定义
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Flume是一个分布式的,可靠可用的系统,用于从很多不同的数据源,高效地收集,聚合并移植大量的日志数据到一个集中的数据存储。
The use of Apache Flume is not only restricted to log data aggregation. Since data sources are customizable, Flume can be used to transport massive quantities of event data including but not limited to network traffic data, social-media-generated data, email messages and pretty much any data source possible.
当然,Flume不仅仅用于数据整合。因为数据源可定制化,Flume可以用于传输大量事件数据,包括但不仅仅限于网络传输数据,社交数据,邮件信息和各种可能的数据。
数据流模型图
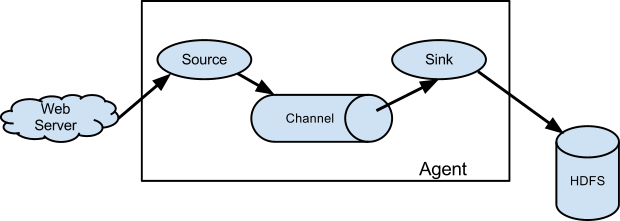
上图中,外部资源发送的数据格式需要跟接受它的flume source 格式一致。
大致流程是:
- Flume source接受外部数据
- 保存事件到一个或多个channel
- Sink会删除channel中的事件并储存数据或者发往下一个flume系统
安装步骤:
运行环境:最新的1.8基于jdk1.8+
- 下载tar包:http://flume.apache.org/download.html
- 解压:tar -zxvf apache-flume-1.8.0-bin.tar.gz
- 配置flume环境变量
vi /etc/profile 添加以下两行(注意PATH之间用冒号分割) export FLUME=/usr/local/flume170 export PATH=$PATH:$FLUME/bin // 环境变量生效命令 source /etc/profile // 校验 flume-ng version - 配置 (路径/usr/local/flume/conf/spool.conf)
// a1 就是agent的名称。可以在一个配置文件中配置多个agent
a1.sources = r1 a1.channels = c1 a1.sinks = k1
# 以下是三个模块(source,channel,sink)的配置 # source配置 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir =/usr/local/flume/logs a1.sources.r1.fileHeader = true # channel配置 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # sink配置 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 -
启动这个agent
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
# 具体到本例,如下:
flume-ng agent -n a1 -c . -f /usr/local/flume/conf/spool.conf -Dflume.root.logger=INFO,console - 确认,向配置的log文件夹添加文件,会出现下面的log
2017-12-07 08:47:25,364 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{file=/usr/local/flume/logs/my.log} body: 48 6F 69 Hoi } 2017-12-07 08:47:25,365 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:324)] Last read took us just up to a file boundary. Rolling to the next file, if there is one. 2017-12-07 08:47:25,366 (pool-3-thread-1) [INFO - org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:433)] Preparing to move file /usr/local/flume/logs/my.log to /usr/local/flume/logs/my.log.COMPLETED
Source的Type有哪些呢?
-
Avro Source
监听avro端口,接收外部avro客户端数据流(二进制数据),配置如下a1.sources.s1.type=avro a1.sources.s1.bind=vm1 a1.sources.s1.port=41414 - Exec Source
启动source的时候执行命令,并期望不断获取数据,比如tail -f命令。配置如下
a1.sources.s1.type=exec a1.sources.s1.command= tail -f /home/flume/a.log - Spooling Directory Source
比Exec Sourc更可靠,监控某个文件夹,将新产生的文件解析成event,解析方式是可插拔的,默认是LINE,将新文件中的每行数据转换成一个event。文件解析完成后,该文件名字被追加.completed。配置如下
a1.sources.s1.type=spooldir a1.sources.s1.spoolDir=/home/flume/a - Netcat Source
类似监听端口数据。类似于nc -k -l [host] [port]命令. 配置如下
a1.sources.s1.type=netcat a1.sources.s1.bind=localhost a1.sources.s1.port=41414 - Sequence Generator Source
不断生成从0开始的数字,主要用于测试。配置如下:
a1.sources.s1.type=seq
- Syslog Source
读取syslog数据,它分为:Syslog TCP Source、Multiport Syslog TCP Source、Syslog UDP Source。配置如下:
a1.sources.s1.type=syslogtcp a1.sources.s1.host=localhost a1.sources.s1.port=41414 - Http Source
通过Http获取event,可以是GET、POST方式,GET方式应该在测试时使用。一个HTTP Request被handler解析成若干个event,这组event在一个事务里。
如果handler抛异常,http状态是400;如果channel满了,http状态是503。
a1.sources.s1.type=http a1.sources.s1.port=41414
参考:
https://cwiki.apache.org//confluence/display/FLUME/Getting+Started
http://flume.apache.org/FlumeUserGuide.html