关于http协议已经有很多大牛们的讨论,从他们的文章中获益匪浅,作为一个通信专业的学生,还是想从计算机网络的角度谈一下自己的认识。http协议全称超文本传输协议,是一种允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器的一种通信协议。计算机网络的层次模型主要有OSI参考模型和TCP/IP参考模型,现在被广泛应用的是TCP/IP参考模型,不同OSI模型将网络分成7层,TCP/IP将网络分成4层。如下图:
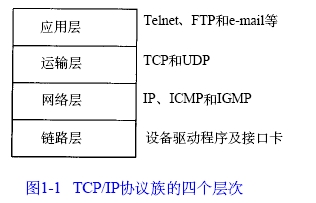 |
http协议即是应用在应用层的 它是一个简单的请求-响应协议, 通常运行在TCP上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII码形式给出,而消息内容则具有一个类似MIME的格式。 虽然HTTP是一个应用层协议,但它变得越来越像一个传输层协议,因为它为进程之间跨越不同网络进行内容通信提供了一种方式,这些进程不一定必须是Web浏览器和Web服务器。媒体播放器也可以使用HTTP于服务器通信并请求专辑信息,防病毒软件可以使用它来下载更新病毒库,机器与机器之间的通信越来越多的通过HTTP进行。HTTP虽然最初是为Web而设计,但不可置疑的是它的使用正在一步步扩大。(这里我们的讨论就以Web中的HTTP为主) |
连接
我们知道http协议是无状态的,所谓的无状态即是无记忆,同一客户端的多次请求在服务器看来和多个客户端的请求是一样的,彼此直接不会有什么关系。那我们是怎么打开一个网页的呢?浏览器会分批向服务器发送请求,浏览器每发送一个请求Request,服务器会相应返回一个Response,浏览器针对服务器的Response进行分析,看看自己还需要什么东西,然后再次向服务器发送Request,服务器根据Request返回Response,l=浏览器继续分析自己的需求,然后重复以上步骤直到网页中html,图片,css,js等相关文件相继加载完毕。然后我们就看到了完整的网页。如果这期间出现什么差错,服务器会返回响应的值:
| 代码 | 含义 | 例子 |
| 1xx | 信息 | 100=服务器同意处理客户请求 |
| 2xx | 成功 | 200=请求成功;204=没有内容 |
| 3xx | 重定向 | 301=移动页面;304=缓存的页面仍然有效 |
| 4xx | 客户错误 | 403=禁止页面;404=页面没有找到 |
| 5xx | 服务器错误 | 500=服务器内部错误;503=稍后再试 |
方法
http不仅支持请求一个Web页面,而且支持操作(称为方法)。每个请求由一行或多行ASCII文本组成,其中第一行的第一个词是被请求的方法的名字。方法名字区分大小写,详情见下表
| 方法 | 描述 |
| GET | 读取一个Web界面 |
| HEAD | 读取一个Web页面的头 |
| POST | 附加一个Web页面 |
| PUT | 存储一个Web页面 |
| DELETE | 删除一个Web页面 |
| TRACE | 回应入境请求 |
| CONNECT | 通过代理连接 |
| OPTIONS | 一个页面的查询选项 |
GET和POST的区别:
1GET方法用于请求服务器发送页面(对象),即获取/查询资源信息,POST用于更新资源信息(提交表单等)。
2GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,POST方法是把提交的数据放在HTTP包的Body中
3基于2的信息,所以GET方式提交的数据会带来安全问题,比如登录一个页面,使用GET登录信息就会出现在URL之中,如果页面被缓存的话或者其他人再使用相同电脑时都是很容易获取的(目测黑客应该是这方面的高手)
4数据大小方面,因为浏览器对URL的长度是有限制的,所以GET提交的数据大小也是有限制的。POST则不然。
5获取变量值时GET使用Request.QueryString,POST使用Request.Form来获取变量的值。
消息头
请求行(例如GET方法的行)后面可能有可能还有额外的行,其中包含了更多的信息,他们统称为请求头。每个请求和响应通常具有不同的头,现就常用的头做一下解释说明
| 头 | 类型 | 内容 |
| User-Agent | 请求 | 有关浏览器及其平台的信息 |
| Accept | 请求 | 客户可处理的页面类型 |
| Host | 请求 | 服务器的DNS名字 |
| Cookie | 请求 | 给服务器发回Cookie的先前请求 |
| Set-Cookie | 响应 | 客户存储的Cookie |
| Expires | 响应 | 页面(Cookie)不再有效的时间和日期 |
| Location | 响应 | 告诉客户向谁发送请求 |
| Date | 请求/响应 | 发送消息的日期和时间 |
| Cache-Control | 请求/响应 | 指示如何处理缓存 |
缓存
关于缓存大家肯定不陌生,前面就说过缓存可能导致信息安全问题,不过没有缓存将会造成更大的影响。积攒已经获取的网页供日后使用的处理方式称为缓存,优点是当缓存的页面被重复使用时,没有必要进行重复传输,这种协议中内置的支撑,能够帮助客户标识他们何时可以放心的重用页面。并且减少网络的流量和延迟,这些缓存通常被保存在本地磁盘上,即安全又方便成本还低廉。
------本博客参考书为:《计算机网络第5版 清华大学出版社》--------