一、安装
cd conf/ cp flume-env.sh.template flume-env.sh vi flume-env.sh 添加 >>> JAVA_HOME=/opt/bigdata/java/jdk180
#flume export FLUME_HOME=/opt/bigdata/flume160 export PATH=$PATH:$FLUME_HOME/bin
[root@vbserver ~]# flume-ng version Flume 1.6.0-cdh5.14.2 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: 50436774fa1c7eaf0bd9c89ac6ee845695fbb687 Compiled by jenkins on Tue Mar 27 13:55:10 PDT 2018 From source with checksum 30217fe2b34097676ff5eabb51f4a11d
二、配置参数
见:https://www.cnblogs.com/yin-fei/p/10778719.html
官方:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-sources
三、简单使用
1.单个文件到HDFS
写一个flume.properties,建立/root/flume/data && /root/flume/checkpoint
vi flume.properties
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = exec a1.sources.r1.channels = c1 a1.sources.r1.command = tail -F /root/abc.log a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint # 需要已经存在 a1.channels.c1.dataDir = /root/flume/data # 需要已经存在 a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/events
2.执行命令
flume-ng agent --name a1 -f /root/flumetest/flume.properties
3.结果

2.实验1:用spooldir监听目录并输出多个文件
发现结果有10份,十行十events一个文件
如何指定目录中特定格式的文件? a1.sources.r1.includePattern= users_[0-9]{4}.csv
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /root/flumeData a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint a1.channels.c1.dataDirs = /root/flume/data a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/logs1 a1.sinks.k1.hdfs.fileType=DataStream
结果
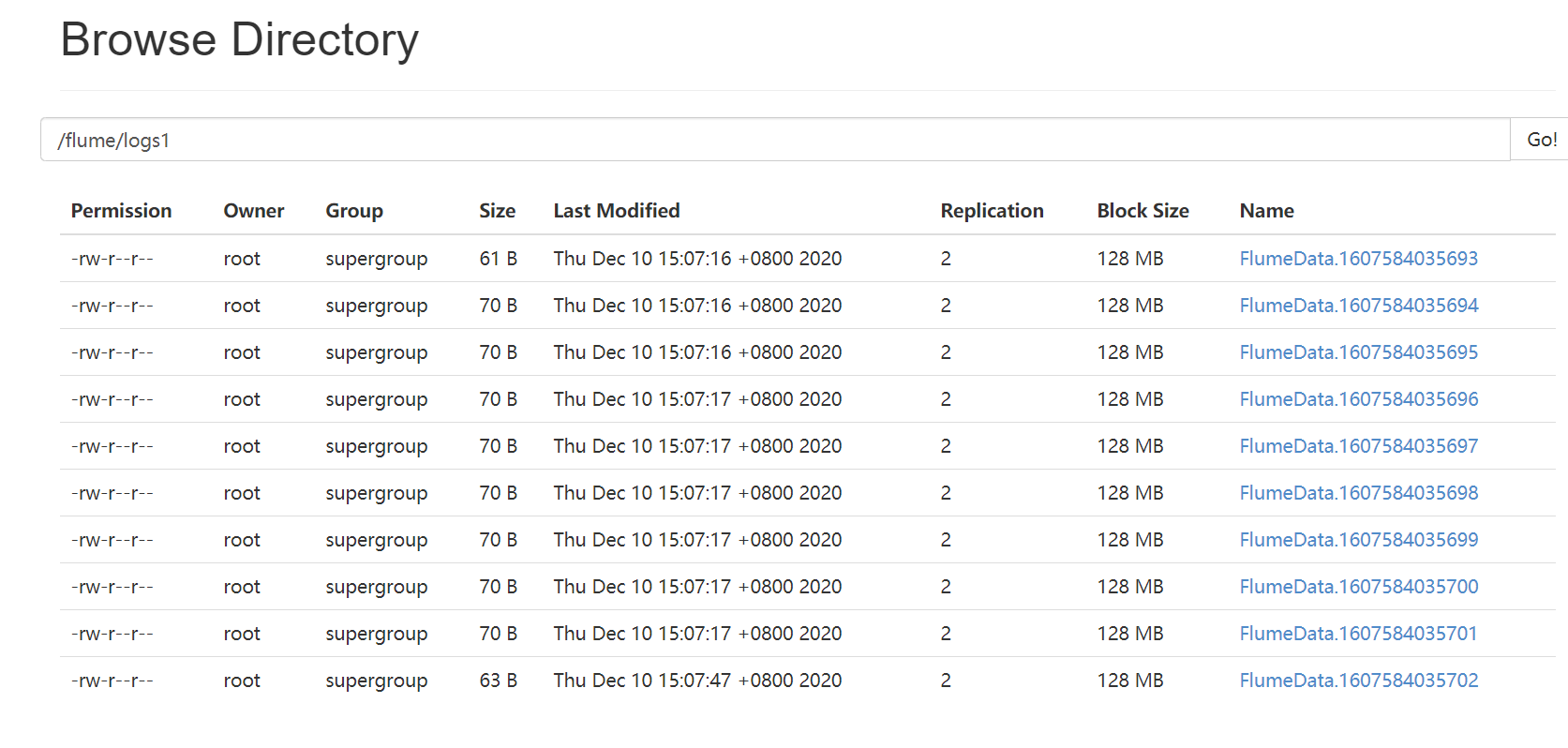
如果发现卡住,原因:

mv abc.log.COMPLETED abc.log
3.实验2:用spooldir监听目录并输出1个文件
rollcount=1000 => 1000条以下都是1个文件
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /root/flumeData a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint a1.channels.c1.dataDirs = /root/flume/data a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/logs3 a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.rollCount = 10000
结果

4.实验3:验证spooldir监听目录的作用:新增新log
hdfs dfs -cat /flume/logs3/*
查看hdfs结果:abc.log中所有文件(从test1-test99)
查看监听目录:abc标记为completed
[root@vbserver flumeData]# ls abc.log.COMPLETED
新建log:cde.log(写有c1-c4)
[root@vbserver flumeData]# ls abc.log.COMPLETED cde.log
再次执行命令:
flume-ng agent --name a1 -f /root/flumetest/flume.properties
查看hdfs结果:
(test1-test99 c1-c4)
5.改进:上传HDFS合成一个文件
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /root/flumeData a1.sources.r1.batchSize = 10000 a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint a1.channels.c1.dataDirs = /root/flume/data a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/logs4 a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.rollCount = 0 #设置文件的生成和events数无关 a1.sinks.k1.hdfs.rollSize = 10485760 #1024 * 10 * 1024 = 10G a1.sinks.k1.hdfs.rollInterval = 60 #每60秒生成一个文件 a1.sinks.k1.hdfs.useLocalTimeStamp = true #使用本地时间戳,如:用来命名文件

5.输出到Kafka,每一行是一个小消息!
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /root/flumeData a1.sources.r1.batchSize = 10000 a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint a1.channels.c1.dataDirs = /root/flume/data a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = mytopic # 可以原来没这个topic,能自动生成 a1.sinks.k1.kafka.bootstrap.servers = 192.168.56.111:9092 a1.sinks.k1.kafka.flumeBatchSize = 100 a1.sinks.k1.kafka.producer.acks = 1
启动kafka后,实时验证:
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mytopic // 实时消费
执行命令:
flume-ng agent --name a1 -f /root/flumetest/flume.properties
结果:
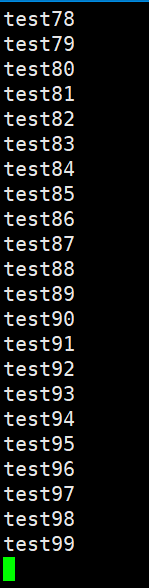
6.使用拦截器给csv去头
a1.channels = c1 a1.sources = r1 a1.sinks = k1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /root/flumeData a1.sources.r1.batchSize = 10000 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=regex_filter a1.sources.r1.interceptors.i1.regex = user_id.* # 第一行是user_id开头 a1.sources.r1.interceptors.i1.excludeEvents=true # exclude 匹配上的
a1.channels.c1.type = file a1.channels.c1.checkpointDir = /root/flume/checkpoint a1.channels.c1.dataDirs = /root/flume/data a1.sinks.k1.channel = c1 a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = users # users.csv => users这个topic a1.sinks.k1.kafka.bootstrap.servers = 192.168.56.111:9092 a1.sinks.k1.kafka.flumeBatchSize = 100 a1.sinks.k1.kafka.producer.acks = 1
比对传输前后的条数:
[root@vbserver flumeData]# wc -l users.csv 38210 users.csv
开启kafka实时消费:
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic users // 实时消费
执行命令:
flume-ng agent --name a1 -f /root/flumetest/flume.properties
结果:
Processed a total of 38209 messages # csv去头成功!
四、问题汇总
1.GC OOM
Flume安装目录下bin
vi flume-ng
解决方法: 改大 JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
2.传入KFK后消息行数翻倍
原因:单行超过最大length会截断,另起下一行 => 所以kfk的消息数会变大!

解决方法: a1.sources.r1.deserializer.maxLineLength=1200000
3.Topic xxx does not exist on ZK path xxxx
kfk的topic删除后 => kfk 和zk关于该topic的信息都灭
但是flume没有关,发现没有传输成功,便又开始传输 => 所以查看kfk的topic时会出现报错
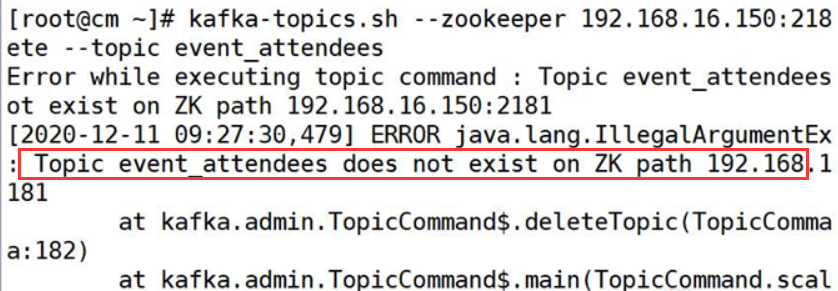
解决方法:先停flume,再delete kfk的topic
4.上游下游都卡住没动
检查一下spoolDir目录下是否所有文件都COMPLETED