说明:基于jdk1.7
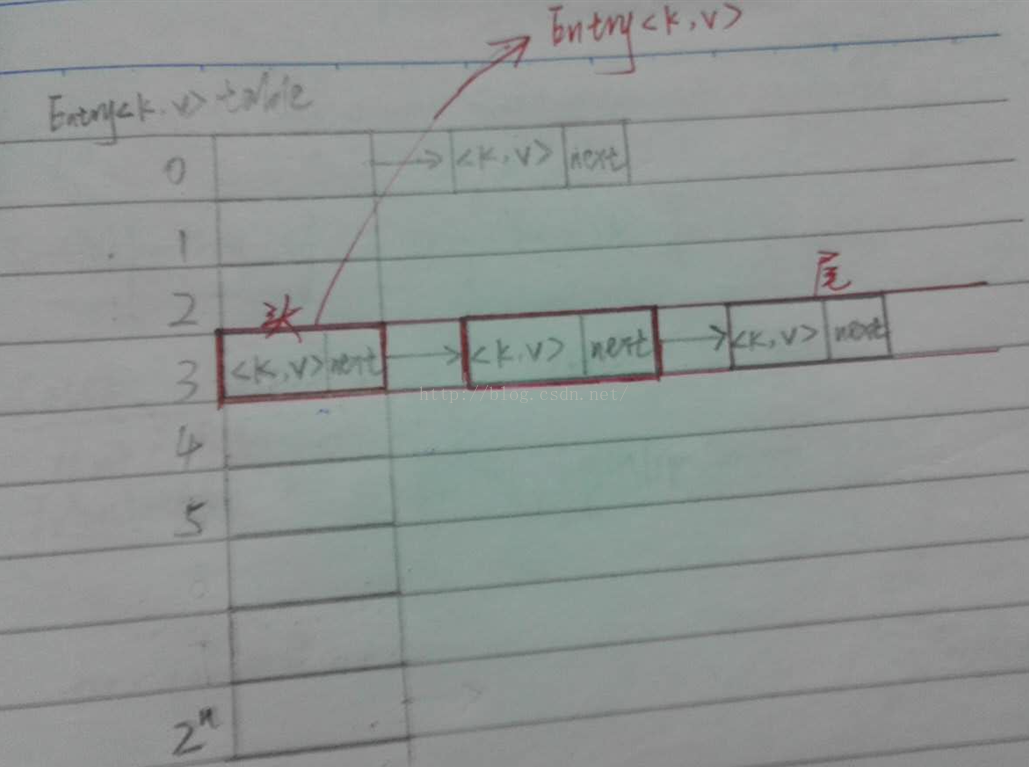
hashmap的原理图如下
一、HashMap源码解析
Entry
HashMap中有一个Entry,它是HashMap的静态内部类。通过声明可以知道,它实际上就类似于一个链表,链表中的元素就是<K,V>,还有个next指向下一个Entry节点。
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; …… }
在HashMap的实现中,有一个桶(bucket)的概念:对于Entry数组而言,数组的每个元素存储的是链表,而不是直接的Value。在链表中的每个元素才是真正的<Key, Value>。而一个链表对应一个桶!
属性
//默认初始容量,16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; //默认负载因子,0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; static final Entry<?,?>[] EMPTY_TABLE = {}; //【核心】HashMap的底层实现 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; //元素数量 transient int size; //阈值(容量*加载因子):当达到该值时,会进行rehash int threshold; //负载因子(size/数组长度。当负载情况达到该值时,自动增加数组的容量,并进行再散列(重新将现有对象分布到容器中)) final float loadFactor; //修改次数 transient int modCount; static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;
构造方法
public HashMap(int initialCapacity, float loadFactor) public HashMap(int initialCapacity) public HashMap() public HashMap(Map<? extends K, ? extends V> m)
在初始化HashMap时,可以指定其初始化容量,和负载因子。如果不指定,则使用定义的默认值。默认初始容量为16,默认负载因子为0.75。
对于指定了初始容量的构造方法,并不会将它作为HashMap的容量,而是选择大于该数字的第一个 2 的幂作为容量:(1->1、7->8、9->16)
HashMap(int initialCapacity) -->HashMap(int initialCapacity, float loadFactor) -->tableSizeFor(initialCapacity) /** * Returns a power of two size for the given target capacity. */ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }
put方法
public V put(K key, V value) { //map为空表时,进行扩充 if (table == EMPTY_TABLE) { inflateTable(threshold); } //如果key为null,直接定位到table[0]处,进行处理 if (key == null) return putForNullKey(value); //计算key的hash值 int hash = hash(key); //根据key的hash,定位key在table中索引 int i = indexFor(hash, table.length); //判断key是否存在 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果key已存在,则覆盖原value //【判断key相等】:也就是判断两个Object是否相等 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); //返回旧值(方法返回后,可能还要用到旧值) return oldValue; } }//key不存在 //修改次数+1 modCount++; //添加<k,v> addEntry(hash, key, value, i); return null; }
get方法
public V get(Object key) { //key为null和非null分别对应table数组的索引为0和非0位置。两种情况分开处理。 //如果key为null if (key == null) return getForNullKey(); //key非null时 Entry<K,V> entry = getEntry(key); //返回key对应value值 return null == entry ? null : entry.getValue(); } private V getForNullKey() { if (size == 0) { return null; } //遍历下标为0处的Entry(类似链表),查找key for (Entry<K,V> e = table[0]; e != null; e = e.next) { //key存在,返回对应value值 if (e.key == null) return e.value; } //不存在,返回null return null; } final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //计算key的hash。如果key为null,则hash为0 int hash = (key == null) ? 0 : hash(key); //通过hash定位key在数组中的下标。遍历所在下标处的Entry(链表结构),查找key for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; //如果key存在,返回该Entry if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } //key不存在,返回null return null; }
实际上,如果能将put方法搞清楚了,get方法就基本是a little case.
①hash函数的选择
hash函数的构造方法有以下几种:
- 直接地址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
hashmap使用的除留余数法,该方法最简单,是最常用的构造hash函数的方法。
②hash冲突处理
常用的处理冲突的方法有如下几种:
- 开放地址法
- 再哈希法
产生冲突时,使用其它的哈希构造函数计算得到另一个地址,如果再冲突,再换个哈希函数再计算,直到冲突不再发生。这种方法不易产生“聚集”,但增加了计算的时间。
- 建立一个公共的溢出区
- 链地址法
也叫拉链法。冲突的元素链接在原有元素上,这样就形成了一个链表。在链表中的插入位置可以在表头,表中,也可以在中间。
HashMap使用的就是链地址法,插入位置在表头。
void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; //创建一个Entry,并插入到表头 table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
二、扩容
HashMap元素个数达到阈值时,如果继续插入元素,则会进行扩容。会先将table容量扩容至原来的2倍,然后再进行扩容。具体步骤是:
1.扩容至原来的两倍
2.暂存原有的table,然后创建一个新的table
3.依次重新计算原有table中每个bucket的节点(Entry)的key的hash,找到在新table中即将插入的bucket位置。然后在该新位置处的
头结点指向原有位置处头节点。
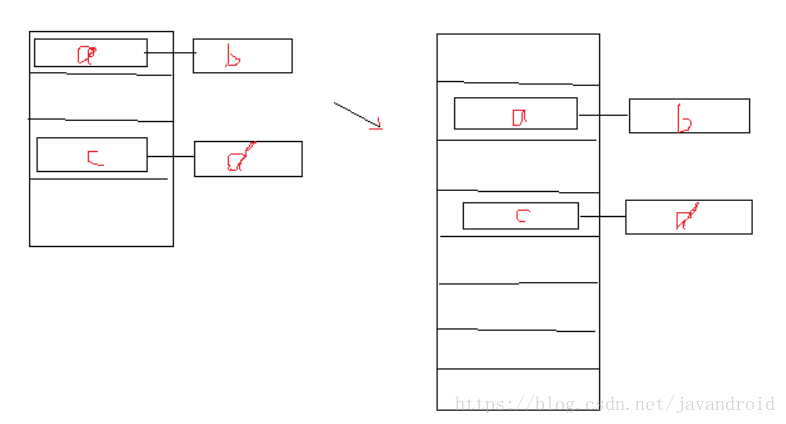
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { //扩容到之前的2倍 resize(2 * table.length); …… } …… } void resize(int newCapacity) { //暂存旧table Entry[] oldTable = table; int oldCapacity = oldTable.length; //旧容量达到了规定的最大容量值,则将阈值提高到Integer取值范围的最大值 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } //构建新table(容量为newCapacity) Entry[] newTable = new Entry[newCapacity]; //将旧table中的全部数据转移到新table中 transfer(newTable, initHashSeedAsNeeded(newCapacity)); //引用指向新table table = newTable; //新table的阈值也相应的增大(但该值不能超过MAXIMUM_CAPACITY + 1) threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); } void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; //外层循环控制table for (Entry<K,V> e : table) { //内存循环控制每个bucket位的链表的复制 while(null != e) { // Entry<K,V> next = e.next; //重新计算key的hash(因为hashseed可能变了) if (rehash) { e.hash = (null == e.key) ? 0 : hash(e.key); } //通过key的hash定位新的bucket索引 int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; //将原链表复制到新table的头部(直接引用原链表头节点) newTable[i] = e; //继续table的下一个bucket位 e = next; } } }
三、线程安全
由于hashmap是非线程安全的,所以在多线程下,会出现线程安全问题
①两个线程同时添加元素时,存在竞态条件。
如下,我们希望一个线程执行添加成功,另一个线程再添加时发现已存在,就不再添加。但实际情况可能是:当两个线程同时执行if条件时,都发现没有key,所以都执行了大括号内的代码,显然不安全。
if(!map.containsKey(key)) { map.put(key,value); return true; }
②两个线程同时添加元素时,都发现容量已经达到阈值,都需要进行扩容。扩容时会将原有的所有元素移动到新的table中。两个线程同时进行移动操作,显然会产生不安全的问题。
void resize(int newCapacity) { //暂存旧table Entry[] oldTable = table; int oldCapacity = oldTable.length; //旧容量达到了规定的最大容量值,则将阈值提高到Integer取值范围的最大值 if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } //构建新table(容量为newCapacity) Entry[] newTable = new Entry[newCapacity]; //将旧table中的全部数据转移到新table中 transfer(newTable, initHashSeedAsNeeded(newCapacity)); table = newTable; //新table的阈值也相应的增大(但该值不能超过MAXIMUM_CAPACITY + 1) threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); }
等等,不一而足。
③rehash导致链表成环,造成死循环。
参考左耳朵耗子的在酷壳上的文章:疫苗:JAVA HASHMAP的死循环
总结
搞清楚下面几个问题,HashMap的知识就算完全掌握了。
1.HashMap的特点和工作原理?
2.碰撞如何处理?
处理冲突的方式很多,HashMap使用链地址法来处理冲突
3.hashCode相同,对象是否相等?对象相等,是否有相同的hashCode?
hashCode相同,则会继续使用key的equals()方法来比较对象。所以hashCode相同,对象不一定相等。
对象相等,通过同一个hash函数当然得到的结果是一样的。所以对象相等,hashCode也一定相等。
4.HashMap的负载因子(load factor)作用是什么?如果容量达到阈值如何处理?
随着越来越多的元素添加到HashMap,发生碰撞的情况也越来越多,链表可能会越来越长。而为了防止这种情况,所以设置了一个负载因子。
HashMap默认的负载因子是0.75。默认初始容量为16,也就是说达到12个元素时,就会达到阈值了。此时将table扩容到原来的2倍,并重新计算key的hash并将该元素添加到新的bucket位置中。
5.HashMap元素个数达到阈值时,如果继续插入元素,扩容的步骤?
6.HashMap会有什么安全问题?
7.为什么String,Integer这样的包装类适合作为HashMap的键?
HashMap是使用key的hash来定位位置的,如果我们做put操作后,对象发生了变化导致其hash发生变化,当我们再次做get操作时,定位显然可能就变了,结果就是该key不存在。
如下,当MyClass作为key时,如果put之前a=b=0,put完后,我们将a=b=1,显然hashCode就变了
public class MyClass { int a; int b; @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + a; result = prime * result + b; return result; } }
String,Integer都是final类型的,对象不会发生变化,也就不用担心put和get时hashcode不一致的问题。
8.如果使用自定义的对象来作为key,要注意些什么?
通过上一个问题,我们已经很明确了。①只要自定义的对象做put操作后不再发生变化就能用来作为key。当然使用时一定要小心,很容易疏忽而发生危险!
当然还要注意一点,通常情况下,对于自定义的对象来作为key,我们要同时覆盖hashCode()方法和equals()方法
9.ConcurrentHashMap和Hashtable有什么区别?
HashMap是非线程安全的,而Hashtable则是线程安全的。但是Hashtable使用的synchronized来实现同步,而ConcurrentHashMap则使用分段锁来实现线程同步,锁的粒度更细,所以ConcurrenttHashMap性能比HashTable更好。所以Hashtable也逐渐被遗弃。
10.如果指定的初始容量为1,7,9,则HashMap的实际容量会是多少?
如果构造函数指定了一个数字作为容量,那么 Hash 会选择大于该数字的第一个 2 的幂作为容量。(1->1、7->8、9->16)
参考: