漫谈MSPetShopV4中的分布式事务与SQL写法
作者:sagahu@163.com,2013-03-11,太原。
关键词:分布式事务、.net Enterprice Service、严格SQL、悲观SQL
MSPetShop是微软.net框架技术的经典技术演示范例,尽管不是实际的应用,但是我们.net程序人仍然能从中学到各种各样的东西,真是智者见智,仁者见仁。我写这篇文章,主要是想总结其中的分布式事务与严格SQL写法,与同好交流,欢迎大家拍砖。
之所以选择V4版本,是因为从V5版代码开始使用Linq to Entity,其对ADO.NET的封装层次更高,更不容易看清数据访问层的本质,尽管其仍然使用分布式事务!
一、分布式事务这么用
打开解决方案的BLL项目中的Order.cs类文件,其中有几个业务规则方法。
(1)首先看这个类的注释:
/// <summary>
/// A business component to manage the creation of orders
/// Creation of an order requires a distributed transaction
/// </summary>
哦,这个类是本方案中生成订单的业务规则部件;订单生成需要分布式事务支持。
(2)接下来看插入订单方法的注释:
/// <summary>
/// A method to insert a new order into the system
/// As part of the order creation the inventory will be reduced by the quantity ordered
/// </summary>
/// <param name="order">All the information about the order</param>
这个方法的注释说:①本方法负责往系统中插入一个订单;②订单生成的部分工作是根据订单减少产品库存;③它的输入参数"order"包含从前台购物车转化过来的全部订单信息。
(3)接下来,对照注释来看插入订单方法的具体代码:
public void Insert(OrderInfo order) {
// Call credit card procesor
ProcessCreditCard(order);
// Insert the order (a)synchrounously based on configuration
orderInsertStrategy.Insert(order);
}
只有两行代码:
第一行是调用信用卡处理模块,这是我们会发现,原来在线支付也是订单生成的一部分工作。做电子商务的同行可以很理解此点的。
第二行代码是调用订单策略,执行往数据库插入订单的操作;提前告诉大家,前面注释中说的减少产品库存也会封装在这第二行代码里。
对于这两行代码,我们可以总结:
生成一个订单,共有三项操作:①根据前端生成订单信息执行在线支付;②往数据库中插入这个订单;③根据订单较少库存(修改库存数据)。
当然,我们希望把这三项操作组合为一个事务:要么全部成功,一切OK;其中一个失败,全部回滚!
(4)MSPetShop V4 生成订单流程图,好像有小BUG
MSPetShop的订单、产品、库存并不在一个数据库中。对于跨库事务,可以使用分布式事务技术来解决。但是现实中第三方在线支付/信用卡功能模块大多不支持在外部对其进行事务回滚,也就是不允许把它组合在客户的分布式事务里面。还是看看微软咋玩儿的吧。
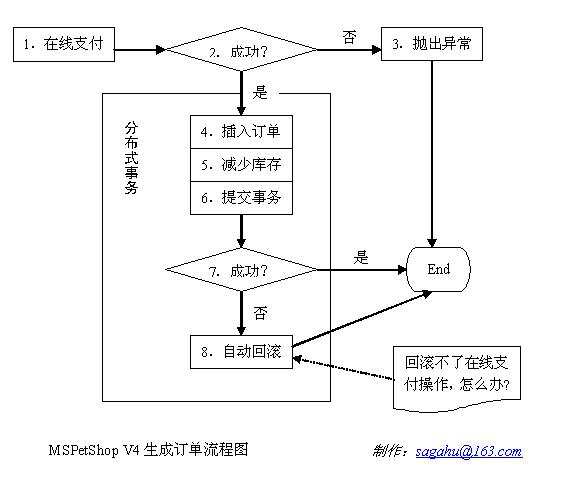
本人根据MSPetShop V4版的代码实现,总结出了这个流程图:MSPetShop V4版把插入订单、减少库存两项操作使用分布式事务组合在了一起,忽略了可能的事务组合失败情况下对在线支付操作的应对!哦,这意味着可能发生:客户支付成功,但是系统生成订单失败;但是这种BUG只能通过PetShop网站与银行对帐才能找到丢失的数据!当然我们不能肤浅地把此归罪于微软,因为这个范例仅仅是微软的技术示例,不是真正的实际案例。
下面本人提出一些思路供大家探讨。到这里我们明确了这样的需求:共三项操作;其中的在线支付是不能包含在分布式事务中的,只能单独处理;其它2项必须使用分布式事务组合在一起。
第一种思路:可以尝试在事务的回滚环节增加一个日志操作,记录客户支付成功,但是订单生成失败的信息,来使得系统可以发现这种有“病”的程序流向与相关数据。当然,增加的这个日志操作也有失败的可能性,但是至少比原来那样对BUG不声不响要好多了。
第二种思路:把在线支付操作调整到分布式事务后面来,这样只有在前面订单事务成功的情况下,才会执行在线支付;如果在线支付失败,增加记录支付失败的信息,以后再要求客户完成订单的支付。也就是说,在线支付还需要单独拆分成一个允许客户在一定时期内追补执行的独立操作。当然客户支付成功后给订单修改支付成功标记的操作还是存在失败的可能,这样也是比原来那样对BUG不声不响要好多。
总结这两种思路,后者比MSPetShop V4方案与第一种思路更加方便操作,事实上当今现实中大多数电子商务的订单就是这么实现的(允许客户在后期追加支付操作);仍然存在第三方支付与电子商务系统订单生成之间的脱节可能性,但是也算尽量避免系统对于这种BUG的“一声不吭忽略掉”;系统与第三方支付平台的对帐是不可逃避的最终手段,我提出的2种思路是要尽量减少对这种工作的诉求。
这里我就不乱放自己的实现代码献丑了,还是让大家群思共议吧。接下来还是回到MSPetShop V4来吧。
(5)稍微注意下在线支付
/// <summary>
/// Process credit card and get authorization number.
/// </summary>
/// <param name="order">Order object, containing credit card information, total, etc.</param>
private void ProcessCreditCard(OrderInfo order) {
// In the real life environment here should be a call to the credit card processor API.
// We simulate credit card processing and generate an authorization number.
Random rnd = new Random();
order.AuthorizationNumber = (int)(rnd.NextDouble() * int.MaxValue);
// Check if authorisation succeded
if (!order.AuthorizationNumber.HasValue)
throw new ApplicationException(CREDIT_CARD_ERROR_MSG);
}
这个方法前2行代码模拟对信用卡处理接口的调用,实现在线支付。它简单地使用伪随机算法,产生一个授权码,这个授权码给了订单的一个相应属性,用作将来系统与第三方在线支付机构对帐的依据。国内第三方支付模块实际返回的信息要多些,例如订单号、时间、金额等等,这些信息也是供对帐用的。
此方法最下面2行代码表示:如果在线支付失败,则向上层抛出异常。所以上面的主调层次必须监查此异常,予以恰当的处理。
(6)查看同步订单策略中的分布式事务代码
在MSPetShop V4里,订单策略实现有同步、异步之分。异步订单策略通过使用微软消息队列技术来实现,同步策略实现相对更加简单一些,我们还是看这个简单点的吧。我们忽略掉订单策略对象的创建(工厂方法、反射技术),直接打开BLL项目的OrderSynchronous.cs文件,这个类实现同步订单策略。
查看数据访问层订单插入方案的实现:
/// <summary>
/// Inserts the order and updates the inventory stock within a transaction.
/// </summary>
/// <param name="order">All information about the order</param>
public void Insert(PetShop.Model.OrderInfo order) {
using (TransactionScope ts = new TransactionScope(TransactionScopeOption.Required)) {
dal.Insert(order);
// Update the inventory to reflect the current inventory after the order submission
Inventory inventory = new Inventory();
inventory.TakeStock(order.LineItems);
// Calling Complete commits the transaction.
// Excluding this call by the end of TransactionScope's scope will rollback the transaction
ts.Complete();
}
}
它的注释:插入订单与更新库存量组成事务。
此方法使用TransactionScope把2项操作组合为一个事务。TransactionScope是.Net Framework 2.0之后,新增了一个名称空间。它的用途是为数据库访问提供了一个“轻量级”(区别于:SqlTransaction、OracleTransaction)的事务。使用之前必须添加对 System.Transactions.dll 的引用。在上面代码中的最后调用TransactionScope类的Complete()方法来提交事务,如果缺少这个调用,前面的操作会自动回滚。当然,如果前面任何一个环节执行发生异常,流程也会随异常而跳出,从而不会执行到最后一行,使得前面的操作发生自动回滚。
以上就是V4中分布式事务的典型实现:使用TransactionScope,调用数据访问层方法的组合,最后提交事务。而V3中使用的是.net Enterprice Services技术,编写代码与配置都麻烦多了,此处不予赘述。
使用TransactionScope,需要注意:在一个TransactionScope范围内,前面任何一行代码发生异常,都会引发它的自动回滚。所以,它所调用的任何操作,都需要严格、细心的写法,否则会造成业务规则的漏洞。假设一个分布式事务的例子,其中一个子操作是根据记录ID删除一行记录,实际执行时ADO.NET的Command对象AffectedRows属性返回0,表示没有删除任何记录,这个操作也没有发生任何异常。但是这个没有删除任何记录是你预期的结果之一吗?如果不是,那么修改那个删除代码,当AffectedRows属性返回0时抛出自定义异常来引发事务回滚吧。事实上MSPetShop在数据访问层的代码就是如此严格的。当然TransactionScope同样需要遵循使用事务的其它通用规律,例如不要包含需要太长时间操作等等。
二、严格的SQL写法
(1)MSPetShop V3/V4三层结构仍然是异型数据库适应的经典
本文不想讲解三层结构,只是说明以下观点:MSPetShop V3/V4三层结构是异型数据库适应的经典,业内许多通用性较强,走多种数据库适应路线的软件产品,常常采用了这种结构。尽管当前.net Entity Framework用的不少,其ORM机制好像比三层结构直观一点儿,但是MS除了对自家的SQLServer,对其它DBMS就欠风度了。据说EF4支持ORACLE,本人作为一线实践者,在把新东西总结提炼为自己的之前,还是必须用三层结构的,因为俺自个儿的旧货可靠。
(2)能写通用于不同DBMS的数据访问层吗?
前几天还见一个初学者说,数据访问层只需要把Provider修改下,就可从SQLServer切换为Oracle;另一个则说,反正我学的是标准SQL,我只用标准SQL,写通用的数据访问。这就是说,他们想对不同DMBS编写统一的数据访问层。可能吗?
我们知道,System.Data.SqlClient、System.Data.OracleClient、MySql.Data.MySqlClient等等都是遵循ADO.NET规范开发出来的Provider,确实可以封装为比较统一形式的MyConnection、MyTransaction、MyCommand、MyAdapter、MyReader、MyParameter等等,从而规范为统一的调用,例如微软企业类库。本人以为:仅仅这些还不足以写出通用的数据访问层,因为不同DBMS的SQL语法是不同的。
尽管有ISO标准SQL,但是我的体会是,稍微实际点的项目,标准SQL就不够用,所以在数据访问层SQL是不能完全统一的,从而数据访问层是应该分开写的。另外不同Provider的Command 参数语法也不同,SqlClient的参数“@”开头,OracleClient的参数“:”开头,MySqlClient则是“?”开头,等等。
所以,MSPetShop也不写通用的数据访问层,而是根据DBMS类型分开,使用抽象工厂模式来切换DAL模块。V4解决方案中SQLServer项目、Oracle项目都是针对其同名DBMS的DAL项目。接下来,我们忽略掉抽象工厂代码,还是以订单插入为例学习严格SQL的写法。
(3)用于SQLServer的订单插入SQL
打开SQLServer项目的Order.cs文件,查看订单Insert方法,忽略掉一些C#,原来它是想写类似下面的SQL:
-- a. 定义2个临时变量,注意这不是Command的参数
Declare @ID int;
Declare @ERR int;
-- b. 插入订单主记录,Command的参数共20个
INSERT INTO Orders VALUES(
@UserId, @Date, @ShipAddress1, @ShipAddress2, @ShipCity,
@ShipState, @ShipZip, @ShipCountry, @BillAddress1, @BillAddress2,
@BillCity, @BillState, @BillZip, @BillCountry, 'UPS', @Total,
@BillFirstName, @BillLastName, @ShipFirstName, @ShipLastName, @AuthorizationNumber, 'US_en');
SELECT @ID=@@IDENTITY;
-- c. 插入订单状态
INSERT INTO OrderStatus VALUES(@ID, @ID, GetDate(), 'P');
SELECT @ERR=@@ERROR;
-- d. 循环插入订单细项
INSERT INTO LineItem VALUES(@ID, @LineNumber0, @ItemId0, @Quantity0, @Price0);
SELECT @ERR=@ERR+@@ERROR;
INSERT INTO LineItem VALUES(@ID, @LineNumber1, @ItemId1, @Quantity2, @Price2);
SELECT @ERR=@ERR+@@ERROR;
-- 省略 ...
INSERT INTO LineItem VALUES(@ID, @LineNumberN, @ItemIdN, @QuantityN, @PriceN);
SELECT @ERR=@ERR+@@ERROR;
-- e. 查询返回SQLServer自动生成的标识列值与错误代码
SELECT @ID, @ERR
这一大段SQL是我把它们分行、分段,并加了注释,为了让大家看着好懂哦。其实这是根据SQLClient机制写的SQL语句“批”,可以通过Command一次性发送给DBMS来“批”执行。
再看微软最后的调用代码吧:
// Read the output of the query, should return error count
using (SqlDataReader rdr = cmd.ExecuteReader(CommandBehavior.CloseConnection)) {
// Read the returned @ERR
rdr.Read();
// If the error count is not zero throw an exception
if (rdr.GetInt32(1) != 0)
throw new ApplicationException("DATA INTEGRITY ERROR ON ORDER INSERT - ROLLBACK ISSUED");
}
//Clear the parameters
cmd.Parameters.Clear();
通过Command的ExecuteReader()方法来调用这个T-SQL“批”,如果返回的@ERR不为0,说明“批”中某一条语句执行在DBMS内的执行发生了问题,接下来就自己用C#抛出异常,从而引发BLL层那个TransactionScope的自动回滚。
注意啦:SQLServer在DBMS内的“批”执行中间发生错误时,外面主调的ADO.NET代码常常接收不到异常,呵呵,它就这么个德行,只能通过这种方式来判断“批”是否执行发生了错误。
以上就是T-SQL的严格写法,至少在分布式事务机制中需要多细心一些。
(4)用于ORACLE的订单插入SQL
与上面对应的订单Insert方法,在Oracle项目的Order.cs文件里,还是先忽略C#代码,来研究其SQL语句。
SELECT ORDERNUM.NEXTVAL FROM DUAL
ORACLE与SQLServer的自增列技术不同:后者用标识列来实现自增列,可以随着INSERT语句之后查询“批”执行而返回;前者使用表外的“序列”实现,只能先调用序列NEXTVAL自动产生,单独把其值查询回数据访问层,为下一步的INSERT做好准备。
再看接下来的ORACLE的PL-SQL语句,还是老办法分行、分段、加注释:
-- a. 开始一个PL-SQL语句块,注意BEGIN后面必须跟空白字符,至少一个空格
BEGIN
-- b. 插入订单主记录,共21个Command参数
INSERT INTO Orders VALUES(:OrderId, :UserId, :OrderDate, :ShipAddress1, :ShipAddress2,
:ShipCity, :ShipState, :ShipZip, :ShipCountry, :BillAddress1,
:BillAddress2, :BillCity, :BillState, :BillZip, :BillCountry, 'UPS',
:Total, :BillFirstName, :BillLastName, :ShipFirstName, :ShipLastName,
:AuthorizationNumber, 'US_en');
-- c. 插入订单状态记录
INSERT INTO OrderStatus VALUES(:OrderId, 0, sysdate, 'P');
-- d. 循环插入订单各细项
INSERT INTO LineItem VALUES(:OrderId0, :LineNumber0, :ItemId0, :Quantity0, :Price0);
INSERT INTO LineItem VALUES(:OrderId1, :LineNumber1, :ItemId1, :Quantity1, :Price1);
-- 省略 ...
INSERT INTO LineItem VALUES(:OrderIdN, :LineNumberN, :ItemIdN, :QuantityN, :PriceN);
-- e. 结束PL-SQL语句块
END;
MSPetShop V4把SQL语句组成为一个PL-SQL语句块,它本身就是一个事务。如果执行失败,C#的OracleClient会接收到异常,所以最后的C#主调代码不需要再自定义异常来抛出。
// Finally execute the query
OracleHelper.ExecuteNonQuery(conn, CommandType.Text, finalSQLQuery.ToString(), completeOrderParms);
到这里,我们都会认识到这两种DBMS在SQL语法有太多的不同,在严格业务的场景里都需要非常精致的写法。
(5)悲观SQL
假定一个银行信贷业务场景:一个简单数据表
create table bank (
Id int identity primary key,
Name nvarchar(50) not null,
Amount decimal default(0) not null,
LockFlag bit default(0) not null
)
包含这样的数据:[123, ‘张三’, 0.3]。表示一个叫张三的人在银行有0.1元钱。这就是那些频临销户状态的银行账户了。而你是信贷系统的操作员,在10:00分浏览账户列表数据,而现在是10:05分了,你已经看了5分钟。这期间那个张三透支了1000元,而你不知道刷新界面,导致看到的还是余额0.3元的数据。
这是领导过来对你说,把那些1元钱以下未透支的帐号锁定放到冷宫吧。于是你选择这个账户,点击系统界面上的锁定按钮,调用锁定功能,结果会如何呢?
推测一下,经常见到的Update、Delete语句是根据记录ID来干的,如果这里的修改语句是这样的:
update bank set LockFlag=1 where Id=123;
哈哈,那么这个操作结果就BUG了。
我要说的悲观SQL语句会这样写:
update bank set LockFlag=1 where Id=123 and ( Name=’张三’ or Name is null and @Name is null) and Amount=0.3 and LockFlag=@LockFlag
这条语句的where条件要求前端显示的数据与库内数据一致,就是没有其他人在此期间修改数据的情况才会执行数据更新。
在VS2003的Win Form界面上放一个DataAdapter,查看其自动生成的SQL语句,就是这种写法,到高版本VS中,悲观SQL成为了DataAdapter配置向导中的一个选项。
前面那种根据记录ID来直接修改或者删除数据的写法,就叫乐观SQL。其实它们都是根据悲观锁、乐观锁这些概念来的。呵呵。
三、最后
最后,本人提出一些问题,与大家共同思考。
(1)实际应用中的订单需求可能更加复杂一些!
例如:①要求支付成功后再减少库存来避免过早地锁定库存数量。②支付成功后还需要创建物流派送的工作任务。③订单有若干个状态:例如生成、支付成功、配送中等等,都需要自动化处理。
(2)MSPetShop V3/V4居然没有使用一个存储过程,为什么?
以下只是本人的推测:
①MSPetShop V3/V4没有使用存储过程,把SQL语句都集中到了数据访问层的相应方法里,显然比SQL语句在数据访问层与DMBS内两个地方都有要方便编写,也方便维护。我这几年来也比较喜欢这样做。
②MSPetShop V3/V4底层核心的SQL代码也不算多,没必要硬套存储过程。如果把订单生成改成存储过程,也是需要非常严格的写法的。而且订单细项数量的不可预测性也会给编码带来麻烦。
所以,本人并不是反对使用存储过程,而是反对滥用存储过程。MSPetShop V3/V4的汇总统计查询就比较简单,实际项目中本人喜欢在这方面使用存储过程,即方便组合查询逻辑,又方便单独维护啊。
OVER.