- Apache Kafka 架构介绍
- Kafka Components
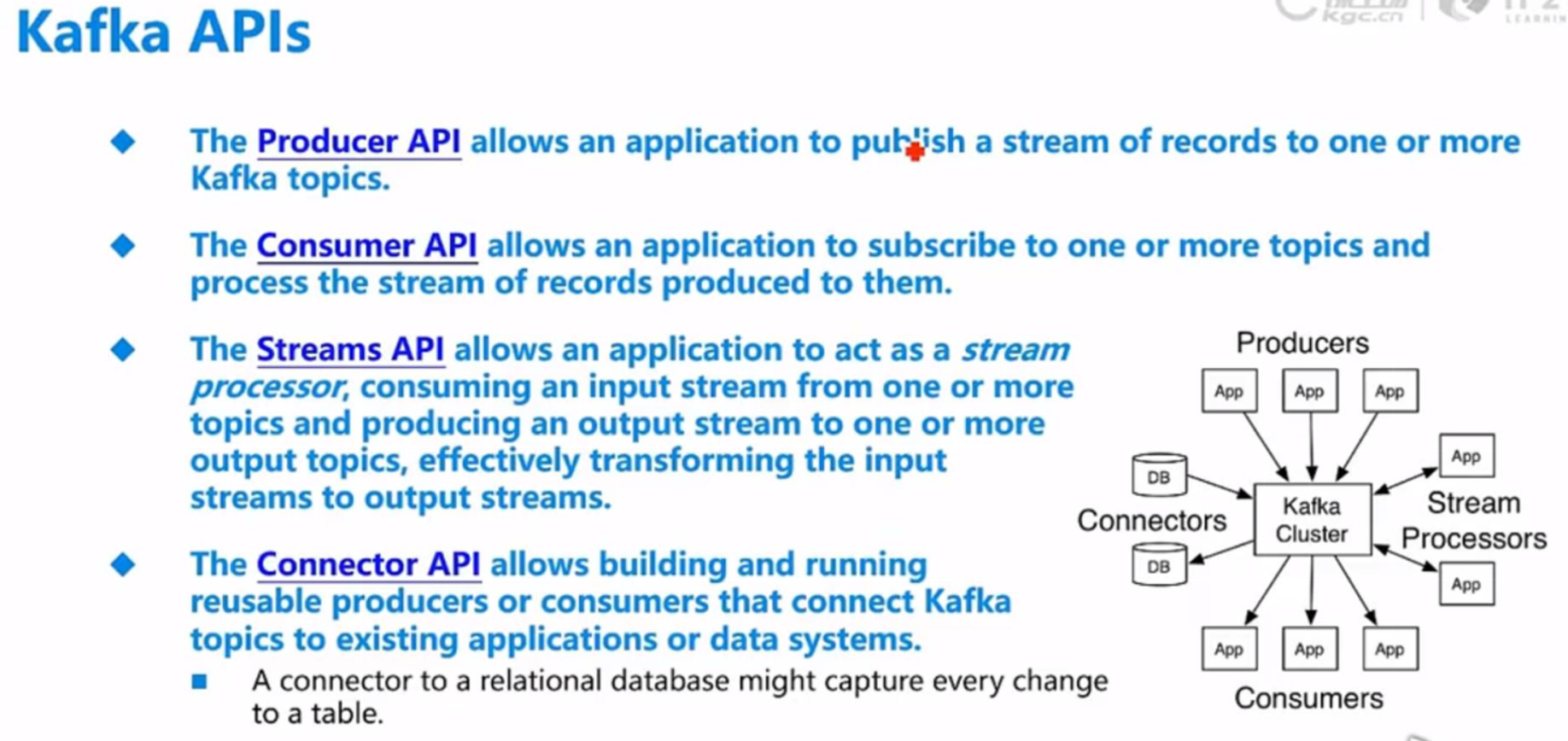
- Apache Kafka API介绍
- Apache Kafka Performance
- Kafka Producer和Consumer
一、架构介绍
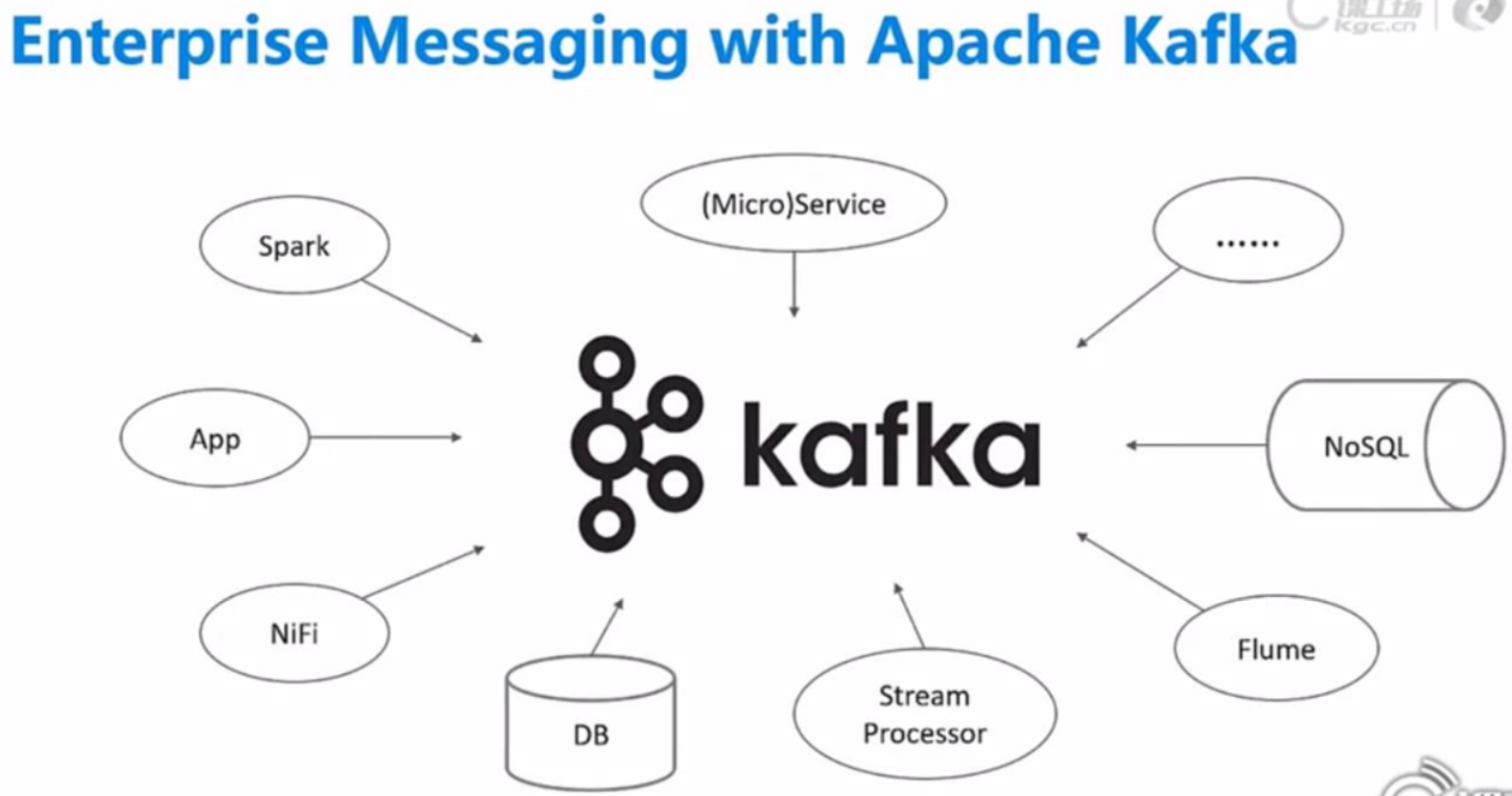
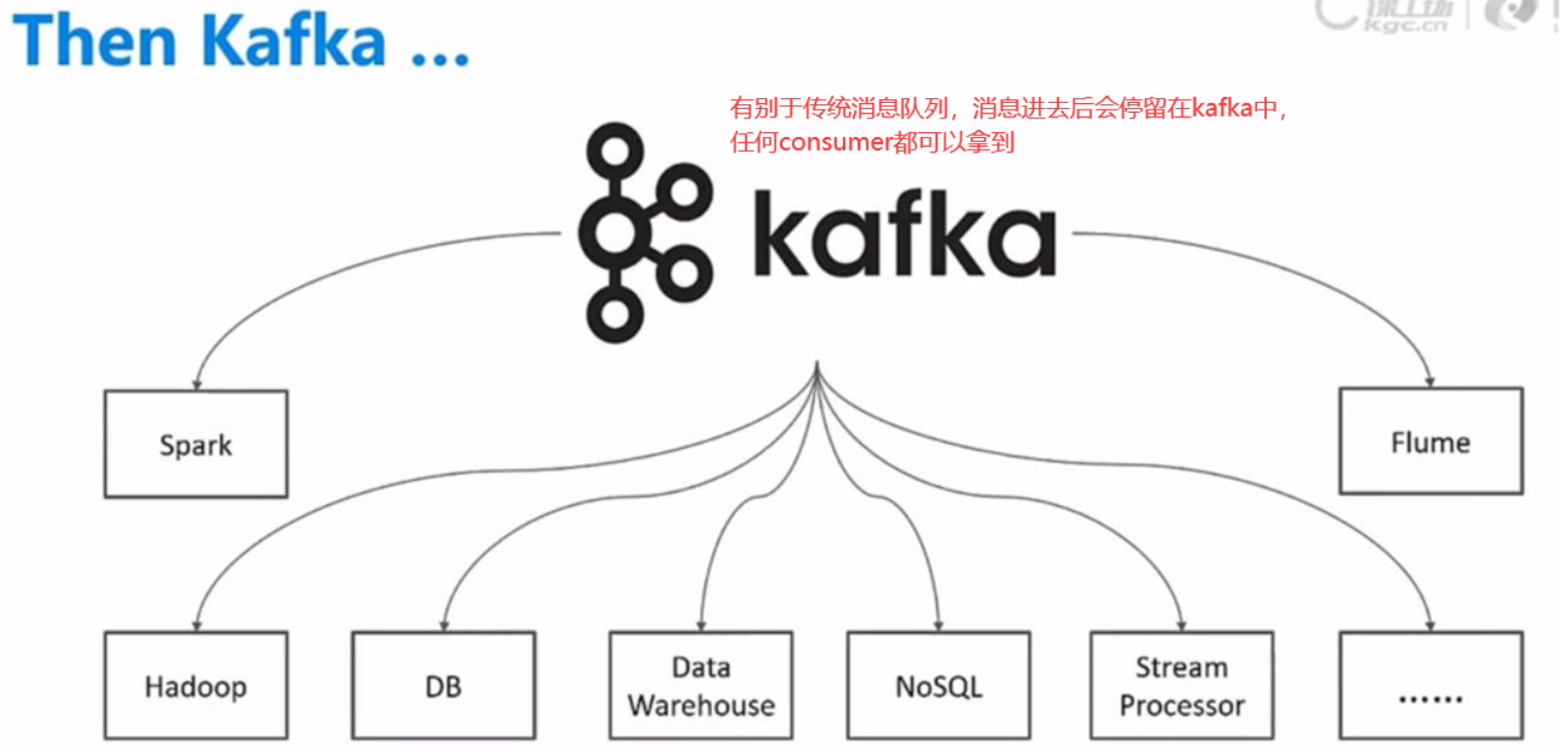



二、KFK特性

三、KFK组件
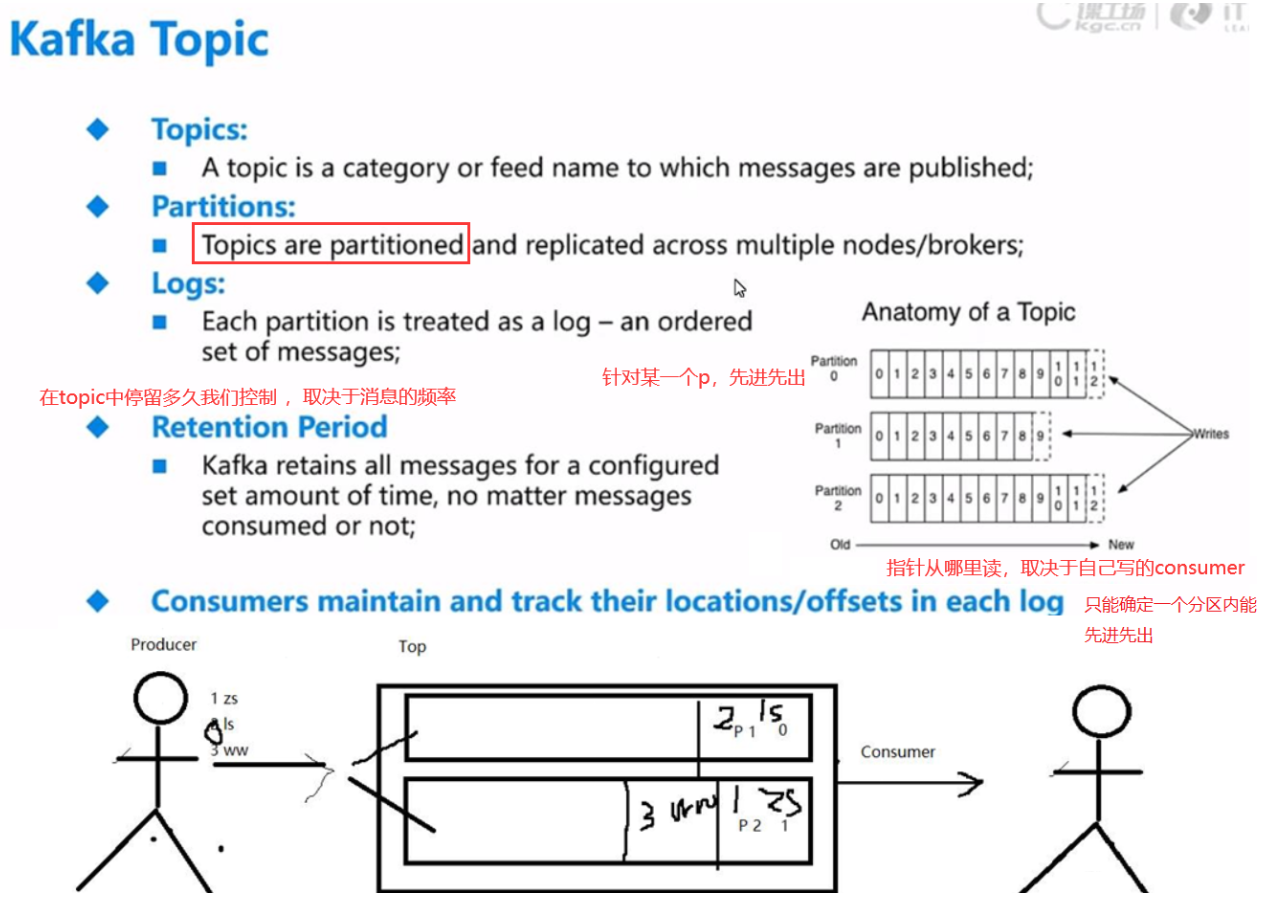
(1)逻辑层面:Topic
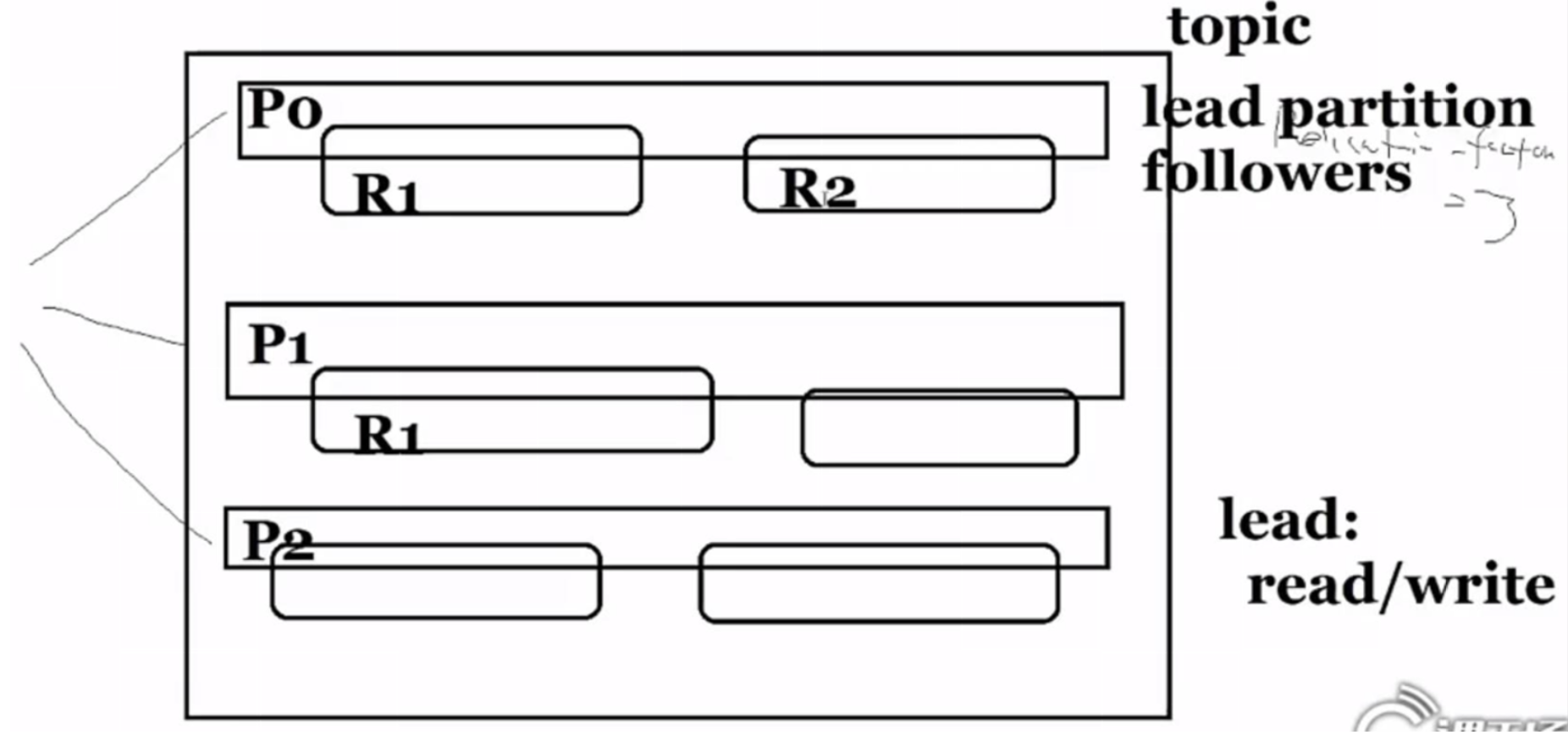
(2-1)物理层面:Broker(节点)



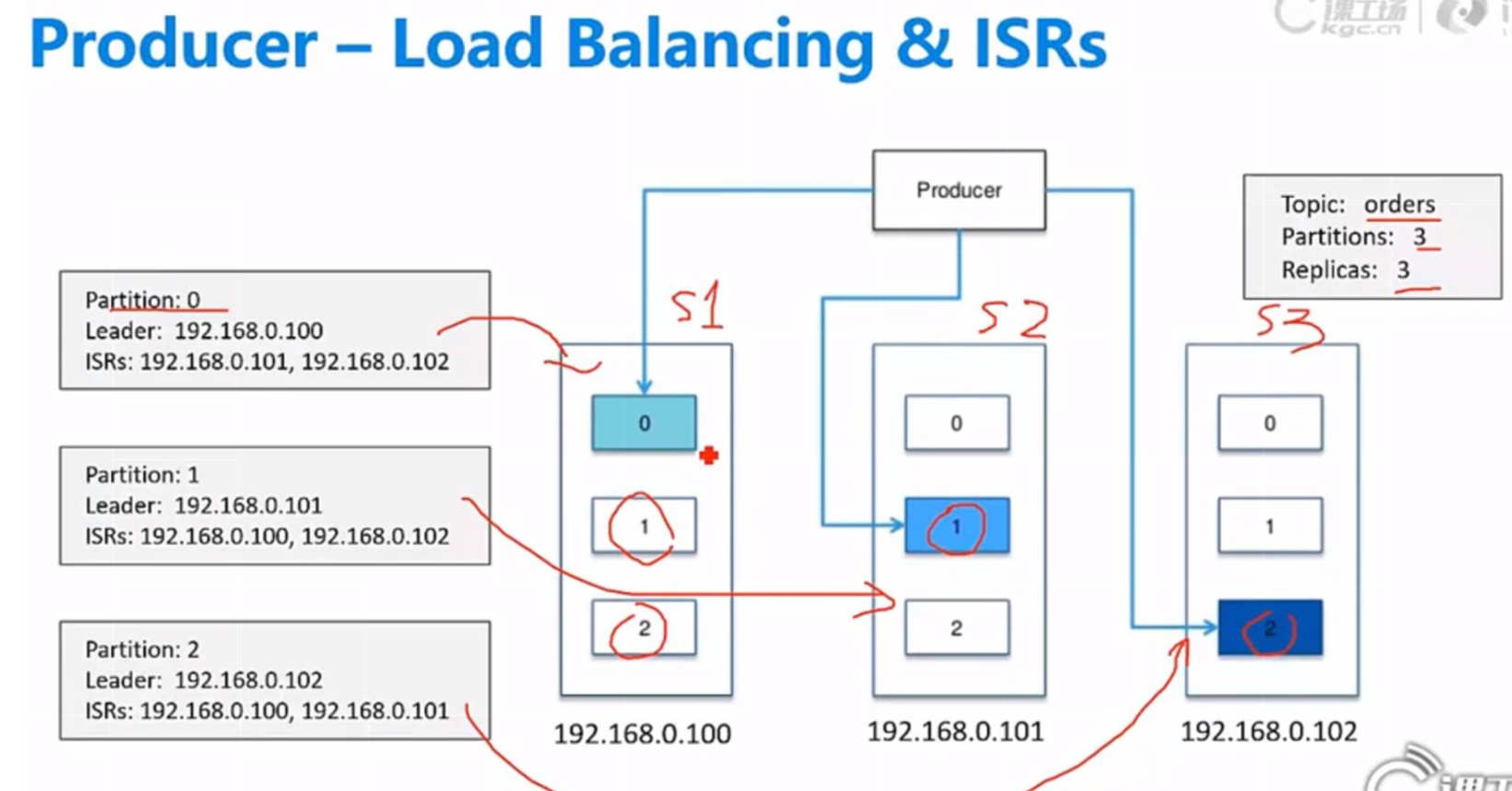
(2-2)物理层面:Producer

每一个partiiton都需要有1个lead server保证数据存储,还可以有一个isr同步备份集合(server2,server3),剩下的follows是异步的,不能保证有没有

request.required.acks = -1 表示生产者发送消息要等到 leader 以及所有的副本都同步了,才会返回确认消息。当然,这种方案也不是非常万无一失的,官方提出的建议是,还需要配置 min.insync.replicas 最小同步的副本数,如果没有得到这个最小数的要求,生产者会抛出异常,本次写入不会成功。
request.required.acks = -1 虽然保证了数据的一致性,但是同时也影响了性能。在实际业务中应该考虑数据少量丢失对于业务的影响,要根据自己的情况来,结合业务来平衡数据一致性和系统的性能。
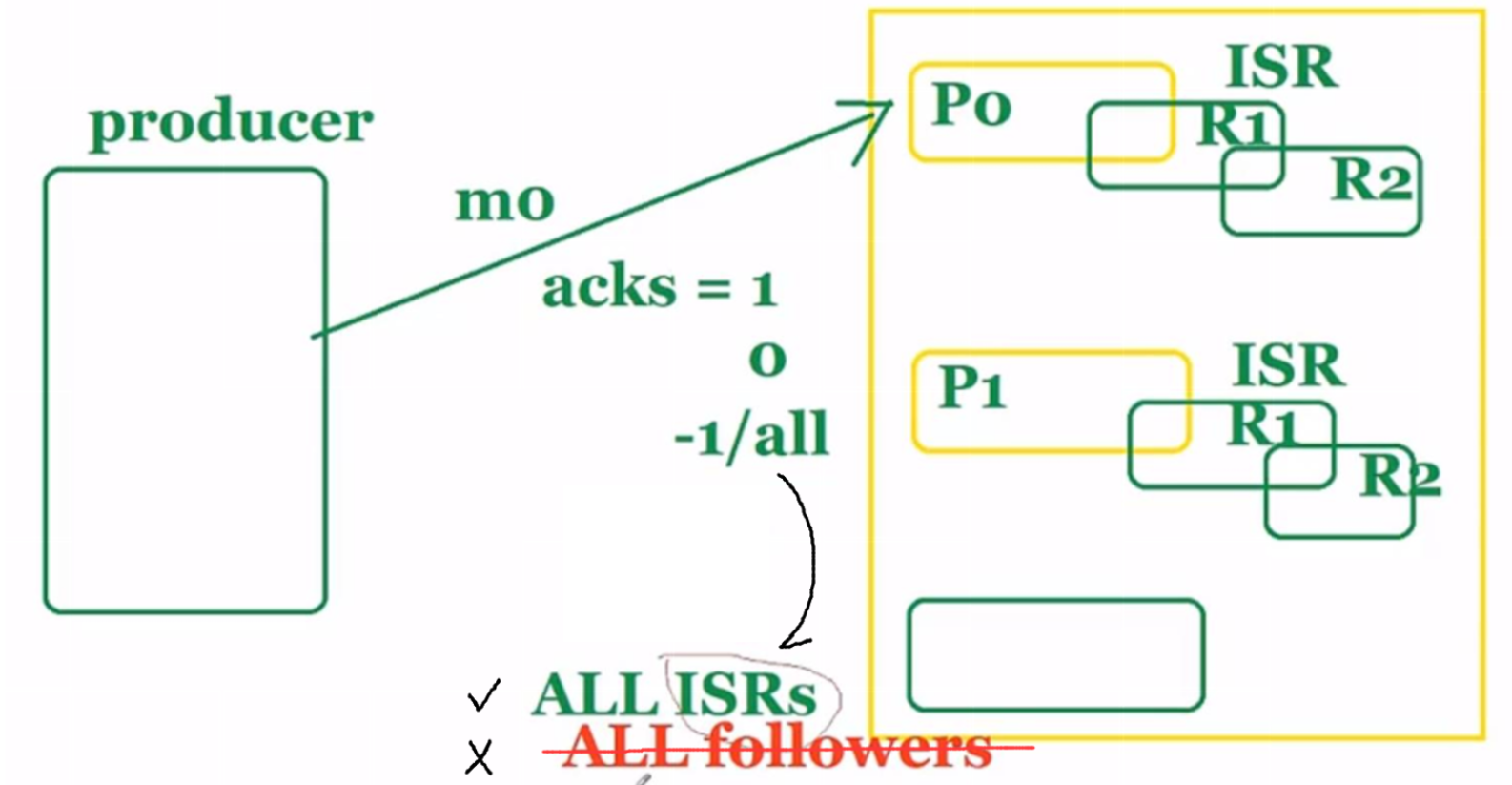
关于ack和最小同步副本,见:https://blog.csdn.net/qq_38704184/article/details/107406294
(2-3)物理层面:Consumer
一个Consumer Group一个指针



(3)管理者:zookeeper

四、kfk APIs
五、Data Loss & Data Duplication
(1) Data Loss
生产端
设置 flush 的时间,不能从根本上保证我们的数据丢失问题。
request.required.acks = -1 虽然保证了数据的一致性,但是同时也影响了性能,应该根据业务平衡一致性和性能。

节点端
至少需要一个isr(同步)存活保证数据,没有isr全是异步容易丢失数据

数据是否丢失与宕机的是不是leader,是不是ISR,存活ISR数量,是否允许unclean election 有关系
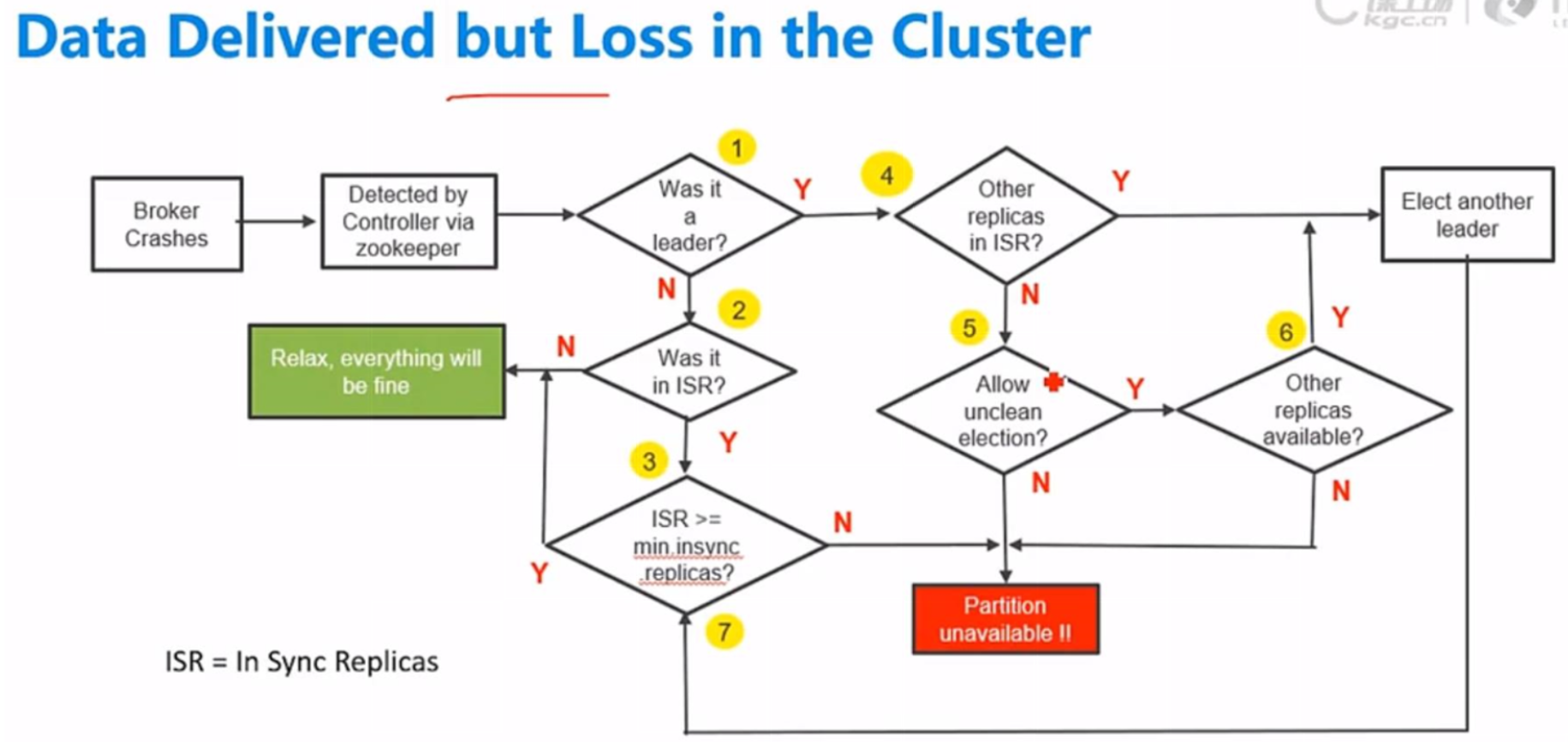
unclean election: 是否允许非ISR节点参与leader选举
存在ISR数量 >=min insync replicas,否则抛错
消费端

就消费者而言,只要收到消息,就会被“处理”。所以现在想象一下,你的消费者已经吸收了1000条消息并将它们缓存到内存中。然后自动提交触发,提交这1,000条消息的偏移量。但是,假设您的服务现在使用了太多内存,并且在处理完所有消息之前会被OOM终止信号强行关闭。这样就永远不会处理剩余的可能是数百条消息,这就是【数据丢失】
相反的情况也是可能的。您可以成功处理这1,000条消息,然后在提交偏移量之前发生问题如硬件故障等。在这种情况下,您将在 消费者重新平衡 后重新处理另一个实例上的数百条消息,这就是【数据重复】
(2) Data Duplication
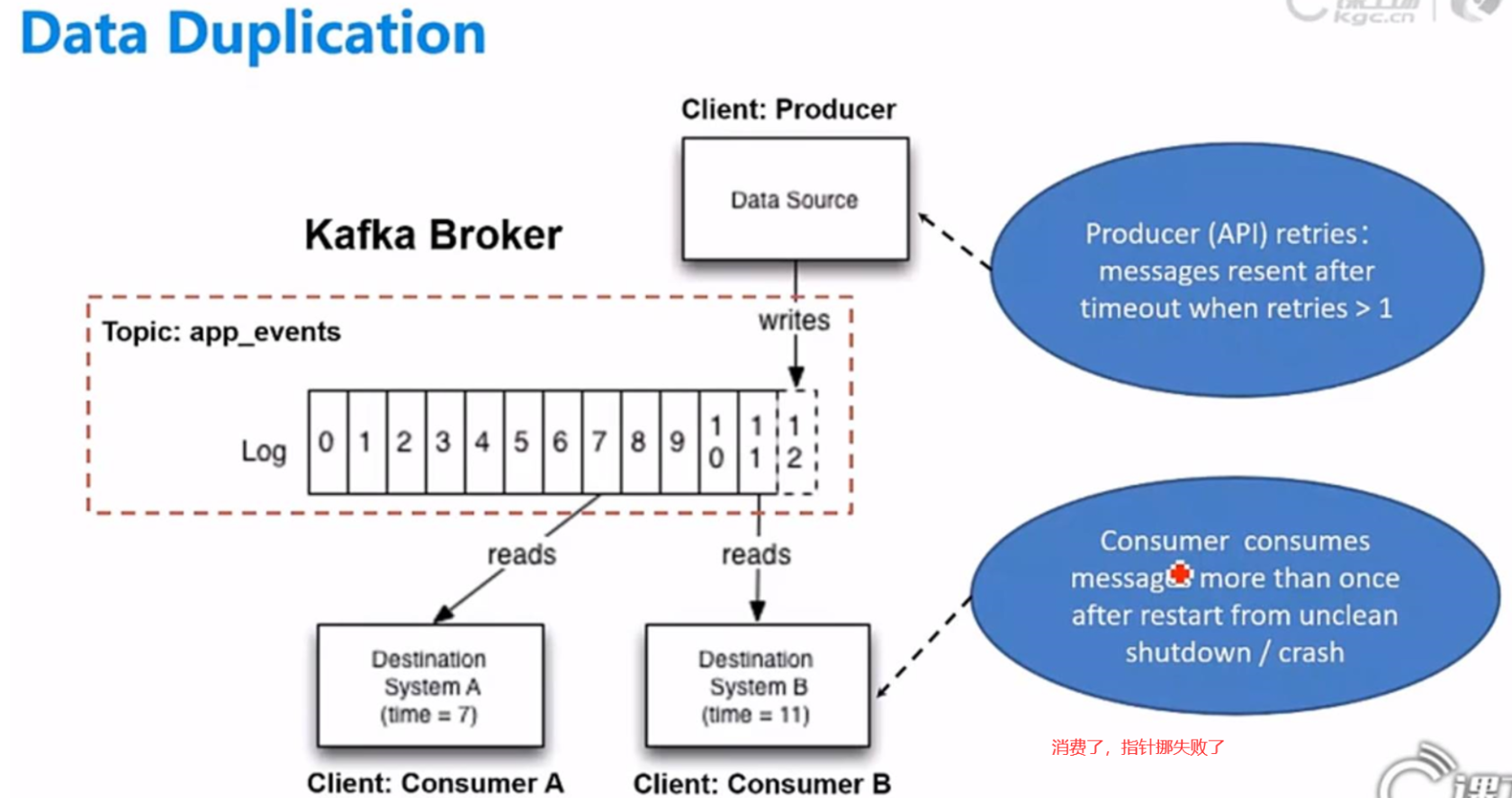
问题1解决:幂等:一次操作和很多次操作效果一样
① 生产者幂等性实现:PID和Sequence Number
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。 PID:每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是 不可见的。
Sequence Numbler:(对于每个PID,该Producer发送数据的每个<Topic, Partition> 都对应一个从0开始单调递增的Sequence Number。
Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号大于Broker 缓存中序号则接受它,否则将其丢弃。这样就可以避免消息重复提交了。
但是,只能保证单个Producer对于同一个<Topic, Partition>的Exactly Once语义。不能保证同一个Producer一个topic不同的partion幂等。
问题2解决:
① 消费者幂等处理:
1.将消息的offset存在消费者应用中或者第三方存储的地方
可以将这个数据存放在redis或者是内存中,消费消息时,如果有这条数据的话,就不会去做后续操作
2.数据落库的时候,根据主键去过滤
在落库时,如果不不在这条数据,则去新增,如果存在则去修改
② 如果不能幂等处理,则将consumer的提交方式设置为同步提交,是最大程度地保证一致性的方法,缺点是性能会降低很多。
六、KFK使用场景

