原文地址:https://zhuanlan.zhihu.com/p/32658341
问题
之前我们讨论的 PCA降维,对样本数据来言,可以是没有类别标签 y 的。如果我们做回归时,如果特征太多,那么会产生不相关特征引入、过度拟合等问题。我们可以使用PCA 来降维,但 PCA 没有将类别标签考虑进去,属于无监督的。
假设我们对一张 100*100 像素的图片做人脸识别, 每个像素是一个特征,那么会有 10000 个特征,而对应的类别标签 仅仅是 0/1 值, 1 代表是人脸。 这么多特征不仅训练复杂,而且不必要特征对结果会带来不可预知的影响,但我们想得到降维后的一些最佳特征(与
关系最密切的),怎么办呢?
线性判别分析(二分类情况)
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。LDA的基本思想:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点中心尽可能远离。更简单的概括为一句话,就是“投影后类内方差最小,类间方差最大”。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据分为 “+”和“-”,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而“+”和“-”数据中心之间的距离尽可能的大。
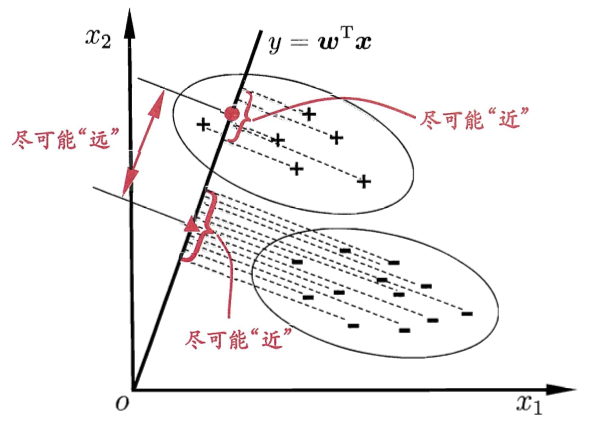 周志华《机器学习》
周志华《机器学习》
我们将这个最佳的向量称为 ,那么样例
到方向向量
上的投影可以用下式来计算
当 是二维的,我们就是要找一条直线(方向为
)来做投影,然后寻找最能使样本点分离的直线。
接下来我们从定量的角度来找到这个最佳的 w。
给定数据集 ,
,令
、
、
、
分别表示第
类示例的样本个数、样本集合、均值向量、协方差矩阵。
的表达式:
的表达式:
由于是两类数据,因此我们只需要将数据投影到一条直线上即可。假设我们的投影直线是向量 ,则对任意一个样本
,它在直线
的投影为
,对于我们的两个类别的中心点
,在直线
的投影为
和
,分别用
和
来表示。
什么是最佳的 呢?我们首先发现,能够使投影后的两类样本中心点尽量分离的直线是好的直线,定量表示就是:
但是只考虑 行不行呢?不行,看下图
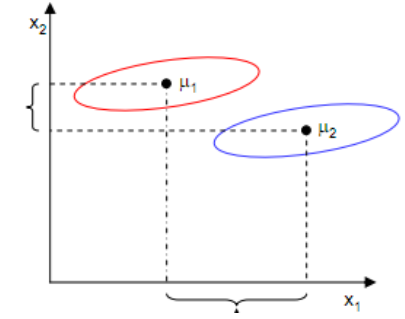
样本点均匀分布在椭圆里,投影到横轴 上时能够获得更大的中心点间距
,但是由于有重叠,
不能分离样本点。投影到纵轴
上,虽然
较小,但是能够分离样本点。因此我们还需要考虑同类样本点之间的方差,同类样本点之间方差越小, 就越难以分离。
我们引入另外一个度量值,称作散列值( scatter),对投影后的类求散列值,如下:
从公式中可以看出,只是少除以样本数量的方差值,散列值的几何意义是样本点的密集程度,值越大,越分散,反之,越集中。
而我们想要的投影后的样本点的样子是:不同类别的样本点越分开越好,同类的越聚集越好,也就是均值差越大越好,散列值越小越好。 正好,我们同时考虑使用 和
来度量,则可得到欲最大化的目标:
接下来的事就比较明显了,我们只需寻找使 最大的
即可。
先把散列值公式展开:
我们定义上式中的中间那部分:
这个公式的样子不就是少除以样例数的协方差矩阵么,称为散列矩阵( scatter matrices)。
我们继续定义“类内散度矩阵”(within-class scatter matrix):
以及“类间散度矩阵”(between-class scatter matrix) :
则 可以重写为:
这就是LDA欲最大化的目标。即 与
的“广义瑞利商”(generalized Rayleigh quotient)。
如何确定 呢?
注意到 式中的分子和分母都是关于
的二次项,因此
的解与
的长度无关,只与其方向有关(
为投影后直线的方向),不失一般性,令
,则式
等价于:
由拉格朗日乘子法,上式等价于:
其中 为拉格朗日乘子。注意到
的方向恒为
,不妨令:
将其带入上式得:
也就是说我们只要求出原始二类样本的均值和方差就可以确定最佳的投影方向 了。
PCA和LDA
PCA(主成分分析)和LDA(线性判别分析)有很多的相似点,其本质是要将初始样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
小结
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在我们进行图像识别图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
LDA算法的主要优点有:
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- LDA可能过度拟合数据。
问题回答
图像像素数据,该怎么降维,lda?(还真没怎么实际操作过,都拿来文本聚类了),降维后,运算肯定会优化,但效果是否比linearsvc和svc的直接效果好?
第一个问题: 可以将图像看成一个高维向量, 多个图像就是一个高维空间中的一些点, PCA或者LDA就是把高维向量用高维空间的一组基来表示.
第二个问题: PCA或者LDA将数据降维后保存最重要的信息, 如20维降到10维后, 由于缺少特征, 可能很难达到原来的效果, 但训练效率会大大提高.