SpringHadoop是通过Spring框架来调用hdfs,跟直接调用hdfs的最大的不同区别是Spring通过依赖注入的方式生成操作hdfs所需要的configuration和filesystem对象,其他所有调用hdfs的api不变
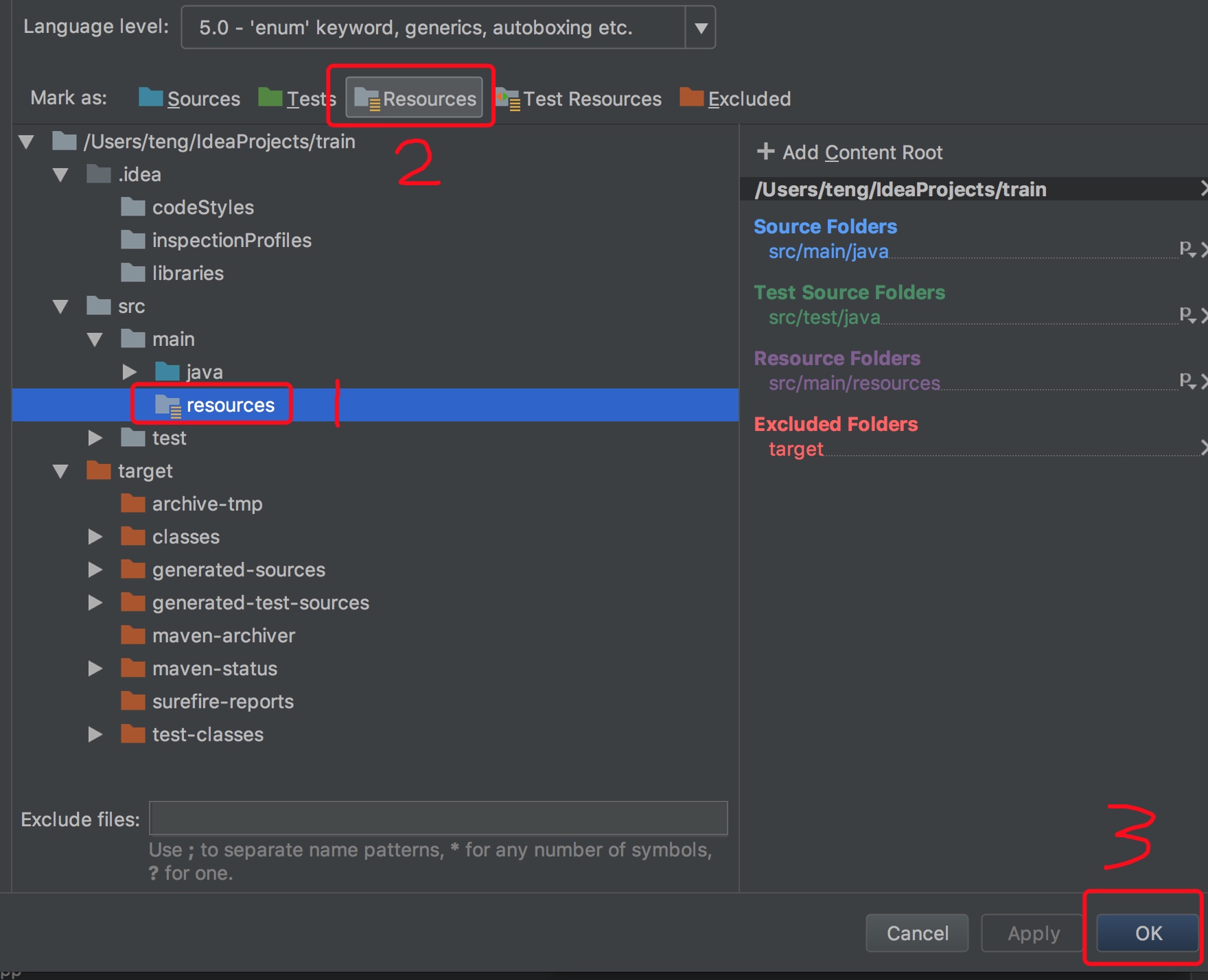
1.在项目的main目录下创建resources文件夹,并将其添加到项目的资源文件中,如图

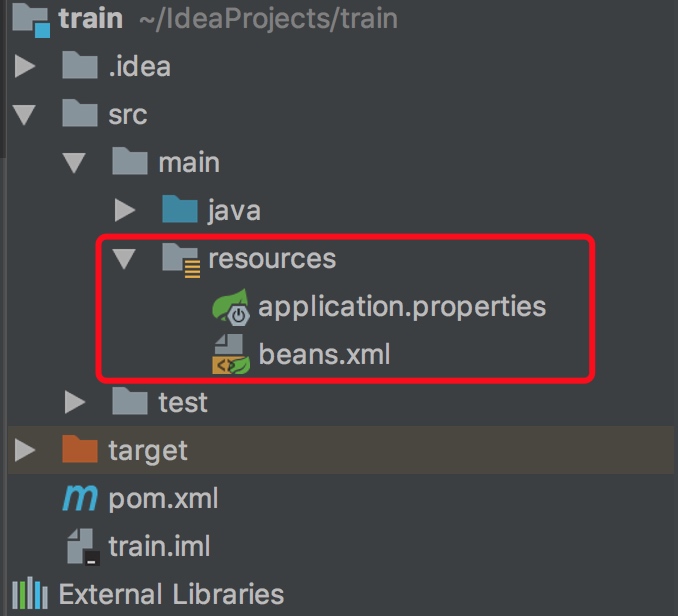
2.在resources文件夹下创建beans.xml和application.properties文件,分别用来注入对象及管理配置文件

3.添加hadoop和spring-hadoop的依赖
<!--在这里可以定义变量,可以统一管理版本号-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--对hadoop版本进行统一管理-->
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<repositories>
<!--添加下载hadoop的仓库-->
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
</repositories>
<dependencies>
<!--添加hadoop依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<!--由于生产环境上已经有这个包,因此不需要打到项目里去-->
<scope>provided</scope>
</dependency>
<!--添加spring-hadoop依赖-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-hadoop</artifactId>
<version>2.5.0.RELEASE</version>
</dependency>
</dependencies>
4.配置beans.xml和application.properties文件中的configuration和filesystem对象
beans.xml文件
<!--将属性配置文件application.properties引用进来,这样在该xml文件就可以使用该配置文件里面的属性-->
<context:property-placeholder location="application.properties"/>
<!--配置hdfs的configurtion-->
<hdp:configuration id="hadoopConfiguration" >
<!--配置namenode的地址-->
fs.defaultFS=${spring.hadoop.fs-uri}
</hdp:configuration>
<hdp:file-system id="fileSystem" configuration-ref="hadoopConfiguration" user="root"/>
application.properties文件
spring.hadoop.fs-uri=hdfs://hadoop01:8020
5.最后是java单元测试代码
package spring;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.io.IOException;
/**
* @author ht
* @create 2018-01-30 23:03
* @desc SpringHadoop测试类
**/
public class SpringHadoopApp {
//Spring上下文
private ApplicationContext mContext;
//hdfs文件系统对象
private FileSystem mFileSystem;
/**
* 测试创建文件夹
*/
@Test
public void mkdir() throws IOException {
mFileSystem.mkdirs(new Path("/test"));
}
/**
* 测试从服务器读取文件
*/
@Test
public void text() throws IOException {
FSDataInputStream is = mFileSystem.open(new Path("/test/install.log.syslog"));
IOUtils.copyBytes(is,System.out,1024);
is.close();
}
@Before
public void setUp() {
//获取Spring上下文,spring的依赖注入,是将对象注入到beans中,类似dagger2中的moudle,专门负责生成对象
mContext = new ClassPathXmlApplicationContext("beans.xml");
//通过beans.xml文件获取filesystem对象
mFileSystem = (FileSystem) mContext.getBean("fileSystem");
}
@After
public void tearDown() throws IOException {
mContext = null;
mFileSystem.close();
}
}