分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性。目前比较常用的分布式事务解决方案包括强一致性的两阶段提交协议、三阶段提交协议以及最终一致性的可靠事件模式、补偿模式、阿里的TCC模式。
事务是指由一组操作组成的一个工作单元,这个工作单元具有原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。 原子性:执行单元中的操作要么全部执行成功,要么全部失败。如果有一部分成功一部分失败那么成功的操作要全部回滚到执行前的状态。 一致性:执行一次事务会使用数据从一个正确的状态转换到另一个正确的状态,执行前后数据都是完整的。
隔离性:在该事务执行的过程中,任何数据的改变只存在于该事务之中,对外界没有影响,事务与事务之间是完全的隔离的。只有事务提交后其它事务才可以查询到最新的数据。 持久性:事务完成后对数据的改变会永久性的存储起来,即使发生断电宕机数据依然在。
强一致性
两阶段提交协议
在分布式系统中,为了解决多个节点之间的协调问题,就需要引入一个协调者负责控制所有节点的操作结果,要么全部成功,要么全部失败。其中,XA协议是一个分布式事务协议,它有两个角色:事务管理者和资源管理者。我们可用把事务管理者理解为协调者,资源管理者理解为参与者。XA协议通过二阶段提交协议保证强一致性:
第一阶段准备:事务管理者向资源管理者发起准备指令,询问资源管理者预提交是否成功;资源管理者执行操作,并不提交,最后给出自己的响应结果
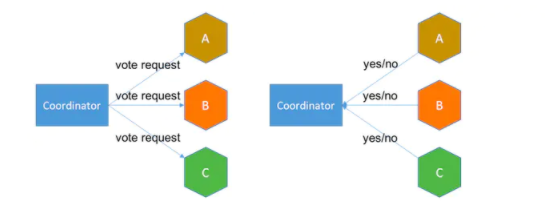
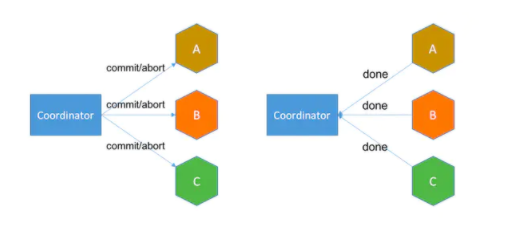
第二阶段提交:如果全部资源管理者都回复预提交成功,事务管理者则发起正式提交命令;如果其中一个资源管理者回复预提交失败,事务管理者则发起全部回滚命令
二阶段提交协议的缺点
- 同步阻塞问题:执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
- 单点故障:由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
- 数据不一致:在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
三阶段提交协议
三阶段提交协议与二阶段的不同之处在于引入了超时机制来解决同步阻塞问题,此外加入预备阶段,尽可能最早发现无法执行的资源管理者并终止事务。
最终一致性
TCC模式
TCC模式将一个任务拆分为3个操作:Try、Confirm和Cancel。在TCC模式中,主业务服务负责发起流程,而从业务服务提供TCC模式的Try、Confirm和Cancel三个操作,还有一个事务管理器的角色负责控制事务的一致性。事实上,TCC模式也是一种二阶段提交。

用户接入TCC,最重要的是考虑如何将自己的业务模型拆成两阶段来实现。
例如:账户业务服务,将业务划分为资源(余额)检查与预留阶段 与 执行扣款或回滚阶段。
-
Try 方法作为一阶段准备方法(做资源的检查和预留)
- 在扣钱场景下,Try 要做的事情是就是检查账户余额是否充足,预留转账资金,预留的方式就是冻结 A 账户的 转账资金。
- Try 方法执行之后,账号 A 余额虽然还是 100,但是**其中 10 元已经被冻结了,不能被其他事务使用**。
二阶段 Confirm 方法(执行真正的扣钱操作)
-
Confirm 会使用 Try 阶段冻结的资金,执行账号扣款。Confirm 方法执行之后,账号 A 在一阶段中冻结的 10 元已经被扣除,账号 A 余额变成 70 元 。
-
如果二阶段是回滚的话,就需要在 Cancel 方法内释放一阶段 Try 冻结的 10 元,使账号 A 的回到初始状态,100 元全部可用
需要注意的是,第二阶段 confirm 或 cancel 操作本身也是满足最终一致性的过程,在调用 confirm 或 cancel 的时候也可能因为某种原因(比如网络)导致调用失败,所以需要活动管理支持重试的能力,同时这也就要求 confirm 和 cancel 操作具有幂等性(所谓幂等,就是任意多次执行所产生的影响均与一次执行的影响相同)。如果业务服务向 TCC 服务框架提交confirm/cancel 失败,不会导致不一致,因为服务最后都会超时而取消。TCC的实现框架有很多成熟的开源项目,比如tcc-transaction。它通过@Compensable切面进行拦截,可以透明化对参与者confirm/cancel方法的调用,从而实现TCC模式
补偿模式
除了重试机制,还可以在每次更新时进行修复。定时校对也是一种重要的解决手段。业内比较常用的有单机场景下的Quartz以及分布式场景下的XXL-JOB等。
可靠事件模式
可靠事件模式是指通过引入可靠的消息队列,只要保证当前的可靠事件投递并且消息队列确保事件传递至少一次,那么订阅这个事件的消费者保证事件能够在自己的业务内被消费即可。但是在网络通信过程中,上下游可能因为各种原因而导致消息丢失。因此,需要通过“正反向消息机制”确保消息队列实现可靠的事件传递,并且使用补偿机制尽可能在一定时间内将未完成的消息重新投递。
一般做法,是主业务服务将要发送的消息持久化到本地数据库中,设置标志状态为“待发送”;然后把消息发送给消息队列,消息队列收到消息后,也把消息持久化到其存储服务中,但并不是立即向从业务服务(生产者)投递消息,而是先向主业务服务(生产者)返回消息队列的响应结果,然后主业务服务判断响应结果执行之后的业务处理。如果响应失败,则放弃之后的业务处理,设置本地的持久化消息标志状态为“结束”状态。否则,执行后续的业务处理,设置本地的持久化消息标志状态为“已发送"状态。
Apache RockerMQ
Apache RockerMQ是阿里开源的分布式消息中间件,4.3版本正式支持分布式事务消息。RockerMQ事务消息中间件解决了生产者端的消息发送与本地事务执行的原子性问题。 换句话说,本地事务执行不成功,则不会进行MQ消息推送。

MQ消息、DB操作一致性方案:
1)发送消息到MQ服务器,此时消息状态为SEND_OK。此消息为consumer不可见。
2)执行DB操作;DB执行成功Commit DB操作,DB执行失败Rollback DB操作。
3)如果DB执行成功,回复MQ服务器,将状态为COMMIT_MESSAGE;如果DB执行失败,回复MQ服务器,将状态改为ROLLBACK_MESSAGE。注意此过程有可能失败。
4)MQ内部提供一个名为“事务状态服务”的服务,此服务会检查事务消息的状态,如果发现消息未COMMIT,则通过Producer启动时注册的TransactionCheckListener来回调业务系统,业务系统在checkLocalTransactionState方法中检查DB事务状态,如果成功,则回复COMMIT_MESSAGE,否则回复ROLLBACK_MESSAGE