程序设计层第6、7章读书笔记
第6章 低级程序设计语言与伪代码
6.1 计算机操作
- 计算机是能够存储、检索和处理数据的可编程电子设备。
- 要改变计算机对数据的处理,只需要改变指令即可。
- 存储、检索和处理是计算机能够对数据执行的动作。
6.2 机器语言
- 计算机真正执行的程序设计指令是用机器语言编写的指令,这些指令固定在计算机的 硬盘中。
- 机器语言(machine language):由计算机直接使用的二进制编码指令构成的语言。
- 在机器语言中,处理过程中每一个微小的步骤都必须被明确地编码。
- 目前几乎没有程序是用机器语言编写的,主要是因为编写这种程序 太费时间。
- Pep/8:一台虚拟机
虚拟机(virtual computer(machine)):为了模拟真实机器地重要特征而设计的假想机器。
Pep/8有39个机器语言指令。这意味着每个Pep/8程序一定是由这些指令组合而成的 序列 。 - Pep/8反映的重要特征:
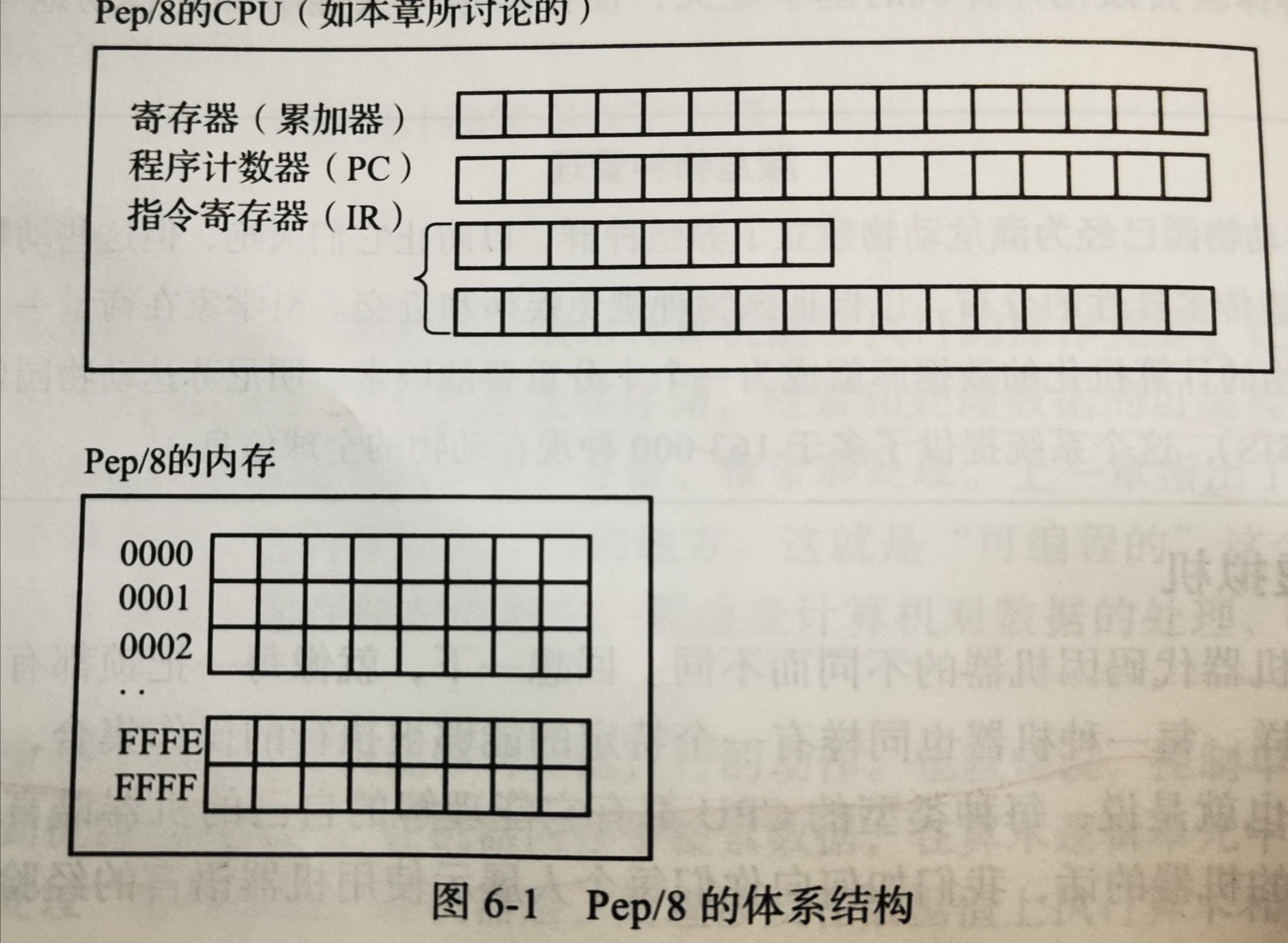
1.Pep/8的内存单元由65536个字节的存储空间构成。这些字节从0到65535( 十进制)进行编号。
2.Pep/8的字长是两字节,或者16比特。这样向算术/逻辑单元(ALU)流入的数据或从 算术/逻辑单元流出的数据在长度上就是 16比特。
3.Pep/8有 7个存储器。 - 累加器:用来保存操作的数据和结果的一种特殊的存储寄存器。
- 指令格式
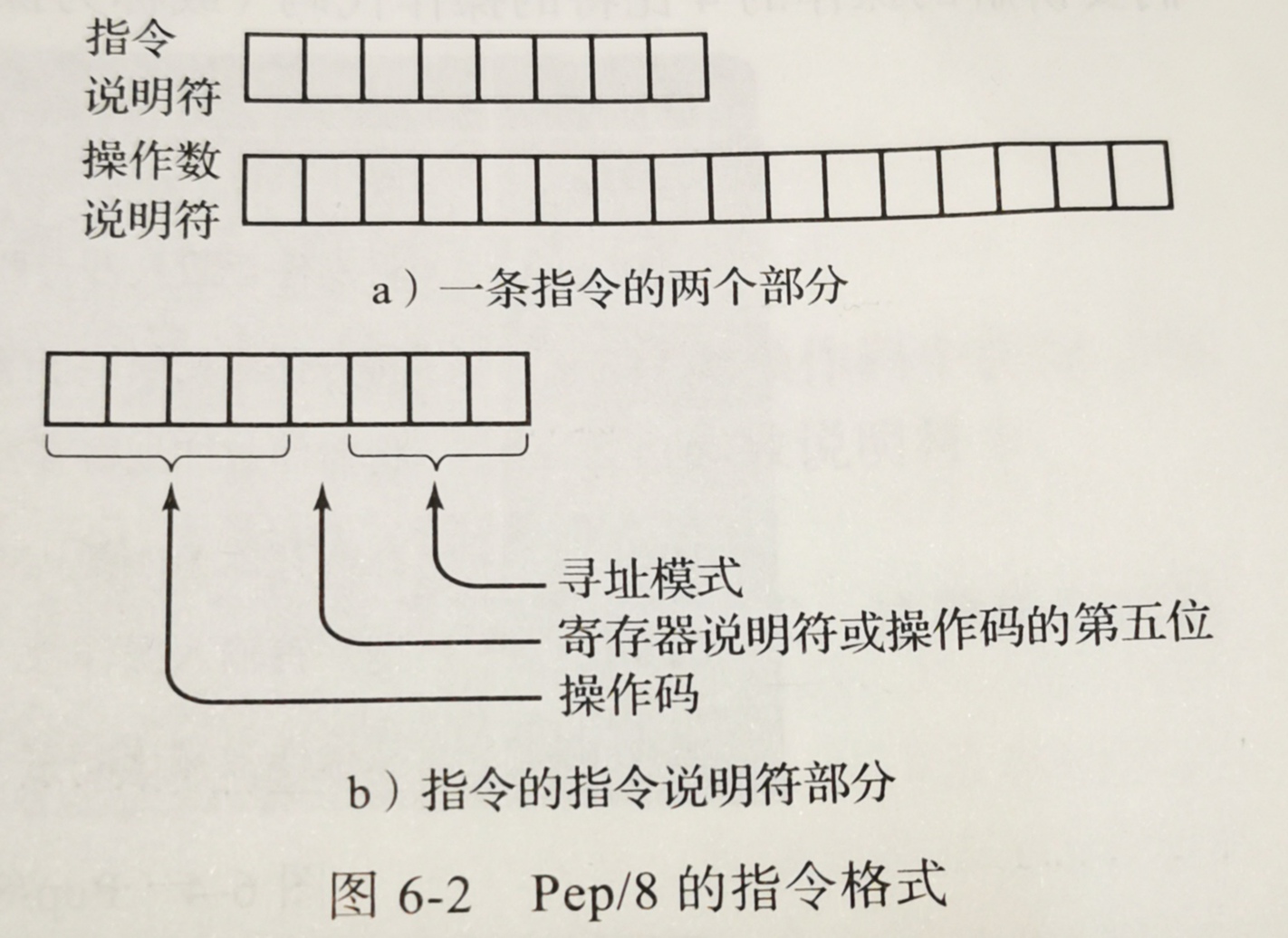
1.一条指令由两部分组成,即8位的指令说明符和(可选的)16位的 操作数说明符。
2.指令说明符(指令的第一个字节)说明了要执行什么操作和如何解释操作数的位置。
3.操作说明符(指令的 第二和第三个字节 )存放的是操作数本身或者操作数的地址。 注:有些指令 没有操作数说明符。
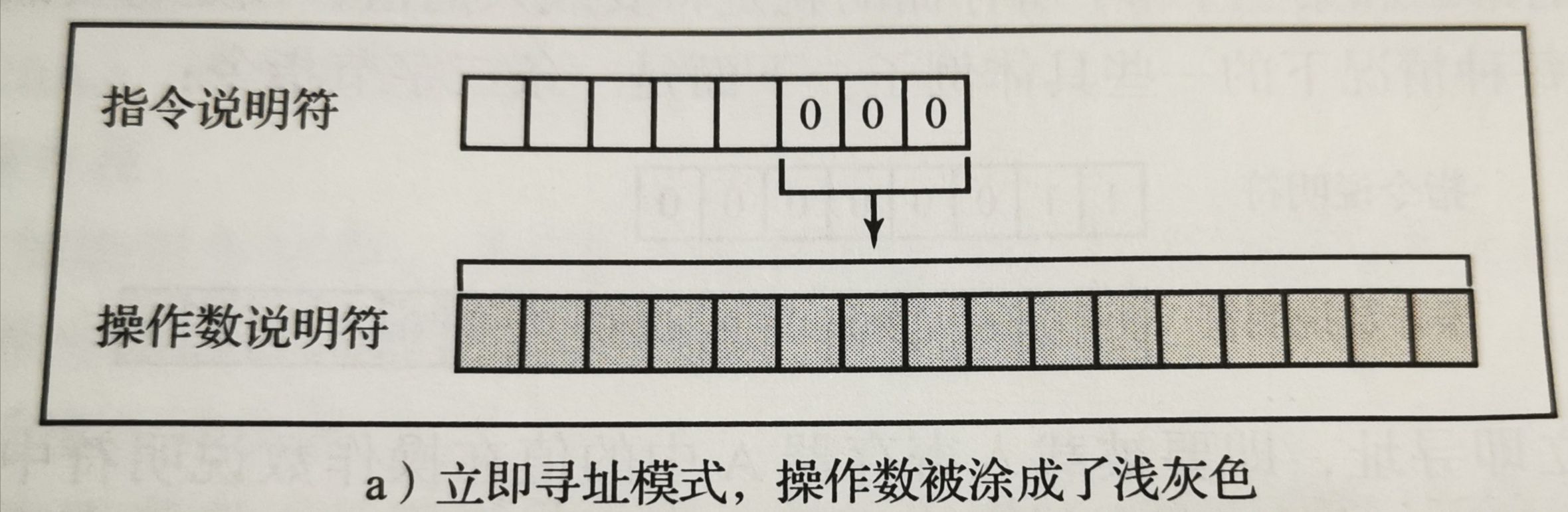
- 立即寻址:如果寻址模式是000,那么指令的操作数说明符中存储的就是操作数。
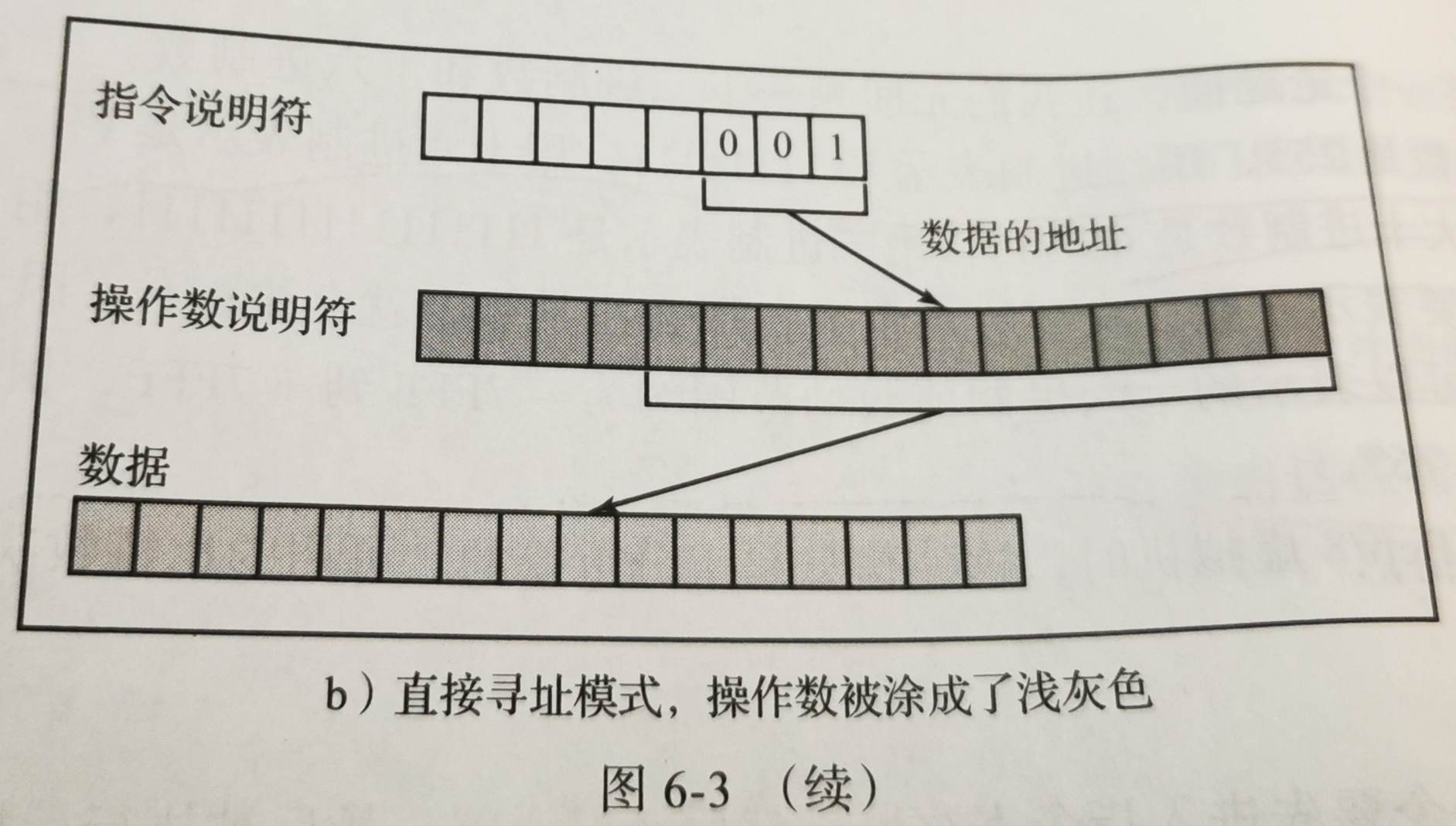
- 直接寻址:如果寻址模式是001,那么操作数说明符中存储的是操作数所在的内存地址名称。
- 立即寻址和直接寻址模式之间差别十分重要,因为它决定了操作中涉及的数据存储或将要被存储的位置。
- 没有操作数(要处理的数据)的指令称为一元指令,这些指令没有操作数说明符。也就是说,一元指令的长度是1个字节,而不是 3个字节。
- 一些示例指令

- 模式说明符说明了该字要载入的位置,其确定了指令的操作数部分(在指令的第二和第三字节)所存储的就是将要载入的值,或是将要载入的值的地址。
6.3 一个程序实例
- 例如,在屏幕上显示“hello”。
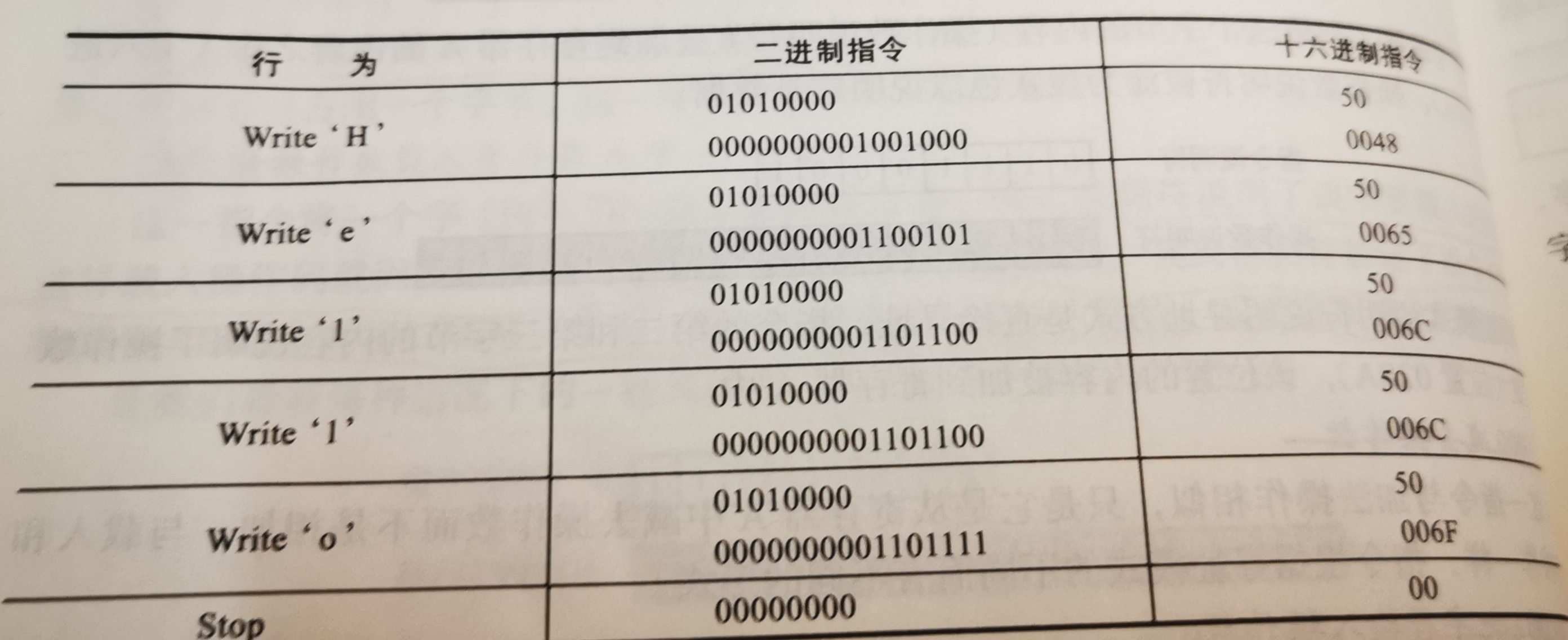
- 我们必须用二进制构造操作说明符,因为它由4位操作码、1位寄存器说明符和3位寻址模式说明符构成。
- 我们使用双引号来指一组字符,如“hello”,使用单引号指单个字符。
6.3.1 手工模拟
- 需要通过执行读取-执行周期的步骤模拟这个程序的执行。
6.3.2 Pep/8模拟程序
- 要运行一个程序,需要逐字节地输入十六进制的代码,每个字节之间用空格隔开,以zz结束程序。
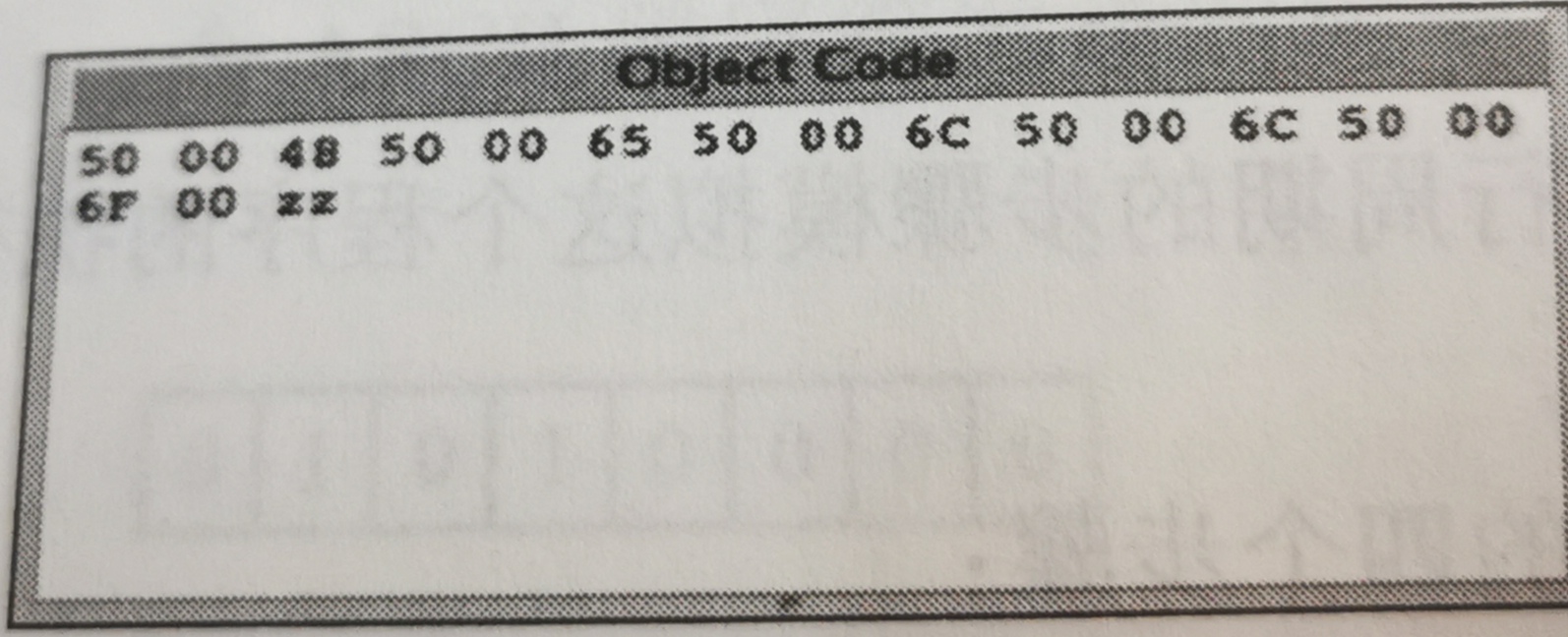
- 装入程序(loader):软件用于读取机器语言并把它载入内存的部分。
6.4 汇编语言
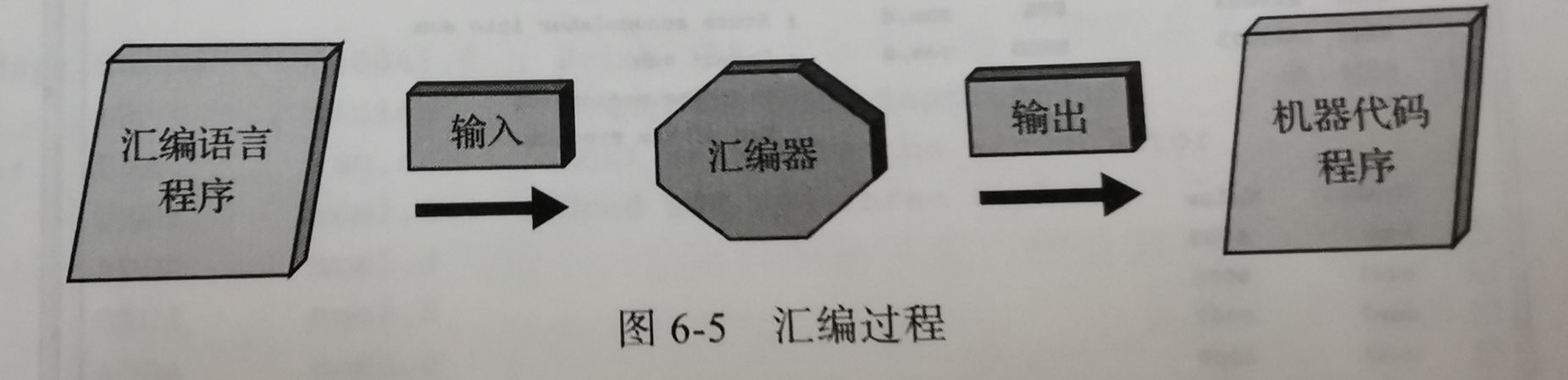
- 汇编语言(assembly language):一种低级语言,用助记码表示特定计算机的机器语言指令。
- 汇编器(assembler):把汇编语言程序翻译成机器代码的程序。
6.4.1 Pep/8汇编语言
- 在Pep/8汇编语言中,每个寄存器有一个操作码,操作数是十六进制的,由0x说明,寻址模式说明符由字母i或d说明。
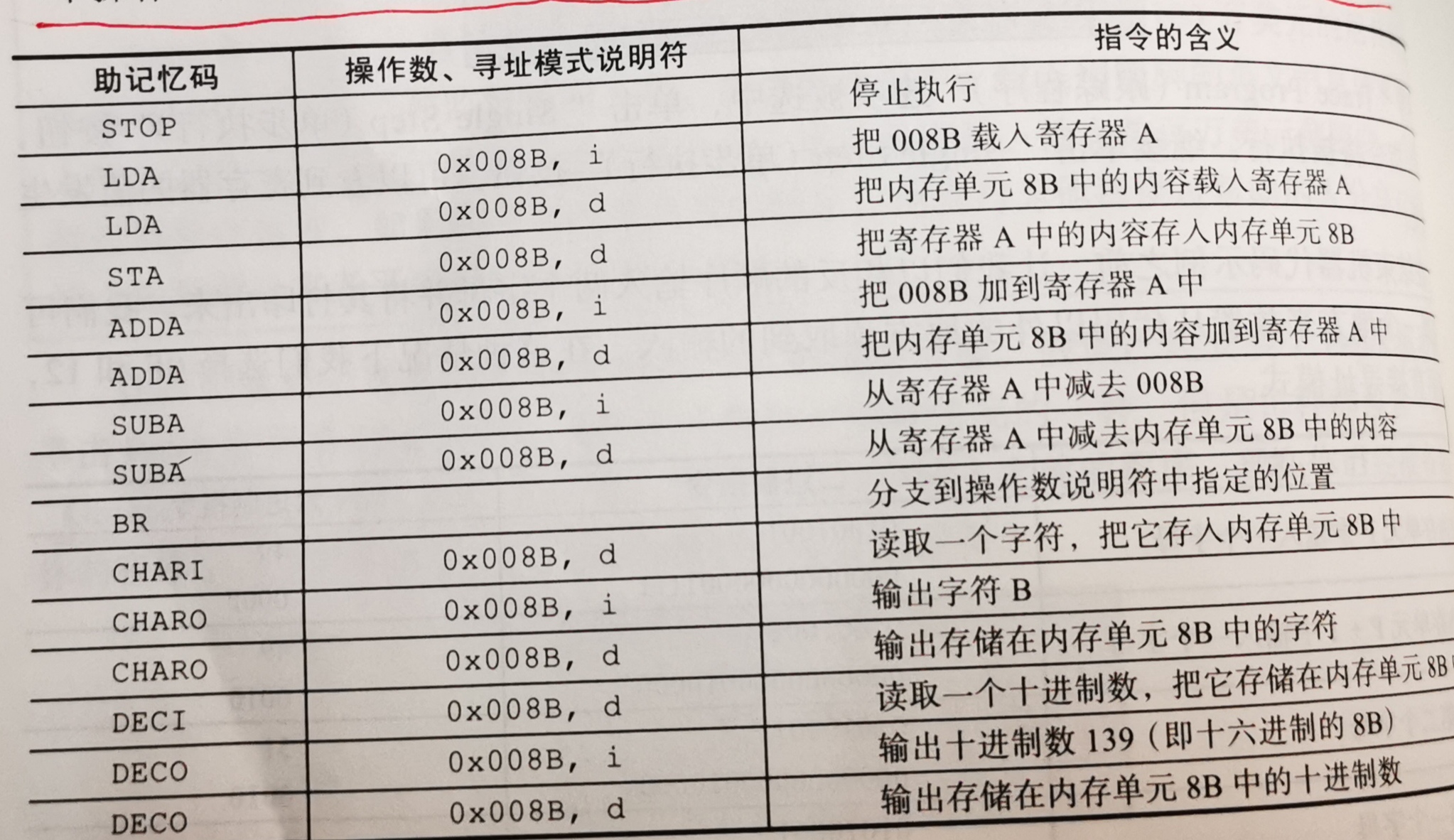
- Pep/8汇编语言提供了助记忆码DECI和DECO,它允许我们做十进制输入和输出。
6.4.2 汇编器指令
- 汇编器指令(assembler):翻译程序使用的指令。

6.4.3 Hello程序的汇编语言版本
- 注释(comment):为程序读者提供的解释性文字。
- 汇编器的输入是一个用汇编语言编写的程序,输出是用机器代码编写的程序。
6.4.4 一个新程序
6.4.5 具有分支的程序
- 一个将程序计数器设为下一条被执行的指令地址的BR指令可以改变程序计数器。

6.4.6 具有循环的程序
- 伪代码:这是一种可以减少对分支和循环的情形进行文字解释的方式。
6.5 表达算法
- 算法(algorithm):解决方案的计划或概要,或解决问题的逻辑步骤顺序。
- 伪代码(pseudocode):一种表达算法的语言。
6.5.1 伪代码的功能
- 虽然伪代码并没有特定的语法规则,但必须要表示变量、赋值、输入/输出、选择和重复的概念。




- 布尔表达式(boolean expression):评价为真或假的表达式。
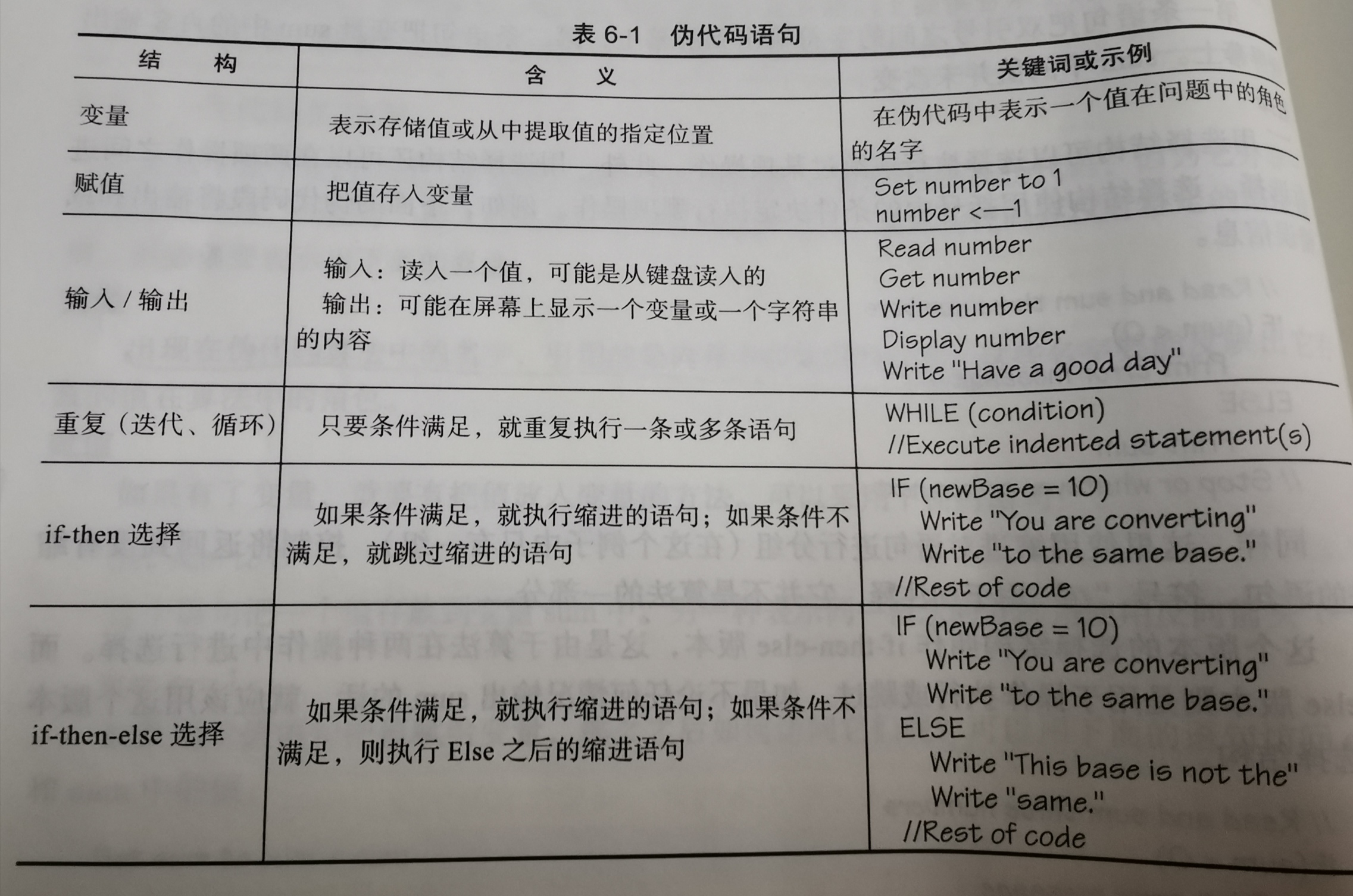
6.5.2 执行伪代码算法
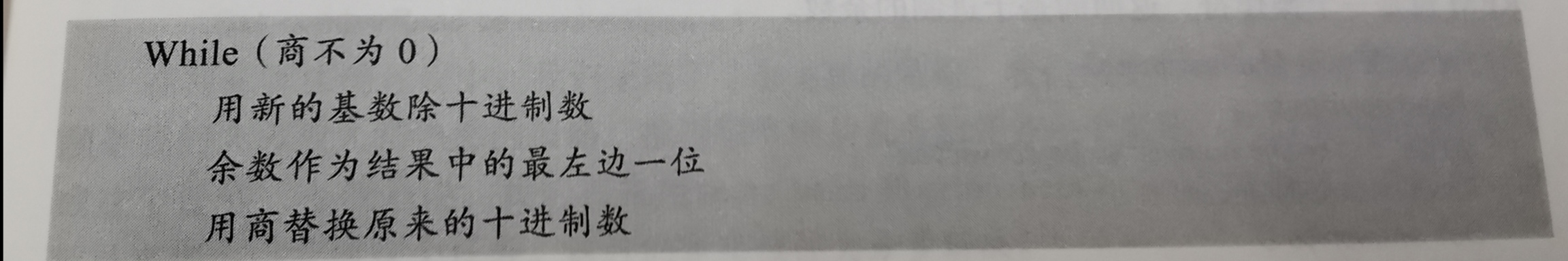
6.5.3 写伪代码算法
- 桌面检查(desk checking):在纸上走查整个设计。
6.5.4 翻译伪代码算法
- 由于汇编语言的范围是有限的,所以一个伪代码语句需要几个 Pep/8语句。
6.6 测试
- 测试计划(test plan):说明如何测试程序的文档。
- 代码覆盖(明箱)测试法(code-coverage(clear-box)testing):通过执行代码中的所有语句测试程序或子程序的测试方法。
- 数据覆盖(暗箱)测试法(data-coverage(black-box)testing):把代码作为一个暗箱,基于所有可能的输入数据测试程序或子程序的测试方法。
- 测试计划实现(test-plan implementation):用测试计划中规定的测试用例验证程序是否输出了预期的结果。
第7章 问题求解与算法设计
7.1 如何解决问题
- 重要的引入:1945年,George Polya所写的《如何解决它:数学方法的新观点》。
7.1.1 提出问题
- Polya的“如何解决它”列表

7.1.2 寻找熟悉的情况
- 人类是擅长识别相似的情况的,在计算领域中,会看到某种问题不断地以不同的形式出现,一个好的程序员看到以前解决的任务或者任务的一部分(子任务)时,会直接选用已有的解决方案。
7.1.3 分治法
- 通常,我们会把一个大问题划分为几个能解决的小单元,这项原则尤其适用于计算领域:把大的问题分割成能够单独解决的小问题。
- 可以把一项任务分成若干个子任务,而子任务还可以继续划分为子任务,如此进行下去。可以反复利用分治法,直到每个子任务都是可以实现的为止。
7.1.4 算法
- 算法(algorithm):在有限的时间内用有限的数据解决问题或子问题的明确指令集合。
7.1.5 计算机问题求解过程
- 计算机问题求解过程有四个阶段,即分析和说明阶段、算法开发阶段、实现阶段和维护阶段。

- 上述的四个阶段是存在交互现象的。如下图所示,粗线标明了各阶段间的一般信息流, 细线 表示在发生问题时可以退回前面的阶段的路径。
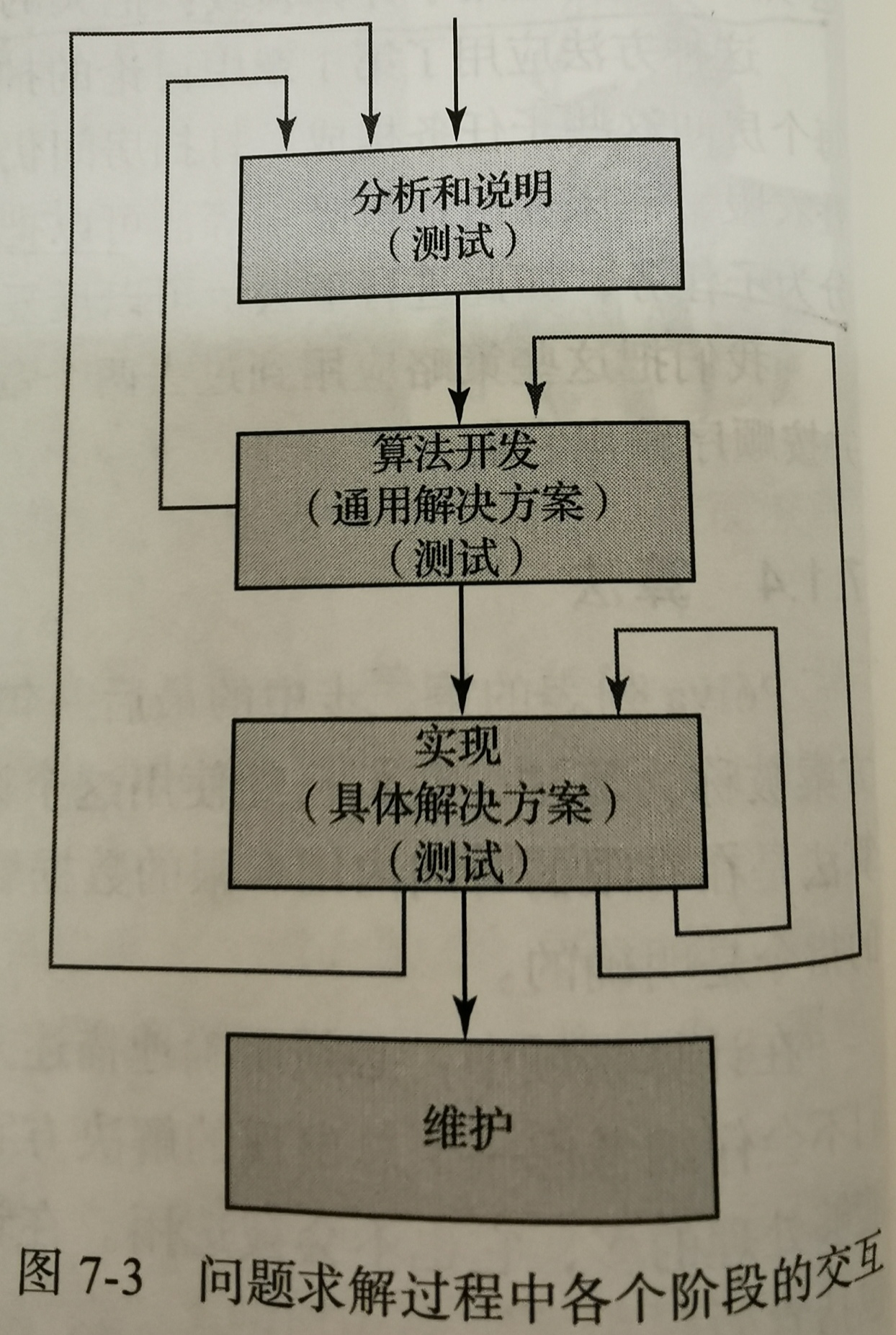
7.1.6 方法总结
- 主要可分解为一下四个步骤:
1.分析问题
2.列出主要任务
3.编写其余的模块
4.根据需要进行重组和改写
7.1.7 测试算法
- 数学问题求解的目标是生成问题的特定答案,因此,检查结果等价于测试推出答案的过程。
7.2 有简单参数的算法
- 简单(原子)变量是那些不能被分开的变量,是存储在一个地方的一个值。
7.2.1 带有选择的算法
- 顶级(主要)模块只是表达任务。
- 任何一个分支都包含一连串的语句。
7.2.2 带有循环的算法
- 计数控制循环
1.计数控制循环可以指定过程重复的次数,这个循环的 机制是简单记录过程重复的次数并且在重复再次开始前检测循环是否已经结束。
2.这类循环有三个不同的部分,使用一个特殊的变量叫 循环控制变量。第一部分是初始化:循环控制变量初始化为某个初始值。第二部分是测试:循环控制变量是否已经达到特定值?第三部分是增量:循环控制变量以1递增。
3.while循环被称为前测试循环。
4.永远不会终止的循环称为一个 无限循环。 - 事件控制循环
1.定义:循环中重复的次数是由循环体自身内发生的事件控制的循环。
2.当使用 while语句来实现事件控制循环时,这一过程仍分为三部分:事件必须初始化,事件必须被测试,事件必须更新。 - 计数控制循环是非常简单直接的,它指定了循环的次数,而在事件控制循环中则不太清楚,并不显而易见。
- 嵌套结构(nested structure):控制结构嵌入另一个控制结构的结构,又称为嵌套逻辑(nested logic)。
- 平方根
- 走查平方根算法如下图

- 抽象步骤(abstract step):细节仍未明确的算法步骤。
- 具体步骤(concrete step):细节完全明确的算法步骤。
7.3 复杂变量
- 引用中的字母叫作字符串。
7.3.1 数组
- 数组:同构项目的有名集合。
- 项目在集合中的位置叫索引。
- 与数组有关的算法分为三类:搜索、排序和处理。
7.3.2 记录
- 记录:异构项目的有名集合。
- 集合可以包含整数、实数、字符串或其他类型的数据。
7.4 搜索算法
7.4.1 顺序搜索
7.4.2 有序数组中的顺序搜索
- 无序数组

- 有序数组

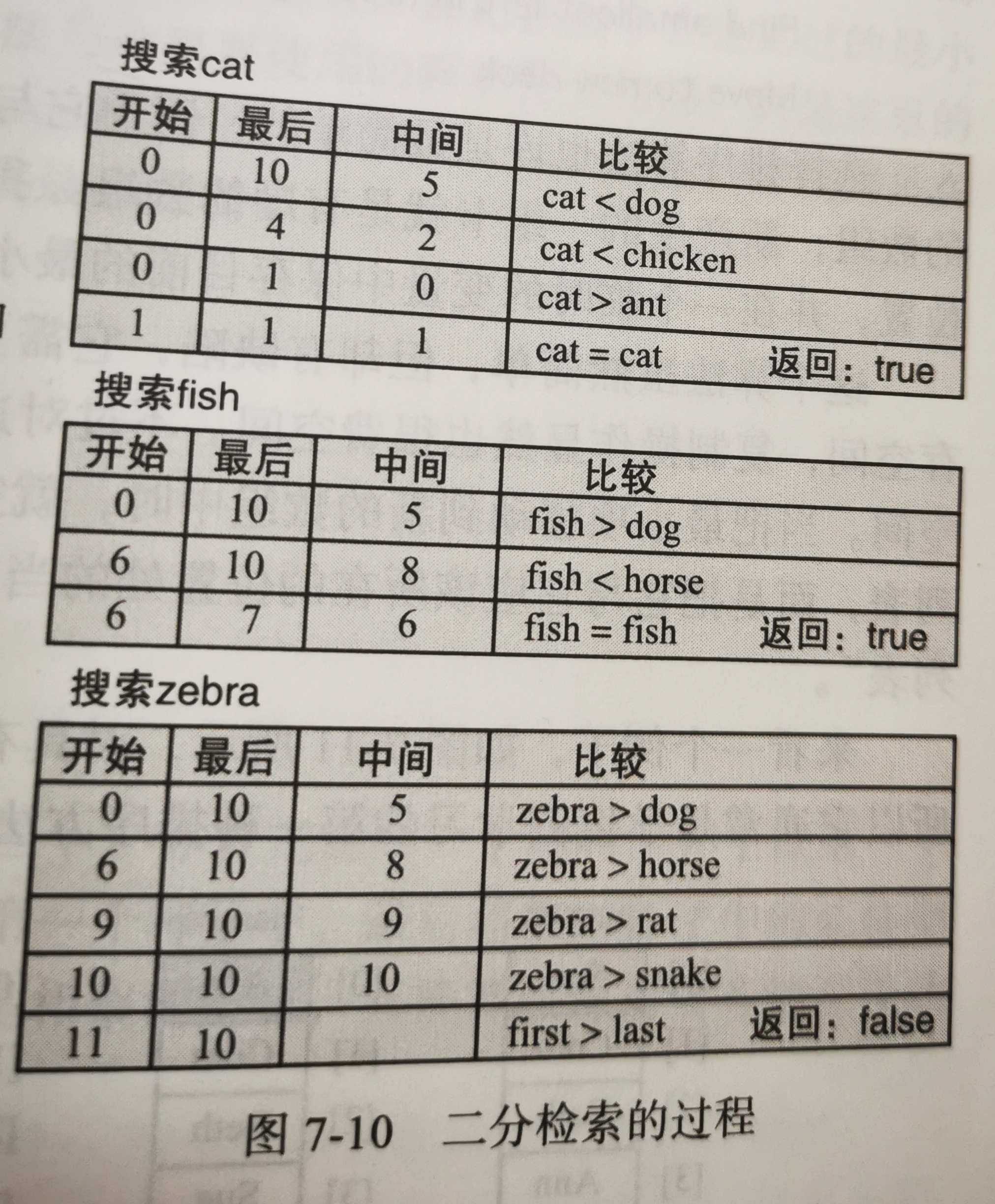
7.4.3 二分检索
- 二分检索(binary search):在有序列表中查找项目的操作,通过比较操作排除大部分检索范围。
- 二分检索不是从数组开头开始顺序前移,而是从数组中间开始。

7.5 排序
7.5.1 选择排序
- 选择排序算法虽然简单,但却有缺陷,它需要两个完整列表(数组)的空间。即使不考虑内存空间,赋值操作显然也很费空间。
7.5.2 冒泡排序
- 冒泡排序也是一种选择排序法,只是在查找最小值时采用了不同的方法。它从数组的最后一个元素开始,比较相邻的元素对,如果下面的元素小于上面的元素,就交换这两个元素的位置。
- 冒泡排序是非常慢的排序方式。
7.5.3 插入排序
- 插入排序:将元素加入有序部分类似于冒泡排序中冒泡的过程。如果找到了一个位置,要插入的元素比数组中这个位置的元素小,那么就将新元素插入这个位置。
7.6 递归算法
- 递归算法:当在一个算法中使用它自己时时的算法。
- 递归(recursion):算法调用它本身的能力。
- 每个递归算法至少有两种情况:基本情况和一般情况。
7.6.1 子程序语句
- 调用单元:命名代码出现的地方。
- 子程序有两种形式,一种是只执行特定任务的命名代码,一种是不仅执行任务,还返回给调用单元一个值(值返回子程序)。
7.6.2 递归阶乘
- 数的阶乘的定义:这个数与0和它自身之间的所有数的乘积。
- 尺寸系数就是要计算阶乘的数。
7.6.3 递归二分检索
- 递归算法必须从非递归算法中调用。
7.6.4 快速排序
- 快速排序算法的基本思想:对两个小列表排序比对一个大列表排序更快更容易。
- 其名字来自源于这种算法通常可以相对快地对数据元素列表进行排序,其基本策略是“分治法”。
- 如果数据是随机排列的,则快速排序是一个很好的排序方法。
7.7 几个重要思想
7.7.1 信息隐蔽
- 信息隐蔽(information hiding):隐蔽模块的细节以控制对这些细节的访问的做法。
7.7.2 抽象
- 抽象(abstraction):复杂系统的一种模型,只包括对观察者来说必需的细节。
- 数据抽象(data abstraction):把数据的逻辑视图和它的实现分离开。
- 过程抽象(procedural abstraction):把动作的逻辑视图和它的实现分离开。
- 控制抽象(control abstraction):把控制结构的逻辑视图和它的实现分离开。
- 控制结构(control structure):用于改变正常的顺序控制流的语句。
7.7.3 事物命名
- 给数据和过程一个名字,这些名字叫作标识符。
- 当我们要用一种程序设计语言把算法转换成计算机能够执行的程序时,可能必须修改标识符。
- 转换过程分两个阶段,首先在算法中命名数据和动作,然后把这些名字转换成符合计算机语言规则的标识符。
7.7.4 测试
- 测试在编程的每个阶段都十分重要,有两种基本的测试分类:白盒测试,基于代码本身; 黑盒测试,基于测试所有可能的输入值。