用fork()函数建立的子进程几乎与父进程完全一样,子进程中的所有变量均保持他们在父进程中的值(当然fork的返回值除外),因为自己称可用的数据是父进程可用数据的拷贝,并且其占用不同的内存地址空间(当然逻辑地址可能是一样的),这就保证了在一个进程中的变量数据变化不会影响到另外一个进程。这一点非常重要。
但是有一点要特别注意的,在父进程打开的文件,那么在子进程中也会打开,继承了打开的文件描述符,但是子进程与父进程共享文件表,所以有一个进程中的文件偏移量发生变化就会直接影响到另外一个进程,详细解释如下。
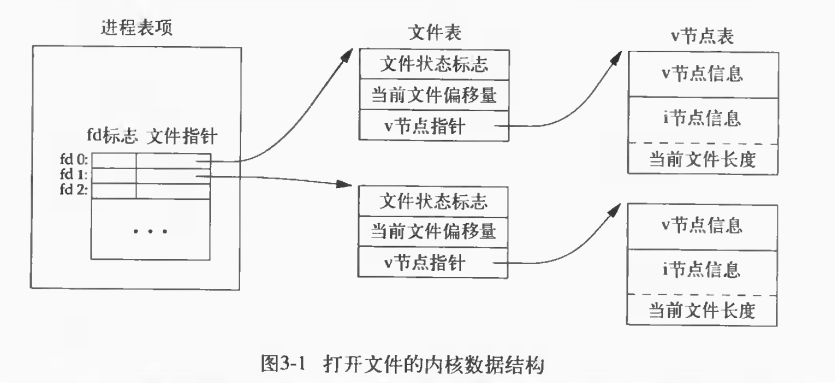
从图3-1我们可以知道,对于每个进程都有对打开的文件的记录表,其中每个记录项都记录着每个文件描述符的信息,通过该记录项的我们就可以文件表的指针,我们就可以在文件表中找到相对应的文件表项,每个文件表项记录着打开的该文件的状态以及当前文件的偏移量信息。当我们在父进程中建立一个子进程,那么现在的打开文件的结构图如8-1所示:(注:此图粘贴自http://blog.csdn.net/caigen1988/article/details/7736565)
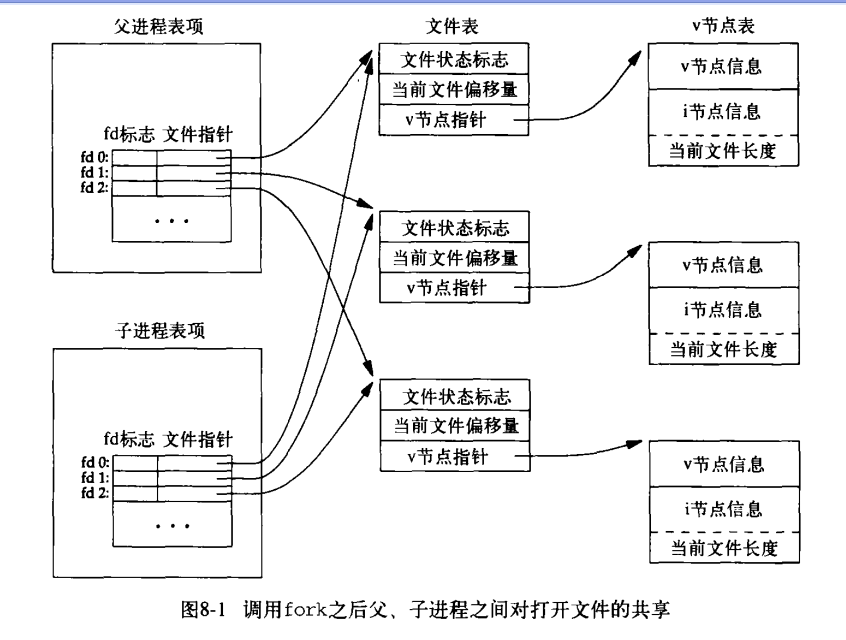
那么从中可以看出,虽然在子进程的表项中是复制了关于打开文件的信息,但是他们是共享文件表的,所以如果一个进程对文件指针进行移动,那么肯定会影响到另外的进程。
如果父、子进程写到同一个文件描述符,但有没有任何形式的同步,那么它们的输出就会相互混合。在fork之后处理文件描述符有两种常见的情况:
(1)父进程等待子进程完成。在这种情况下,父进程无须对其描述符做任何处理。当子进程终止之后,它曾进行过读、写的人一个共享描述符的文件偏移量已经执行了相应的更新。
(2)父、子进程各自执行不同的程序段。这种情况下,在fork之后,父、子进程各自关闭它们不需使用的文件描述符,这样就不会干扰对方使用的文件描述符。这种方式是网络服务进程中常用的方式。