采用微服务架构后,当分布式系统到达一定量级时,每个环境都可能出错,因此在系统设计时应该考虑如何减轻故障的影响,如何从故障中快速恢复。一般从以下两点来考察系统的稳定性:
- 高可用:当前服务依赖的下游服务性能降低或者失败时,该服务怎么相应,是快速失败还是重试?大促时如何应对瞬间涌入的流量?
- 高并发:底层服务如何保证服务的吞吐量?如何提高消费者的处理速度?
高可用
限流
限流算法
计数器法:该算法维护一个counter,规定在单位时间内counter的大小不能超过最大值,每隔固定时间就将counter的值置为零。
漏桶算法:水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出(拒绝服务),可以看出漏桶算法能强行限制数据的传输速率
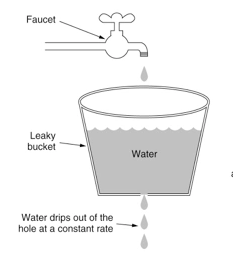
令牌桶算法:一个存放固定容量令牌的桶,按照固定速率(每秒/或者可以自定义时间)往桶里添加令牌,然后每次获取一个令牌,当桶里没有令牌可取时,则拒绝服务。令牌桶分为2个动作,动作1(固定速率往桶中存入令牌)、动作2(客户端如果想访问请求,先从桶中获取token)
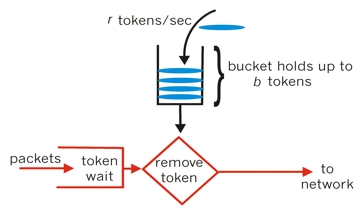
限流实践
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法(Token Bucket)来完成限流,非常易于使用.RateLimiter经常用于限制对一些物理资源或者逻辑资源的访问速率.它支持两种获取permits接口,一种是如果拿不到立刻返回false,一种会阻塞等待一段时间看能不能拿到.
RateLimiter设计思路:RateLimiter的主要功能就是通过限制请求流入的速度来提高稳定的服务速度。实现QPS速率的最简单的方式就是记住上一次请求的最后授权时间,然后保证1/QPS秒内不允许请求进入.比如QPS=5,如果我们保证最后一个被授权请求之后的200ms的时间内没有请求被授权,那么我们就达到了预期的速率.如果一个请求现在过来但是最后一个被授权请求是在100ms之前,那么我们就要求当前这个请求等待100ms.按照这个思路,请求15个新令牌(许可证)就需要3秒。如果RateLimiter的一个被授权请求之前很长一段时间没有被使用会怎么样?这个RateLimiter会立马忘记过去这一段时间的利用不足,而只记得刚刚的请求。
断路器
Hystrix[hɪst'rɪks]由Netflix开源的一个延迟和容错库,用于隔离访问远程系统、服务或者第三方库,防止级联失败,从而提升系统的可用性、容错性与局部应用的弹性,是一个实现了超时机制和断路器模式的工具类库。
Hystrix主要提供4个功能:断路器、隔离机制、请求聚合和请求缓存。
- 断路器(Circuit breaker)
Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN).
- 隔离机制(Bulkheads)
线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃该类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
- 请求聚合
使用HystrixCollapser将前端的多个请求聚合成为一个请求发送到后端
- 请求缓存
HystrixCommand和HystrixObservableCommand实现了对请求的缓存,假如在某个上下文中有多个同时到达的相同参数的查询,利用请求缓存功能,可以减少对后端系统的压力。
超时与重试
在微服务系统中,如果上游应用没有设置合理的超时和重试机制,则会造成请求响应变慢,慢请求会积压并耗尽系统资源。超时机制应该和限流、断路器配合使用,最终实现微服务系统的稳定性。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
高并发
几种常见的高并发策略如下:
- 异步:提高业务过程中可异步部分的占比,提高异步部分的执行效率
- 缓存:将频繁访问的数据存储在离业务处理逻辑更近的地方
- 池化:对于创建起来比较消耗资源的对象进行缓存
异步
按照异步操作出现的位置,可用分为两类:在JVM内部,使用异步线程池或者异步回调机制;在JVM外部,可用使用消息队列、Redis队列等中间件
异步线程池
Java中可用通过Executors和ThreadPoolExecutor方式创建线程池,通过Executors可用快速创建四种常见的线程池,但这种方式在实际使用中并不推荐,因为这种方式创建出来的线程池的可控性较差(FixedThreadPool和SingleThreadPool:允许的请求队列长度为Integer.MAX_VALUE,可能对堆积大量请求,从而导致OOM;CacheThreadPool和ScheduledThreadPool:允许创建线程数量为Integer.MAX_VALUE,可能创建大量线程,从而导致OOM)。而通过ThreadPoolExecutor的方式去创建,可用让开发人员更明确线程池的运行规则,避免资源耗尽的风险。同时可用实现自定义的拒绝策略,从而打印告警日志,并根据日志监控线程池的运行情况,在发生异常时及时处理。
异步回调机制
异步回调与同步调用的不同之处在于,请求发起方不需要等待服务方的响应返回,可用先去做别的业务。接口请求返回后会自动调用预先定义的回调函数,进行后续的业务处理。
消息队列
消息队列是系统架构层面的异步策略,应用场景很广泛,如削峰填谷。典型应用就是优惠券发放和电商秒杀系统
缓存
在分布式系统中,缓存无处不在。从缓存静态资源的CDN,到缓存http请求的nginx,从浏览器或App客户端的缓存,到服务端到数据存储的缓存,不一而足。常见的分布式缓存中间件有Redis、Memcache等。在分布式系统中使用缓存时,还需要处理好缓存穿透、缓存雪崩、大value缓存监测、热点缓存等问题。
缓存穿透:一般的缓存系统都是按照key去缓存查询的,如果不存在则去后端系统查找。如果key对应的value一定不存在,并且对该key的并发请求量很大,就会对后端系统造成很大的压力。
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段消失,在消失的这段时间,也会对后端系统带来很大压力