ElasticSearch 2 (7) - 基本概念
摘要
ElasticSearch的一些基本核心概念,理解这些概念有助于ElasticSearch的学习
- 准实时NRT(Near Realtime)
- 集群
- 节点
- 索引
- 类型
- 文档
- 分片与副本(Shards & Replicas)
版本
elasticsearch版本: elasticsearch-2.2.0
概念
准实时NRT(Near Realtime)
ElasticSearch是一个准实时的搜索平台。准实时的意思是说它的延迟非常小,从为一个文档建索引到这个文档可以搜索出来,只需要1秒的时间。
集群(Cluster)
一个ES集群可以由一个或者多个节点(nodes or servers)组成。所有这些节点用来存储所有的数据以及提供联合索引,为我们提供跨节点查询的能力。一个ES集群的名称是唯一的,默认情况下为“elasticsearch”。这个名称非常重要,因为一个节点(node)会通过这个名称来判断是否加入已有的集群。
必须保证在不同环境下使用不同的集群名称,否则节点可能会加入错误的集群。比如我们可以为开发环境(development)、测试环境(staging)、产品环境(production)分别给出不同的集群名称:logging-dev、logging-staging、logging-prod。
需要注意的是我们也可以使用一个只有一个节点的集群,或者我们也可以有不同的集群,每个集群都有自己唯一的名称。
节点(Node)
一个节点是一个集群中的一台服务器,它用来存储数据,参与集群的索引以及提供搜索能力。如ES集群,一个节点也是由它的唯一名称来标识,默认状态下,ES会为在启动时随机为一个节点给定一个以漫威Marvel人物的名字为之命名,当然我们也可以为节点指定任何我们想指定的名称。这个名称对于管理ES集群非常重要,我们用它来定位网络或集群中的某一节点。
一个节点可以通过指定集群名称让它加入某个集群,默认情况下,每个节点都会加入到一个名为“elasticsearch”的集群中,也就是说,当我们在某一网络下启动一定数量的ES节点时,我们认为他们可以相互发现同一网络下的其他节点。
在单集群下,我们可以有任意数量的节点,如果当前网络下没有任何ES节点,那么在启动节点后,当前节点会默认形成一个单节点集群,名称为“elasticsearch”。
索引(Index)
一个索引是一组具有相似特性的文档的集合。例如,可以为客户数据(customer data)建立索引一个索引,也可以为产品目录(product catalog)建立另一个索引,还可以为订单数据(order data)建立另一个索引。一个索引由它的名称唯一标识(必须所有字母为小写字母),这个名称会在进行索引(indexing)、搜索(search)、修改(update)和删除(delete)操作的时候使用。
在一个单集群下,我们可以定义任意多的索引。
类型(Type)
在一个索引下,我们可以定义一个或多个类型(types)。一个类型是一个索引逻辑分类或分区(category/partition),而分类或分区的划分方法由我们自己决定。通常情况下,我们会为具有相类似的字段的一组文档定义类型。比如,如果我们运行一个博客平台,所有的数据都使用同一索引,我们为用户数据定义一种类型,为博客数据定义另一种类型,同时为评论数据定义另一种类型。
文档(Document)
一个文档是一个可以被索引的基本信息单元。比如,一个用户可以是一个文档,一个产品可以是一个文档,一个订单同样也可以成为一个文档。这个文档以JSON格式表示。
分片与副本(Shards & Replicas)
一个索引可能会存储大量数据从而超过单个节点硬件的限制。例如,单个索引可能会有上亿的文档占用1TB的磁盘空间,这对于单个节点来说太大,同时使用单个节点也会是搜索变慢。
为了解决这个问题,ES提供了一种分片(shard)能力,让我们将一个索引切分成片。当我们创建一个索引时,我们可以为它指定分片的数量。每个分片自己都能独立工作,并且存在与集群的任一节点中。
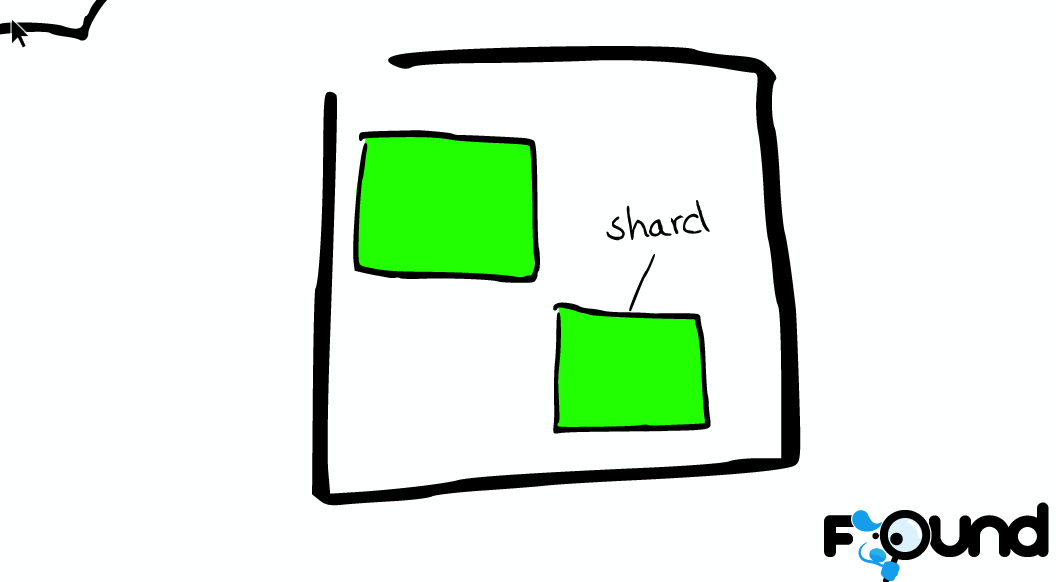
分片的重要性主要体现在以下两个原因:
- 可以水平分割或扩展内容体量。
- 可以分布式和并行的方式在多个分片上进行操作(多个节点)从而提高性能和吞吐量。
一个分片是如何散发的,如何将它的文档聚合并返回个查询是对用户透明的,这个过程完全由ES来管理。
在网络或云的环境下,错误可以在任何时候发生,当一个分片或节点因为某种原因下线或消失时,一个错误恢复机制就非常重要。为了解决这个问题,ES让我们可以为一个索引分片创建一个或多个拷贝,这个拷贝称作副本分片,简称为副本。
副本的重要性主要体现在以下两个原因:
- 当一个分片或者节点出错时,集群任然可用。正因如此,我们会发现一个分片副本从来不会在它的原始分片或主分片所在的节点出现。
- 横向扩展搜索体量和吞吐量,因为搜索可以在所有副本上并行执行。
总之,每个索引都可以分为多个分片,一个索引也可以被复制到零个或多个副本。一旦发生复制,每个索引都会有主分片(primary shards)和多个副本分片(replica shards)。分片数和副本数可以在一个索引创建时指定。当索引创建以后,可以动态的改变副本数,但是不能改变分片数。
默认情况下,每个ES索引都有5个主分片(primary shards)和1个副本(replica),也就是说当我们的集群有两个节点时,我们的索引会有5个主分片和另外5个副本分片,也就是说每个索引有总共10个分片。

注意
每个ES分片都是一个Lucene索引。对于单个Lucene索引,文档的最大数有一个限制,2,147,483,519。即(= Integer.MAX_VALUE - 128)。可以通过
_cat/shards
来查看。

Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. As of LUCENE-5843, the limit is 2,147,483,519 (= Integer.MAX_VALUE - 128) documents. You can monitor shard sizes using the _cat/shards api.
参考
参考来源:
https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html
图片来源:
https://www.youtube.com/watch?v=LDyxijDEqj4