-
一致性模型
- 弱一致性
- 最终一致性
- DNS (Domain Name System)
- Gossip (Cassandra的通信协议)
- 最终一致性
- 强一致性
-
同步
-
Paxos
-
Raft (multi-paxos)
-
ZAB (multi-paxos)
-
- 弱一致性
-
强一致性要解决的的问题
-
数据不能存在单点上(安全)
-
分布式系统对fault tolorence 的一般解决方案是state machine replication(状态机复制)
-
state machine replication 的 共识(consensus) 算法。
-
paxos 其实是一个共识算法
-
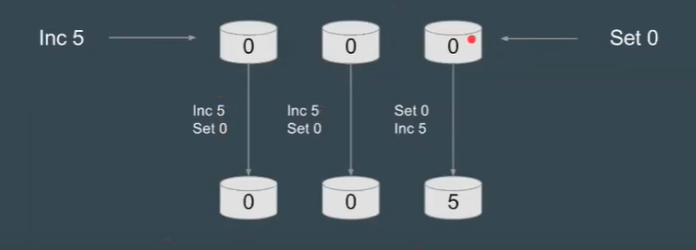
系统的最终一致性, 不仅需要达成共识, 还会取决于 client的行为。
-
假设x为命令
-
Client --(x)--> Consensus Module
x stored in that server's own log(x 存储在该服务器自己的日志中)
Consensus Module --(x)--> Other servers
each of them records the command in their own log(每台服务器都将x存储到自己的日志中)
-
-
-
强一致性算法: 主从同步
- Master 接受写请求
- Master复制日志到slave
- Master等待, 直到所有从库返回
- 可能出现的问题: 一个节点失败, Master阻塞, 导致整个集群不可用, 保证了一致性, 可用性(A)却大大降低
-
强一致性算法: 多数派
-
基本思想: 每次写都保证写入大于 N/2 个节点, 每次读保证从大于 N/2 个节点中读(N 为总节点数)。
-
但是, 在并发环境下, 无法保证系统正确性, 顺序非常重要
-
-
-
强一致性算法: Paxos
-
发明者: Lesile Lamport, 他同时也是Latex的发明者
-
Paxos 分类
-
Basic Paxos
-
角色:
- Client: 系统外部角色, 请求发起者, 类似民众。
- Proposer: 接受Client请求, 向集群提出提议(propose)。并在冲突发生时, 起冲突调节的作用, 类似议员。
- Acceptor(Voter): 提议投票和接收者, 只有在形成法定人数(Quorum, 一般即为majority多数派)时, 提议才会最终被接受, 类似国会
- Learner: 提议接收者, backup, 备份, 对集群一致性没有什么影响, 类似记录员。
-
阶段(phases:):
-
Phase 1a: Prepare
- Proposer 提出一个提案, 编号为N, 次N大于该proposer之前提出提案编号。请求acceptors 的 quorum接受。
-
Phase 1b: Promise
- 如果N大于此acceptor之前接受的任何提案编号则接受, 否则拒绝。
-
Phase 2a: Accept
- 如果达到了多数派, proposer会发出accept请求, 此请求包含提案编号N, 以及提案内容。
-
Phase 2b: Accepted
-
如果此acceptor在此期间没有收到任何编号大于提案, 则接受此提案内容, 否则忽略。
-
也就是说如果在接受到了一个满足的提案后又出现了一个满足的提案, 则会忽略先前的提案, 所以此阶段接收的提案即使满足多数派, 还是可能会失败。
-
-
-
基本流程:
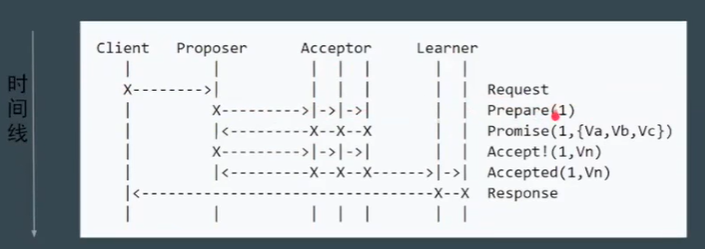
-
Proposer失败
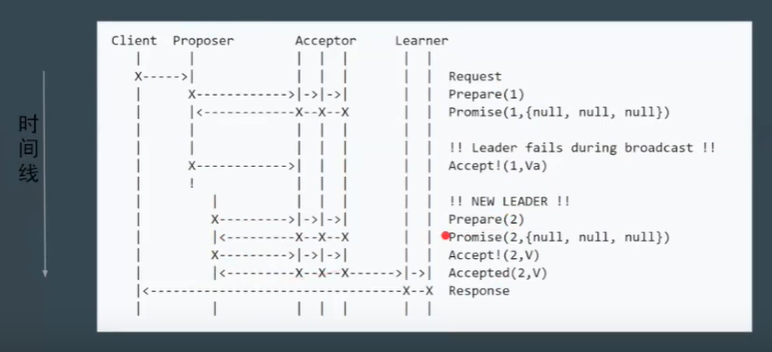
-
潜在问题: 活锁(liveness) 或 dueling
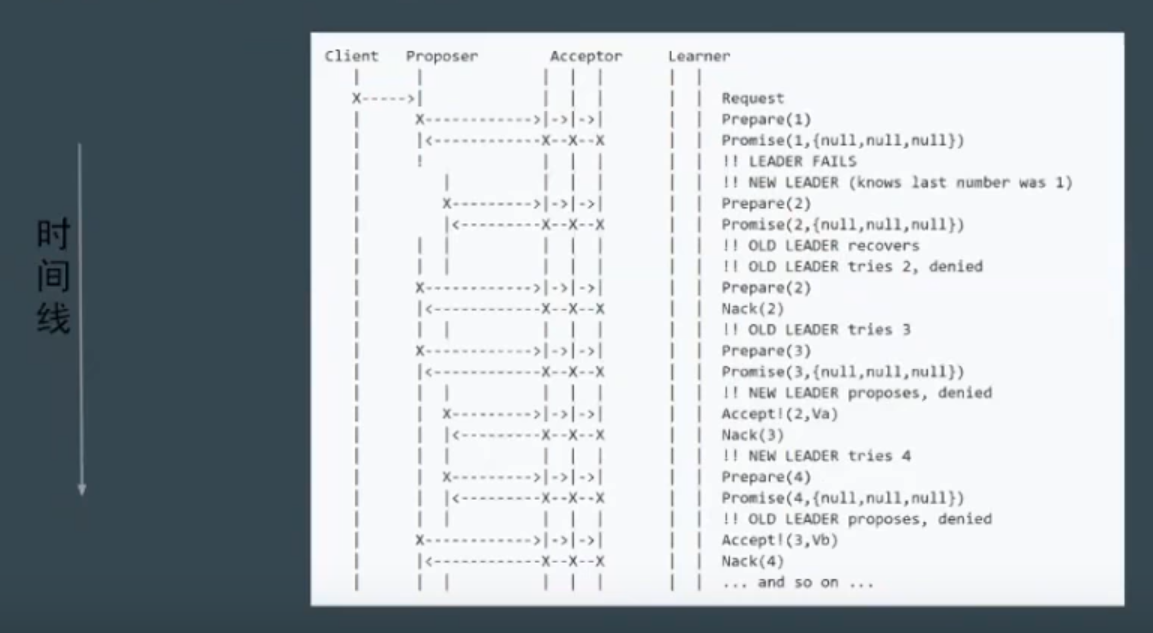
- 简单定义:
- 如果事务T1封锁了数据R, 事务T2又请求封锁R, 于是T2等待。T3也请求封锁R, 当T1释放了R上的封锁后, 系统首先批准了T3的请求, T2仍然等待。然后T4又请求封锁R, 当T3释放了R上封锁之后, 系统又批准了T4的请求, 则T2可能永远等待。
- T2 再不断地获取锁, 我们称此现象为活锁(有时能自己解开)
- 工业上的处理方案:
- 用一个随机的Timeout(延时)
- 简单定义:
-
Basic Paxos的其他问题:
- 难实现, 效率低(2轮RPC)
-
-
Multi Paxos
-
Leader: 唯一的proposer, 所有请求都需要经过此Leader
-
基本流程:

-
减少角色, 进一步简化:
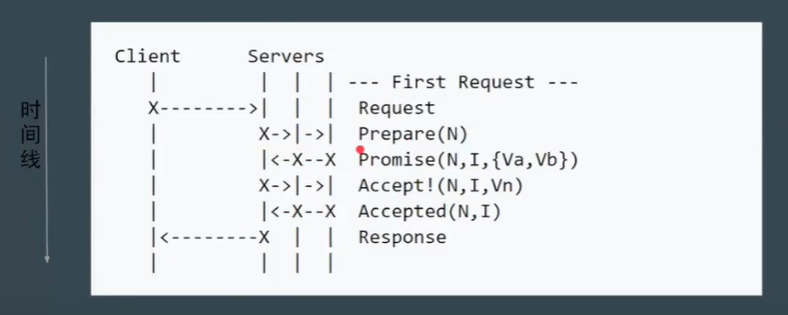
-
-
-
-
强一致性算法: Raft(对Multi Paxos的简化优化)
-
划分成三个子问题:
- Leader Election
- Log Replication
- Safety
-
重定义角色:
- Leader
- Follower
- Candidate
-
整个集群只有一个Leader
-
当Leader存在时, 其他节点为Follower
-
当检测到Leader不存在时, 会有节点进入Candidate状态, 并向其他节点发送请求, 其他节点达到大多数情况就会将该阶段选举
-
节点数量选择为奇数是为了减少网络隔离的影响, 若发生隔离, 总会切出多数一方, 维持集群的运行, 而少数一方在网络恢复后, 会检测并将自己设置为过时, 重置状态。
-
日志提交流程:
- Client发送日志提交请求到Leader
- Leader 发送日志到 Follower
- Follower收到日志后返回信息(先不提交)
- Leader接收到到日志发送成功信息后提交日志
- Leader 直接回复客户端提交成功(异步), Leader 发送提交信息给 Follower, Follower提交后返回已提交信息后Leader再回复客户端则为同步提交。(比如Storm的ack=1 和 ack = all)
-
-
具体可以试试官网的图示: 官网图示
-
实际应用该算法的框架: Etcd
-
-
强一致性算法: ZAB (对Multi Paxos的简化优化)
- 基本与raft相同
- 某些名词叫法上有区别: 比如ZAB将某一个leader的周期称为epoch, 而raft则称之为term
- 实现上也有些许不同: 比如raft保证日志连续性, 心跳方向为leader至follower。ZAB则相反。
- 实际应用该算法的框架:Zookeeper