对于IO流中字节流的总结
字节流的概念
由于应用程序,经常需要和文件打交道,所以Inputstream专门提供了读写文件的子类:FileInputStream和FileOutputStream类,如果程序对于文件的操作较为简单,就比如说只是顺序的读写文件,那么就可以使用字节流进行操作.并且我们都知道,所有文件的最底层数据类型都是字节,所以说,字节流的应用范围是十分广的,当然,它也有相应的缺点,只能处理简单的数据文本,一旦数据多了,其处理速度慢的弊端也就显现了出来.
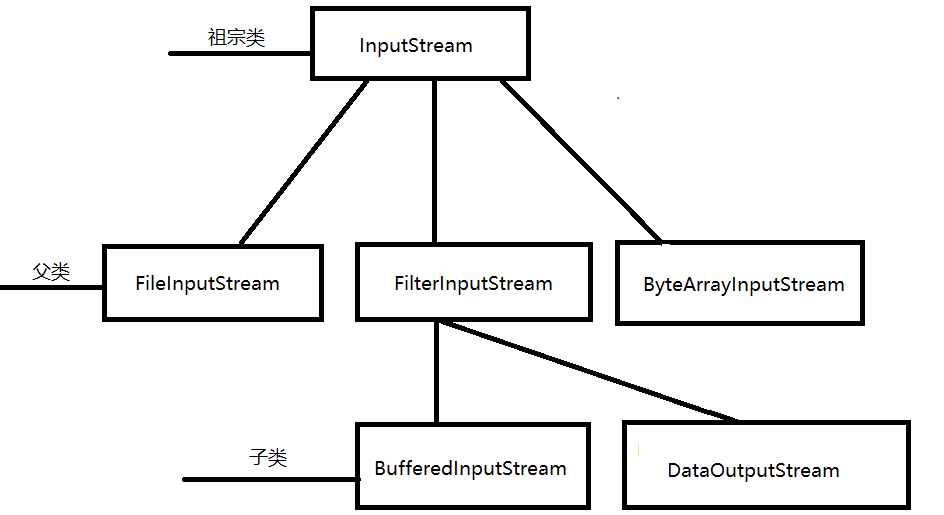
子父类关系
通过超级父类InputStream延伸出的很多派系,并且一些派系完美的解决了,字节流速度慢的问题(字节缓冲流)
编码方式
查阅了挺久资料的,发现在编码方式这块,由于我还没有接触计算机原理这门课,所以对于这块的概念十分的模糊,从昨天到今天也查阅了许多资料,但还是无法很系统的整理出一些真正有用的东西,所以对于编码方式这里,我会在以后认真的总结一番。
其与字符流的不同
1.
字节流传输的最基本单位是字节
字符流传输的最基本单位是字符
2.
编码方式不同
3.
字符流在传输方面上,由于计算机的传输本质都是字节,而一个字符由多个字节组成,转成字节之前先要去查表转成字节,所以传输时有时候会使用缓冲区。
字节流传输时不会用到缓冲区,是通过直接访问IO设备的方式来完成传输。
4.
字节流适用于图片,文本,视频等等格式的数据.
字符流适用于文本,并且最好是中文文本,处理速度超快.
字节流的输入输出流
构造方法(1)

构造方法(2)

构造方法(3)

这三种构造方法都要求在对象创建之前便给出文件名。
对于一个文件进行的输入输出操作的代码
import java.io.*;
import java.util.Scanner;
/*
* 该类用于做一个文件字节流的例子
*/
public class Demo1 {
public static void main(String[] args) throws IOException{
File file=function();
choice(file);
}
public static File function() throws IOException{ //该方法用于创建一个文件对象
File file=new File("C:\Users\Lenovo\Desktop\Demo.txt");
//创建一个文件对象
if(!file.exists()) {
file.createNewFile(); //若文件不存在则创建一个文本文件
}
return file;
}
public static void choice(File file) throws IOException{ //该类用于进行选择输入方式(是覆盖还是从文件末尾写)
int a = 0;
System.out.println("a==");
Scanner sc=new Scanner(System.in);
a=sc.nextInt();
switch(a) {
case 1:function1(file);function3(file);break; //这是覆盖式写入
case 2:function2(file);function3(file);break; //这是从文件末尾写入
default:System.out.println("无该索引");
}
sc.close();
}
public static void function1(File file) throws IOException{
FileOutputStream fos=new FileOutputStream(file);
System.out.println("请输入您想要写入的信息");
Scanner sc=new Scanner(System.in);
String s=sc.nextLine();
byte[] b=s.getBytes(); //将字符串转换为字节数组
fos.write(b);
fos.close();
sc.close();
}
public static void function2(File file) throws IOException{ //该方法是从末尾开始写
FileOutputStream fos=new FileOutputStream(file,true);
System.out.println("请输入您想要写入的信息");
Scanner sc=new Scanner(System.in);
String s=sc.nextLine();
byte[] b=s.getBytes();
fos.write(b);
fos.close();
sc.close();
}
public static void function3(File file) throws IOException{
FileInputStream fis=new FileInputStream(file);
byte[] b=new byte[(int) file.length()];
//运用File类关于文件属性的方法,但是返回值是long型数据,需要强转。
fis.read(b);
System.out.println(new String(b));
fis.close();
}
}
第一次键入a=1,输入"啊哈哈"
第二次键入a=1,输入"嘿嘿嘿” 会发现文件中只剩下"嘿嘿嘿”
第三次键入a=1,输入"啊哈哈"
第二次键入a=2,输入"嘿嘿嘿” 会发现文件中是"啊哈哈嘿嘿嘿”
字节缓冲流
BufferedInputStream&BufferedOutputStream
这两种类为IO提供了带缓冲区的操作,一般打开文件进行写入或读取操作时,都会加上缓冲,这样提高了IO的性能。
对于IO的抽象理解
如果我们要将一缸水转到另一缸水中
FileOutputStream&FileInputStream相当于把水一滴一滴的转移
DataOutputStream&DateaInputStream相当于把水一瓢一瓢的转移
BufferedOutputStream&BufferdeInputStream相当于先把水全部放入一缸水中,然后在将这一缸水倒入目标缸中。
所以说带缓冲区的字节缓冲流是很好使的。
我们用字节缓冲流代码实现一下文件的复制
import java.io.*;
/*
* 用字节缓冲流完成对于文件的复制
*/
public class Dmeo2 {
public static void main(String[] args) throws IOException{
byte[] b=function();
function1(b);
}
public static byte[] function() throws IOException {
InputStream is=new FileInputStream("C:\Users\Lenovo\Desktop\Demo.txt");
BufferedInputStream bis=new BufferedInputStream(is); //构造方法参数为InputStream类型
byte[] b=new byte["C:\Users\Lenovo\Desktop\Demo.txt".length()];
bis.read(b); //将信息转换为字节数组
bis.close();
return b; //将字节数组返回
}
public static void function1(byte[] b) throws IOException {
OutputStream os=new FileOutputStream("C:\Users\Lenovo\Desktop\Demo1.txt");
BufferedOutputStream bos=new BufferedOutputStream(os);
bos.write(b);
bos.flush(); //此处一定要记得刷新缓冲区,这样信息才能流入文件
bos.close(); //若是我们手动关闭的话,系统会帮我们自动刷新缓冲区
/*所以说fluse()方法与close()方法写一个就行,但这只是理论上的
* 但是为了程序的可读性还是都写好一点
*/
}
}
这里的Demo文件是我们上个代码也就是字节流中所创建的文件。
字节数组流
字节数组流在功能方面属于字节流,属于直接作用于目标设备的一种流类.经常而言我们都是针对文件的操作,然后带上缓冲的节点流进行处理,但有时候为了提升效率,我们发现频繁的读写文件并不是太好,那么于是出现了字节数组流,即存放在内存中,因此又称之为内存流.(这里是直接copy别人的).其实也就是将我们的目标放在了缓冲区之上,而不再是文件了.
ByteOtputArrayStream(字节数组输出流)
构造方法:

第一个是有初始长度但可以增加,第二个是自己设置长度
这里我感觉我们不可以将其理解为数组,总感觉它和集合真的好像,因为他的属性单位也是以size()方法来查看的,并且他和集合一样长度是可变的。
特殊方法:

这个无效close最先真的搞得我一头雾水,后来才反应过来这里我们操作的对象是缓冲区,缓冲区是无法关闭的,或者说关闭了会出很大的问题,所以这里他应该是无效的,并且作为子类,我们从父类中所拿到的方法并不全是有用的,毕竟子类与父类是不同的两个单独存在的个体。

关于缓冲区属性的一个方法


这两个方法都是write方法,这里的处理方式其实和父类中的write方法基本一致吧,只是目标有所变化。
ByteInputArrayStream字节输入流
构造方法

这里最关键的是buf的选择,作为输入流我们若是想从缓冲区得到数据的话,buf应该是输入流.toByteArray()方法得到的数组,在我看来输入流就代表着那一块我们正存放数据的缓冲区,这样转换成数组合情合理
完成一个简单读写操作
import java.io.*; public class Demo3 { public static void main(String[] args) throws IOException{ function(); } public static void function() throws IOException{ //该方法用于输出流的存入 ByteArrayOutputStream bos=new ByteArrayOutputStream(); //使用默认构造方法 String s="我是哈哈哈"; byte[] b=s.getBytes(); bos.write(b); //这里不要像上文给出的write(byte[] b,int off,int len)因为这样的话我们还要 //计算一下字节个数,很麻烦,还容易出错,当然也有其它方法知道准确字节数但是代码量会多 function1(bos.size(),bos); } public static void function1(int a,ByteArrayOutputStream bos) throws IOException{ ByteArrayInputStream bis=new ByteArrayInputStream(bos.toByteArray()); //如上文所说,以输出流所转化成的数组为参数创建一个对象 byte[] b=new byte[a]; bis.read(b); //把字节存到b数组中 System.out.println(new String(b)); } }
字节数据流
DataInputStream和DataOutputStream类创建的对象称为数据输入流和数据输出流.这两个流是很有用的流,他们允许程序按着及其无关的的风格读取JAVA原始数据.也就是说,当读取一个数值时,不必再关心这个数值应该是多少个字节(而且有些数据类型long,double数据类型真的很难转成字节),它们属于处理流,即程序通过一个间接流类去调用节点流类,以达到更加灵活方便地读写各种类型的数据,这个间接流类就是处理流。
构造方法


也就是说他们的参数是节点流。并且这里我们可以很好的利用多态的概念,FileInputStream。。。。等等都可以作为参数
读写方法writexxx,readxxx。
代码完成简单的读取操作
import java.io.*;
public class Demo4 {
static String file="C:\Users\Lenovo\Desktop\李xx.txt";
public static void main(String[] args) throws IOException{
function();
function1();
}
public static void function() throws IOException{ //该方法用于存
DataOutputStream dos=new DataOutputStream(new FileOutputStream(Demo4.file));
dos.writeInt(1);
dos.writeInt(2);
dos.writeInt(3);
dos.writeInt(4);
dos.writeUTF("你是真滴6");
dos.close();
}
public static void function1() throws IOException{
DataInputStream dis=new DataInputStream(new FileInputStream(file));
System.out.println(dis.readInt());
System.out.println(dis.readInt());
System.out.println(dis.readInt());
System.out.println(dis.readInt());
System.out.println(dis.readUTF());
}
}
但是我发现数据流中读取时指针的跳转过于笨拙,也就是说我们必须知道下个数据类型是啥,才能将其准确读取出来,并且前一个读不出来的话,后一个也是无法读取的。