:
version: v1
name: version-v1
trafficPolicy:
connectionPool:
http: {}
tcp: {}
loadBalancer:
simple: RANDOM
outlierDetection:
baseEjectionTime: 15.000s
consecutiveErrors: 1
interval: 5.000s
maxEjectionPercent: 100
- labels:
version: v2
name: version-v2
trafficPolicy:
connectionPool:
http: {}
tcp: {}
loadBalancer:
simple: RANDOM
outlierDetection:
baseEjectionTime: 15.000s
consecutiveErrors: 1
interval: 5.000s
maxEjectionPercent: 100
其中,Istio被配置为每隔5秒钟去检查不正常pod,并在发生1次后就将它从负载均衡池中移出去,而且保持15秒钟。
oc -n tutorial replace -f
istiofiles/destination-rule-recommendation_cb_policy_pool
_ejection.yml
给customer服务发送一些请求:
#!/bin/bash
while true
do curl customer-tutorial.$(minishift ip).nip.io
sleep .1
Done
你会发现一旦recommendation-v2-3416541697收到请求并返回503后,它都会被弹出负载均衡池不再接受请求,直到15秒钟的冷却期过期。
customer => ... => recommendation v1 from '2039379827': 509
customer => 503 preference => 503 misbehavior from '3416541697'
customer => ... => recommendation v1 from '2039379827': 510
customer => ... => recommendation v1 from '2039379827': 511
customer => ... => recommendation v1 from '2039379827': 512
customer => ... => recommendation v2 from '2036617847': 256
customer => ... => recommendation v2 from '2036617847': 257
customer => ... => recommendation v1 from '2039379827': 513
customer => ... => recommendation v2 from '2036617847': 258
customer => ... => recommendation v2 from '2036617847': 259
customer => ... => recommendation v2 from '2036617847': 260
customer => ... => recommendation v1 from '2039379827': 514
customer => ... => recommendation v1 from '2039379827': 515
customer => 503 preference => 503 misbehavior from '3416541697'
customer => ... => recommendation v1 from '2039379827': 516
customer => ... => recommendation v2 from '2036617847': 261
4.6 组合:断路器 + 池弹出 + 重试
从上面的输出可以看出,即使使用了池弹出,你的应用还是会有少量出错,但你可以继续进行优化。如果你的服务有足够数量的副本在环境中运行,你可以将Istio的多种能力组合在一起来增强后端弹性:
-
断路器:避免给一个实例发送过量请求
-
池弹出:从负载均衡池中将故障实例弹出
-
重试:当断路器或池弹出发生时,将请求发往其它实例
在当前VirtualService中增加一些简单配置,我们就能完全避免503错误响应。这意味着每次从被弹出实例收到503故障返回时,Istio会将请求发往另一个正常实例:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
creationTimestamp: null
name: recommendation
namespace: tutorial
spec:
hosts:
- recommendation
http:
- retries:
attempts: 3
perTryTimeout: 4.000s
route:
- destination:
host: recommendation
subset: version-v1
weight: 50
- destination:
host: recommendation
subset: version-v2
weight: 50
替代当前的VirtualService服务:
oc -n tutorial replace -f istiofiles/virtual-service-recommendation-v1_and_v2_retry.yml
然后向customer端点发起请求:
#!/bin/bash
while true
do curl customer-tutorial.$(minishift ip).nip.io
sleep .1
done
你不会再收到503错误了:
customer => ... => recommendation v1 from '2039379827': 538
customer => ... => recommendation v1 from '2039379827': 539
customer => ... => recommendation v1 from '2039379827': 540
customer => ... => recommendation v2 from '2036617847': 281
customer => ... => recommendation v1 from '2039379827': 541
customer => ... => recommendation v2 from '2036617847': 282
customer => ... => recommendation v1 from '2039379827': 542
customer => ... => recommendation v1 from '2039379827': 543
customer => ... => recommendation v2 from '2036617847': 283
customer => ... => recommendation v2 from '2036617847': 284
出故障的recommendation-v2-3416541697不会再出现,这要归功于Istio的池弹出和重试功能。
最后做下清理,在RecommendationVertical.java中删除延迟代码,重新构建docker镜像,删除故障pod,然后删除DestionationRule和VirtualService对象:
cd recommendation/java/vertx
mvn clean package
docker build -t example/recommendation:v2 .
oc scale deployment recommendation-v2 --replicas=1 -n tutorial
oc delete pod -l app=recommendation,version=v2 -n tutorial
oc delete virtualservice recommendation -n tutorial
oc delete destinationrule recommendation -n tutorial
现在,你已看到如何让服务到服务之间的调用更加弹性和健壮。接下来,在第5章中,我们会介绍如何通过引入混乱来有意中断某些服务。
书籍英文版下载链接为 https://developers.redhat.com/books/introducing-istio-service-mesh-microservices/,作者 Burr Sutter 和 Christian Posta。
本中文译稿版权由本人所有。水平有限,错误肯定是有的,还请海涵。
感谢您的阅读,欢迎关注我的微信公众号:
