本文大纲
- 进程与线程
- Python的GIL
- 多线程编程及线程间通信
进程与线程
程序就是一堆代码也就是在磁盘上的一个或多个文件。当程序运行起来也就被加载到内存中开始执行它的指令这时候才是真正的进程。运行中的QQ、Word就是一个进程。
那线程又是什么呢?无论怎么说一个进程至少包含一个线程作为它的指令执行体,线程你可以理解为进程中要执行的一个任务,那么其实进程可以包含多个任务,可是在单核心CPU的时代这些任务只能顺序执行,哪怕这些任务是独立的。比如Word的自动保存功能,你在编写文档时定期会自动保存这时候其实就是一个线程执行了这个任务。
进程管理资源而将线程分配到某个cup上执行,也就是说线程是CPU调度的最小单位。一个进程可以拥有多个线程,如果进程运行在多核心CPU上,那就可以把多个线程分配到多个核心上去执行,最大化并行处理。就算是单核心CPU也可以通过模拟出来并行(CPU时间片概念),虽然这带来更多上下文切换但是线程的切换比进程的切换开销要小的多,因为除了CPU资源之外其他的资源进程内的线程都是共享的。
注意:线程分为内核线程和用户线程,区分标准就是线程的调度者在核心内部还是外部。内核线程更利于并发使用多核心处理器的资源,而用户线程更多考虑的是上下文切换开销。目前主流操作系统中都是两者结合使用只是组合会有差异。我们这里说的多线程或者多进程其实是用户线程,无论你是用Python还是Java编写的程序。
场景描述
单进程模型:
比如一个WEB服务器,进程正在运行,监听在某一个端口,这时候如果有一个用户请求,那么是不是应该让这个进程来处理呢?可以,但是一般不会这么做,因为如果来了第二个请求,显然之前那个进程还在处理第一个请求,根本无法处理第二个。所以不会让那个进程来处理,而是基于它产生一个子进程,让子进程来处理,这样看似问题解决了,但是你想,来10个请求我可以产生10个子进程,如果来1万呢?比如一个子进程消耗1M内存,那么这就要消耗将近10G内存,这显然不可接受,这还没有考虑产生一个子进程的其他系统开销,如果每个进程都访问主页,那么就要把主页数据加载到内存,如果一个主页消耗2M内存,那么1个请求就要占用1万个2M内存空间,加上之前的1M,总量就将近30G。如果CPU只有一颗的话,那性能将会非常糟糕,会有频繁的CPU切换。
单进程多线程模型:
上面是进程模型,如果改用线程模型的话效率会大大提高,一个父进程生产一个子进程,一个子进程内部产生多个线程,因为产生一个线程基本没有什么内存占用或者是非常小(CentOS的默认线程栈8K),而且线程是可以共享进程资源的,还是上面的例子,只需要打开一次2M的主页,1万个请求共享这一个,这就大大节约了内存空间。但是如果你还是只有一个CPU的话,那么还是无法实现多个线程同时运行,依然存在切换问题。如果是多核心则会更好,如果还没有资源征用(典型的场景就是A线程要读取一个正在被B线程写入的文件)那么效果会更好。
任务可以分为计算密集型和IO密集型。前者主要是大量占用CPU后者主要是访问磁盘或者网络请求等。上面的两个例子其实是IO密集型,会有大量用户请求发送到服务器,这种任务类型如果不使用多线程那么就需要使用多路复用。典型的就是Nginx。
Python中的GIL
Python代码的执行是由python解释器(解释器主循环)进行控制的。在主循环中同时只能有一个控制线程在执行,就像单核心CPU中的多进程一样。尽管Python解释器中可以运行多个线程,但是在任意某一时刻只能有一个线程在运行。
GIL:全局解释器锁,这个是进程级别的,进程里面任何的线程要想被执行都要经过这个锁,这就意味着进程内多个线程同一时刻只能有一个线程被执行其他都睡眠或者等待IO,哪怕你有多个核心的CPU也不行,简单来说就是Python中的线程不是并发的,在JAVA中线程可以并发。这个锁曾经尝试去掉过但是去掉之后导致单线程程序性能下降很多,虽然去掉会带来多线程的性能提升但是经过权衡觉得不值得,最后还是加上了。Python为什么一开始不设计真正的多线程?这个跟年代有关Python诞生在1989年,那个年代INTEL才推出80486其实就是80386的加强版,别多多核心,也就是刚刚加入了浮点运算,当然同期摩托罗拉的CPU也不是多核心。而JAVA是1995年诞生,那时候虽然也没有多核心但是性能要高的多,单核心性能高了我们就可以利用CPU时间片概念模拟多线程并发;另外就是我们常用的Python是CPython解释器是C写的它的多线程依赖操作系统,这种Python有GIL,如果是JPython或者PYPY则没有GIL限制,所以所GIL不是语言决定的,而是执行这个语言的解释器决定的。另外Python的进程也是依赖操作系统的,调用操作系统的库函数实现的,进程没有GIL限制。
那么这里就涉及到一个问题,如果一个多线程程序,其中一个线程等待IO(网络或者磁盘)时间很长那么其他线程就一直阻塞在哪里吗?显然不是,那如何处理的呢?一个线程无论任何时候开始睡眠或者等待IO,其他线程都有机会获取GIL然后执行自己的Python代码,这就是协同式多任务处理,另外Python还支持抢占式多任务。
协同时多任务
比如当一个线程进行网络IO操作时,其实无法估计这个IO需要多久,此时这个线程就阻塞在这里并且没有运行任何Python代码,那么这个线程就会释放GIL(被解释器强制释放),从而让其他线程获取GIL来运行他们的Python代码。这就是协同式多任务,它允许并发;多个线程同时等待不同事件。
比如2个线程打开2个套接字,两个线程同一时刻只能有一个执行Python,但一旦线程开始连接它就会放弃GIL,这样其他线程就可以运行,这就意味着2个线程并发等待套接字连接。其实你可以看到它允许顺序的并发等待,当IO有返回时也就是它需要重新获得锁来执行Python代码的时候,在这个时间片里只能有一个线程运行。
协同时多任务也叫做协作式多任务,本意是指程序或者线程自己控制执行时间,A线程执行完了就通知B线程,看起来很完美但是如果A线程代码有问题导致无法正常执行完毕那后面的线程就都卡死了。在Python中解释器就充当了那个中间人的作用它保证某个线程卡死不会一直占用CPU。
抢占式多任务
抢占式顾名思义就是进程或者线程可以在执行时被任意打断也就是被别的线程或者进程抢去它的执行时间。抢的机制避免了代码问题线程卡死但是也带了其他问题就是所有线程或者进程的执行时间无法公平。
上面说的是线程主动放弃锁,那么对应的就有主动获取锁,当多个线程都有返回的时候(所有线程都处在一个可以继续执行的状态),就会发生对锁的争抢(抢GIL)。总之最终只有一个线程被运行。假设有一个获取锁的线程继续执行但是它的数据有问题导致线程变成死循环那后面的线程是不是就无法运行了呢?答案是否定的。Python代码执行首先会被翻译成二进制字节码,然后解释器函数读取这些二进制码然后执行,在Python 2 中检测间隔为在虚拟机中运行的字节码数量达到一定值就强制线程释放GIL,在Python 3.2及以后改变了GIL的释放和获取机制,默认是0.005秒也就是5毫秒换句话说如果一个线程5毫秒没有释放锁就被强制释放,也就是说结解释器会主动定期轮询所有线程而不会让一个线程一直运行。那这个GIL能保证线程安全吗?
Python的线程安全
一个线程可以随时失去GIL那么可以得出GIL是无法保证线程安全的,从开发这角度来说程序是一条一条执行,但是翻译成字节码我们看起来的一条语句可能是多条尤其是对于原子性操作。比如 += 这样的操作,看下图

无论是GIL是按照字节流多少还是按照时间,假设刚执行了上面0、3操作就需要释放GIL,那么后去的6、7则无法执行,相当于 += 操作没有完成。所以作为开发人员仍然需要手动加锁。我这里的例子并没有加循环进行累计虽然发生概率不高,但是也要引起注意。下图为手动加锁:
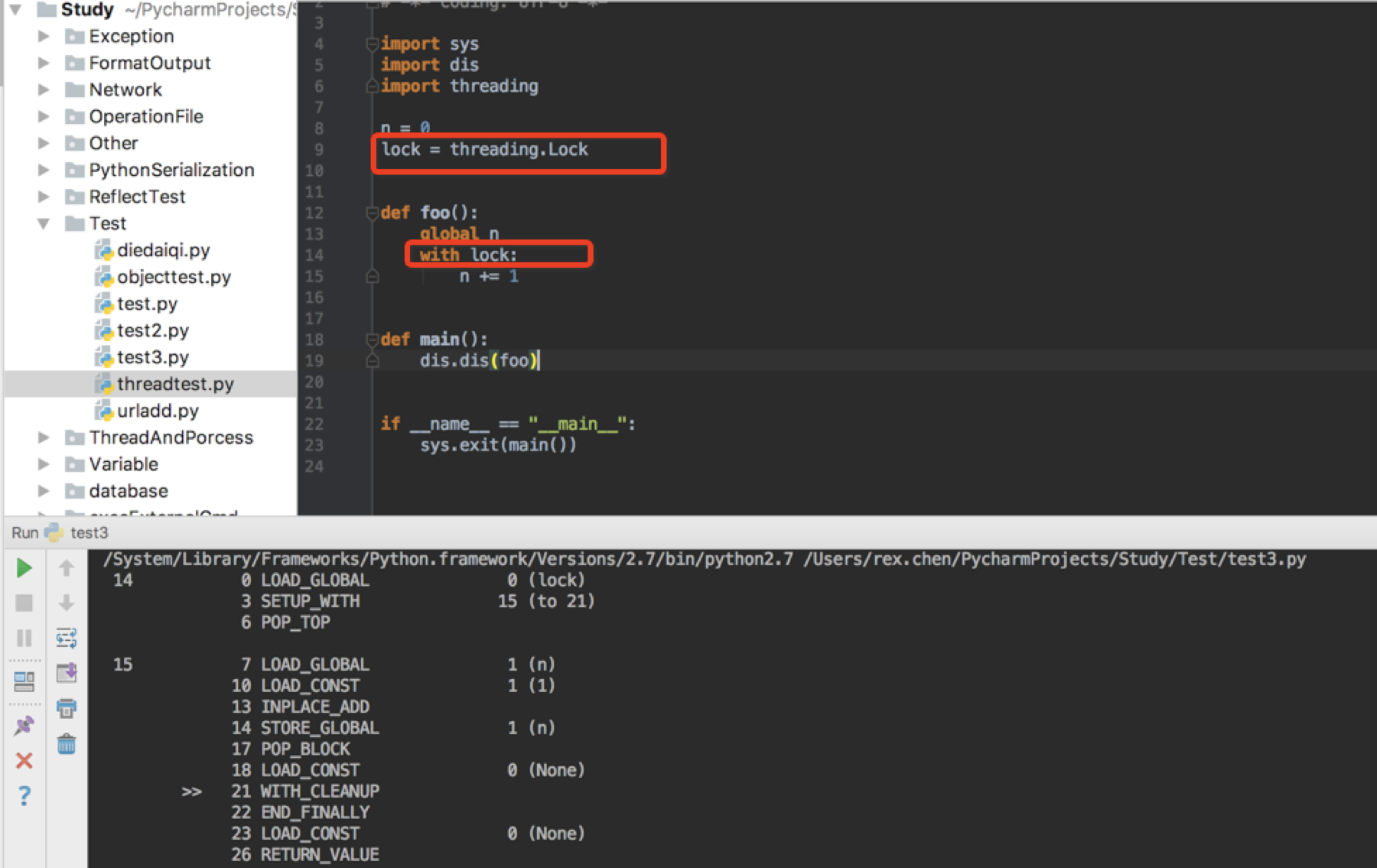
那么对于原子性操作比如sort()方法,是不能被中断的即使到了该是否GIL的时候。因为sort是单字节码,因此线程没有机会在调用期间抓取GIL。有时候你分不清哪些是原子的哪些不是,所以可以遵循一个原则:始终围绕共享可变状态的读取和写入加锁。反正threading.Lock是廉价的。
如果你使用JAVA语言则需要程序员自行加、解锁来保证线程安全。在Python中是粗粒度锁,也就是语言本身就提供一种机制来保证线程安全。所以在Python中除了特殊需要一般情况下没必要使用更加细粒度的线程锁。
从上面来看可以更加详细的了解Python多线程,而不是一味的认为它的多线程没有意义。所以如果真的需要并行计算呢?答案就是多进程,那么到底具体什么场景需要使用多线程什么时候多进程呢?
计算密集型:要用多进程,大量使用CPU计算能力的程序或者任务,而进程本身不太去访问IO设备。比如计算圆周率、对视频进行解码、解压缩和压缩、加密解密。虽然多进程会更叫消耗资源,但是可以更多的利用CPU核心的计算能力。
IO密集型:要用多线程,因为IO操作不占用CPU能力,所以不用利用CPU的多核心。IO分为网络IO和磁盘IO,就是CPU的等待时间主要消耗在等待输入和输出上,比如网络爬虫这种类型属于IO密集型,在一个线程等待IO的同时会放弃GIL,然后让后面的线程工作,这显然比单线程要效率高。
从运算结果来看GIL不能保证线程安全
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com import multiprocessing import threading import time def foo(n): # print(n) global count count += 1 time.sleep(1) count -= 1 print("子进程 %d 执行完毕。" % n) count = 0 def main(): thList = [] for i in range(200): t = threading.Thread(target=foo, args=(i,)) t.start() thList.append(t) for t in thList: t.join() print(count) print("主线程执行完毕") if __name__ == '__main__': main()
如果是线程安全的那么结果就是0,可是真的结果呢?不一定是多少,我这次执行的是6,如果你不在count += 1和 -= 1之间加睡眠你是看不到效果的。如果你没有count -= 1这一步,你是看不到效果的,因为虽然你用sleep模拟了执行时间长来触发线程之间的GIL释放和获取但是你要明白 count += 1这个是一个完整操作在睡眠前就已经执行完毕了,所以是否睡眠与结果毫无相关,所以必须是两次对同一数据进行操作然后两次操作中间增加睡眠时间来触发线程释放GIL才能有直观的效果。

如果要想保证线程安全怎么办呢?用锁

这样就保证了结果,上例子中应该去掉sleep,因为这样程序就是串行的了,但是如果面对这种根本无法触发释放GIL锁的操作,你不加睡眠的话人为加锁对执行结果没有影响。锁和信号量会在后面讲到。
多线程编程及线程间通信
在Python中有两个模块可以实现线程,就是thread模块和threading模块的Thread类。thread可以实现的功能threading也可以实现,可以把threading看做高级的thread,在做多线程编程的时候推荐使用threading,所以我这里也只用这个来举例。
我们先说一下创建线程的方法:
- 创建线程实例,然后传给它一个函数
- 创建线程实例,然后传递给它一个可调用的类(也就是实现了类里的__call__方法)
- 派生线程子类,实现run()方法,然后基于子类创建实例并运行它
三种方法用哪一个呢?总之不推荐使用第二种因为难以阅读。如果是简单任务第一个种就够了,如果是复杂程序就要遵循面向对象编程思想那么第三种更合适。
我们先用第一种方法来创建
(例子1)
#!/usr/bin/python # -*- coding: UTF-8 -*- import sys from time import sleep from threading import Thread # 测试使用 被线程执行的方法 def foo1(arg): print("子线程任务-获取的参数值为:", arg) sleep(2) print("子线程任务执行完毕。") def simpleExample(): """ 创建一个线程实例,然后传递一个需要线程执行的函数 target=foo1 传递一组参数给需要执行的函数,形式为元祖,如果没有参数就使用空元祖 args=(1,) 还可以设置线程名称,当然不是必须的,如果不设置线程名称以 Thread-开头后面跟一个数字,默认从1开始 设置线程名称还可以使用 Thread.name = "子线程" 不推荐使用 .setName和.getName来设置和获取线程名称 """ t1 = Thread(target=foo1, args=(1,), name="子线程") # 启动线程 t1.start() # 获取线程名称 print(t1.name) """ 获取线程是否还存活,线程执行完毕后,也就是返回了,那么这个值就是False。线程一旦start()那么就是活着的, 所以线程是在start到返回之间是存活的。 """ print("线程是否还活着:", t1.isAlive()) print("主线程代码执行完毕。") def main(): simpleExample() if __name__ == "__main__": sys.exit(main())

这个程序很简单就是传递一个函数去执行。当线程执行时,主线程继续执行直到执行完所有主线程代码,从上图可以看出“子线程任务执行完毕”是最后一个输出,这个是子线程输出的。这时候你可能回想,上面的主线程不等子线程完成它自己的代码就执行完了,如果我的主线程需要获取子线程执行结果然后再继续运行主线程怎么办?看下面的代码
下面的代码是创建5个子线程,然后每个子线程都在一个列表里写上自己的名字,然后主线程显示这个列表。
(例子2)
#!/usr/bin/python # -*- coding: UTF-8 -*- import sys from time import sleep from threading import Thread def foo2(arg, name): arg.append(name) sleep(2) print("子线程: %s 任务执行完毕。" % name) def aboutJoin(): namelist = ["Thread-A", "Thread-B", "Thread-C", "Thread-D", "Thread-E"] threadlist = [] testlist = [] for i in namelist: t = Thread(target=foo2, args=(testlist, i), name="子线程-" + str(i)) t.start() threadlist.append(t) # for i in namelist: # threadlist[namelist.index(i)].start() for i in namelist: """ 线程启动后阻塞主线程,主线程需要等待线程完成后才可以继续执行(join后面的语句),你在线程调用的方法中加入sleep效果最明显。 你不加阻塞其实不影响运行,只是输出信息会乱因为主线程会继续执行,线程也会执行,那具体调度执行顺序由系统控制, 所以不加阻塞每次输出的信息前后顺序会不一样。 join(timeout),它可以加一个超时,不加就是等待线程执行完毕,加超时则是等待多久无论线程是否执行完毕都向后继续执行主线程。 """ threadlist[namelist.index(i)].join() for i in testlist: print(i) print("主线程代码执行完毕") def main(): aboutJoin() if __name__ == "__main__": sys.exit(main())
说明:上面那一段注释的代码是启动线程,我写的是创建时线程实例就启动,其实你可以先全部创建(创建后并不马上调用start),然后在启动(用注释的代码)。

从执行结果来看,主线程等待所有子进程完毕,然后输出那个列表,当主线程执行完最后一条代码后,程序退出。
守护线程
thread模块不支持守护线程,所以我们必须是用threading模块。守护线程的意思是当主线程退出时所有子线程也将终止,无论子线程的任务是否完成。守护线程一般用来做那些不重要的任务,比如等待客户端请求,如果没有请求那么这个线程就是空闲的。它只负责接收请求然后把请求转发给其他线程来处理,然后自己继续等待请求。所以对于这种不具有重要逻辑处理的线程可以作为守护线程。换句话说主线程活着守护线程就活着,主线程没了守护线程也就没了。
有人说把处理客户请求的线程弄成守护线程,这也是可以的,但是有个问题,如果要重启应用或者手动停止服务,当前没有处理完请求的那些线程难道直接终止吗?留给大家思考,不过很多人也应该听过优化停机这种说法,在这种场景下执行了停止服务操作,可以不再接收新的请求,但是要处理完老的请求。
(例子3)
#!/usr/bin/python # -*- coding: UTF-8 -*- import sys from time import sleep from threading import Thread def foo3(arg, name): sleep(2) arg.append(name) print("子线程: %s 任务执行完毕。" % name) def demoForDaemon(): namelist = ["Thread-A", "Thread-B", "Thread-C", "Thread-D", "Thread-E"] threadlist = [] """ 创建5个线程,然后它们设置为守护线程,这时候你会发现主线程很快执行完毕然后程序退出 这时候你看不到任何线程输出内容。因为所有线程都随主线程的退出而退出了。但是如果你注释掉 subT.daemon = True 你会发虽然主线程代码执行完毕但是不会退出,它会等着线程,然后你就看到输出的列表. 如果把线程设置为守护线程则表示这个线程其实不重要,进程退出时可以不需要管这个线程是否执行完了自己的代码。 """ for name in namelist: subT = Thread(target=foo3, args=(threadlist, name)) """ 这个值默认是False,这个是设置子线程为守护模式,就是说主线程是不是等待线程执行完毕在退出。 比如你设置了True,也就是主线程不等待,那么如果主线程执行代码需要1秒钟,而线程执行它里面的代码 需要10秒,那1秒过后主线程执行完毕退出,线程也会随之退出这时候线程的代码根本没有执行完。通常来讲 主线程产生的所有线程都应该随主线程退出而销毁,这样就可以避免线程出现死循环主线程退出了子线程还在继续执行的情况。 必须在start()方法之前设置。 """ # subT.daemon = True subT.start() # 这个指令是为了演示虽然把主线程设置为所有线程的守护进程,但是因为睡眠了所以主线程没有退出,这时候 # 你就会看到线程的正常输出,至于线程是否执行完毕则取决于主线程什么时候退出,这里设置睡眠可以理解为 # join()操作。只不过你不能真的当join()来使用,毕竟真实场景中子线程的执行时间不可预知。 # sleep(5) print(threadlist) print("主线程代码执行完毕。") def main(): demoForDaemon() if __name__ == "__main__": sys.exit(main())

下面开启daemon
(例子4)
#!/usr/bin/python # -*- coding: UTF-8 -*- import sys from time import sleep from threading import Thread def foo3(arg, name): sleep(2) arg.append(name) print("子线程: %s 任务执行完毕。" % name) def demoForDaemon(): namelist = ["Thread-A", "Thread-B", "Thread-C", "Thread-D", "Thread-E"] threadlist = [] """ 创建5个线程,然后它们设置为守护线程,这时候你会发现主线程很快执行完毕然后程序退出 这时候你看不到任何线程输出内容。因为所有线程都随主线程的退出而退出了。但是如果你注释掉 subT.daemon = True 你会发虽然主线程代码执行完毕但是不会退出,它会等着线程,然后你就看到输出的列表. 如果把线程设置为守护线程则表示这个线程其实不重要,进程退出时可以不需要管这个线程是否执行完了自己的代码。 """ for name in namelist: subT = Thread(target=foo3, args=(threadlist, name)) """ 这个值默认是False,这个是设置子线程为守护模式,就是说主线程是不是等待线程执行完毕在退出。 比如你设置了True,也就是主线程不等待,那么如果主线程执行代码需要1秒钟,而线程执行它里面的代码 需要10秒,那1秒过后主线程执行完毕退出,线程也会随之退出这时候线程的代码根本没有执行完。通常来讲 主线程产生的所有线程都应该随主线程退出而销毁,这样就可以避免线程出现死循环主线程退出了子线程还在继续执行的情况。 必须在start()方法之前设置。 set/getDaemon() 方法已经过时,不推荐使用了. """ subT.daemon = True subT.start() # 这个指令是为了演示虽然把主线程设置为所有线程的守护进程,但是因为睡眠了所以主线程没有退出,这时候 # 你就会看到线程的正常输出,至于线程是否执行完毕则取决于主线程什么时候退出,这里设置睡眠可以理解为 # join()操作。只不过你不能真的当join()来使用,毕竟真实场景中子线程的执行时间不可预知。 # sleep(5) print(threadlist) print("主线程代码执行完毕。") def main(): demoForDaemon() if __name__ == "__main__": sys.exit(main())

线程安全
之前说过GIL并不能保证线程安全,那在某些场景下又需要线程安全,那应该怎么做呢?通常有两种方式,锁和信号量。在说这两个东西之前,先说两个概念
- 临界资源:是同一时刻仅允许一个进程/线程使用的共享资源。各进程/线程采取互斥的方式,实现共享的资源称作临界资源。临界资源是资源。
- 临界区:每个进程/线程中访问临界资源的那段代码称为临界区。临界区是代码。
简单来说多个线程/进程同一时刻可能对同一个资源又添加又修改或者是仅修改可是每次修改的数量不同。典型场景就是购物,多个人购买一个商品,但是商品库存是一定的,可是每个人买的数量不同。控制不好可能会出现销售数量大于库存数量。
锁
模拟用户抢购商品,在扣减库存的时候进行锁定,扣减完毕释放锁
(例子5)
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com import random from threading import Thread from threading import Lock # 库存数量,这个就属于临界资源 STOCK = 100 # 锁 LOCK = Lock() def buy(username, amount): """ 购买商品方法,从 LOCK.acquire() 到 LOCK.release() 之间属于临界区,因为这中间的代码就开始对STOCK进行操作了 :param username: 用户名称 :param amount: 购买数量 :return: """ LOCK.acquire() global STOCK print("用户 %s 下单购买 %d 个商品" % (username, amount)) if STOCK >= amount: STOCK = STOCK - amount print("%s 成功的购买了 %d 个商品。" % (username, amount)) print("当前库存数量:%d" % STOCK) else: print("用户 %s 您好,当前库存不足,您最多可以购买 %d 个商品, 请重新下单" % (username, STOCK)) LOCK.release() def main(): print("库存数量:%d" % STOCK) userlist = ['User1', 'User2', 'User3', 'User4', 'User5', 'User6', 'User7', 'User8', 'User9'] userthreadlist = [] for user in userlist: userT = Thread(target=buy, args=(user, random.randint(10, 100))) userT.start() userthreadlist.append(userT) for userT in userthreadlist: userT.join() print("抢购后当前库存数量:%d" % STOCK) if __name__ == '__main__': main()
执行效果

这个程序只是为了展示锁如何使用以及效果,所以程序还有很多不完整的地方,比如不能重新下单直到库存为0,有兴趣可以自己去完善。更加简洁的使用锁的方式
# -*- coding: utf-8 -*-
# @Time : 2020/2/13 14:48
# @Author : rex.chen
# @Email : rex.cheny@outlook.com
# @File : lockTest.py
# @Software: PyCharm
import threading
import time
locker = threading.Lock()
cups = []
def produce_cups(count=100):
while True:
"""
这里等同于那种 with open() as 语句,通过上下文的方式使用锁,进入with语法块说明获取所成功,代码执行完毕自动释放。
它的原理就是调用__enter__语句获取锁,最后调用__exit__语句释放锁。 RLock里面也是这么实现的。
"""
with locker:
if len(cups) < count:
time.sleep(0.001)
cups.append(1)
"""
这里跳出循环为什么不写在 with 语句块里呢?因为在with 语句里面直接break后就跳出去了,它不会执行__exit__
所以也就不会释放锁。
"""
if len(cups) == count:
break
def main():
t_list = []
for i in range(20):
t = threading.Thread(target=produce_cups, args=(1000,))
t_list.append(t)
t.start()
for t in t_list:
t.join()
print(len(cups))
if __name__ == '__main__':
main()
信号量
下面我演示的是和上面一样的功能只是使用了信号量,我这里用的是二进制信号量。信号量解释网上很多,我这里摘抄一个。
信号量是线程的同步机制,它其实就是一个计数器,当资源消耗时递减,当资源释放是递增。
进程或者线程可以共享信号量,如果一个线程或者进程执行获取信号量操作时,它将得到信号量,然后就可以执行,而后一个进程获取信号量时如果是0就会
被阻塞,那么它必须等待前一个进程释放。所以如果信号量不是0那么该进程就可以执行。这里说的是二进制信号量,也就是0或者1.
(例子6)
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com import random from threading import Thread, BoundedSemaphore # 库存数量,这个就属于临界资源 STOCK = 100 # 实例化一个信号量对象,BoundedSemaphore 的一个功能就是计数器永不会超过初始值,为了防止释放次数多余获得次数 candytray = BoundedSemaphore(2) def buy(username, amount): """ 购买商品方法,从 candytray.acquire() 到 candytray.release() 之间属于临界区,因为这中间的代码就开始对STOCK进行操作了 :param username: 用户名称 :param amount: 购买数量 :return: """ # 下面的语句是信号量递减,如果某个线程执行到这里发现信号量是0,则会被阻塞并等待其他线程执行release()操作 candytray.acquire() global STOCK print("用户 %s 下单购买 %d 个商品" % (username, amount)) if STOCK >= amount: STOCK = STOCK - amount print("%s 成功的购买了 %d 个商品。" % (username, amount)) print("当前库存数量:%d" % STOCK) else: print("用户 %s 您好,当前库存不足,您最多可以购买 %d 个商品, 请重新下单" % (username, STOCK)) # 下面的语句是信号量递增 candytray.release() def main(): print("库存数量:%d" % STOCK) userlist = ['User1', 'User2', 'User3', 'User4', 'User5', 'User6', 'User7', 'User8', 'User9'] userthreadlist = [] for user in userlist: userT = Thread(target=buy, args=(user, random.randint(1, 100))) # userT.start() userthreadlist.append(userT) for userT in userthreadlist: userT.start() for userT in userthreadlist: userT.join() print("抢购后当前库存数量:%d" % STOCK) if __name__ == '__main__': main()
执行效果

对于非二进制信号量来说就是一个更大的整数。
所以如果为了控制对共享资源的访问那么通常会把信号量设置为1.如果你设置大于1,则表示针对该资源将有可能出现同一时刻被多于1个线程或进程访问。
那么有没有需要让信号量大于1的时候呢?当然有,比如购买火车票,售票大厅容纳500人,售票窗口肯定比500少,这时候就需要两种信号量,一种代表
售票大厅的容纳人数其信号量就为500、另一种代表售票窗口,如果售票窗口就1个,那么此时代表售票窗口的信号量就为1.
其实很多时候我们并不需要用信号量来控制线程或者进程的多少,这个可以用池来解决。通常使用信号量是为了避免多个线程或者进程对同一资源访问从而
造成数据不一致。当然解决这种问题除了使用信号量之外最常规的就是使用锁来实现。
线程通信
在本节(例子2)其实就演示主线程和线程通信的效果,就是传递一个列表到所有线程,每个子线程在列表中添加自己的名字,然后在主线程中显示。当然这个并不算是严谨的线程间通信虽然它也通信了,虽然使用列表或者字典等传递给线程也可以共享数据但是这不是线程安全的。其实线程通信比较容易,因为每个线程共享进程的内存空间,所以这也就为什么会有线程安全的问题。因为毕竟每个进程都是独立的内存空间是隔离的。为了让线程安全通信我们之前说了锁和信号量,不过在python标准库中还有一个叫做Queue的对象。这个模块可以提供线程共享数据而且是线程安全的。
(例子7)
#!/usr/bin/env python # -*- coding: utf-8 -*- # Author: rex.cheny # E-mail: rex.cheny@outlook.com import random from threading import Thread from queue import Queue, LifoQueue, PriorityQueue from time import sleep """ Queue本身就包含了锁,所以线程可以安全的传递数据。 q = Queue(10) 创建一个先进先出的队列,如果设置了最大队列长度,那么在队列满的时候将被阻塞,否则队列长度则没有限制 LifoQueue(MAX_SIZE) 后入先出队列 PriorityQueue(MAX_SIZE) 优先级队列 put((优先级,数据)), 优先级可以是字母也可以是数字,数字越小优先级越高 常用方法: qsize() 获取队列当前长度 empty() 判断当前队列是否为空,如果队列为空则返回True full() 判断队列是否已经满了,如果满了则返回 True put(DATA) 将数据放入队列 get(DATA) 从队列中取出一个数据 """ def productmessage(queue): count = 1 while True: if count >= 10: print("写入消息退出命令 EXIT。") queue.put("EXIT") break msg = random.randint(50, 100) print("写入消息 %d" % msg) queue.put(msg) print("当前队列长度:%d" % queue.qsize()) count += 1 sleep(random.randint(1, 3)) def consumemessage(queue): while True: msg = queue.get(1) if msg == "EXIT": print("收到退出命令 EXIT。") break print("线程读取了一条数据:%s 当前队列长度:%d" % (msg, queue.qsize())) sleep(random.randint(1, 3)) def main(): # 创建队列并设置队列长度 q = Queue(10) wT = Thread(target=productmessage, args=(q, )) rT = Thread(target=consumemessage, args=(q, )) wT.start() rT.start() if __name__ == '__main__': main()

在使用put和get的时候它有一个非同步方式。因为如果使用同步方式,那么当队列空了你还继续get将会阻塞,默认是这种方式,同理put也是,如果队列没有空余位置,那么就会等待这个等待时间由timeout设置。put方法默认是阻塞的。这里我们使用了Queue,它其实本身使用的是dqueue,而这个东西在字节码的层面上就已经实现了线程安全。
事件通知
Event也是线程通信的一种,它使用起来比较简单它不能传递具体数据只能用于发送通知。这种在某些场景下需要。
(例子7)
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys from threading import Event from threading import Thread import time """ 线程的事件驱动 服务器和客户端同时会监听一个标志,默认是Fasle,如果有事件触发,则触发的一方会把标志设置为True,这时候需要处理的一方 就知道有事件,那么它将处理这个事情。 """ def Server(event): print("Server: 等活儿中。。。。。") # 这个是事件驱动的等待,属于阻塞的等待,这就是服务器去等待这个标志,如果不要阻塞的就用 event.isSet() 判断是否为True,不是True就干其他的事情 event.wait() print("Server: 客户端触发了一个事件。") print("Server: 服务器开始处理。。。。。。") # 这个是把标准位恢复为False,因为客户端一点调用event.set(),那么标志就是True,如果这里不清空,那么就一直是True, # 那么下面Client里面 event.wait()就会立刻获取True,而不会等待服务器下面的处理。 event.clear() # time.sleep(3) print("Server: 服务器处理完毕。") # 服务器也要去更新这个标志,表示已经处理完了,用于通知客户端,因为客户端此时在关注这个事件 event.set() def Client(event): print("Client: 我去派个活儿。。。。。") # 这个是事件驱动的通知,就是服务器在等待的时候,客户端调用这个方法表示去更新那个标志 event.set() print("Client: 活儿已派等待服务器处理事件:") # time.sleep(1) # 客户端等待服务器更新标志位 event.wait() # 这里要想执行就必须等待上面 Server 里面的 event.set()执行完了才可以 print("Client: 谢谢服务器。") def main(): # 创建一个事件对象 event = Event() srvT = Thread(target=Server, args=(event,)) srvT.start() cliT = Thread(target=Client, args=(event,)) cliT.start() if __name__ == "__main__": try: main() finally: sys.exit()

通过派生子类的方式创建线程
通过派生子类创建线程比较简单,子类的使用方式和直接使用Thread是一样的,不过至少要重写run方法,这里就是具体运行你自己的逻辑,构造方法可以省略。
(例子8)
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys from threading import Thread """ 这里演示通过集成Thread类来运行线程 之前是通过 t = Thread(target=FUN, args(X,)) 这种方式把需要让线程执行的方法或者说是FUN传递进去,然后通过t.start()来运行线程 实际上 Thread类里的 start()方法 调用的是 Thread中的run()方法,这个方法里面非常简单就是单纯的执行我们传递进去的方法和参数,那么 如果我们自己来写一个类,这个类从Thread继承,然后通过重写run()也是可以的,看下面实例。 """ class MyThread(Thread): # 如果你自己重写了构造方法,那么你就必须在这个方法里调用父类的构造方法,否则初始化会失败 def __init__(self, name): # 调用父类的构造方法,至于是否传递参数根据需要,我这里只是传递一个名字,其实也可以省略。 super(MyThread, self).__init__(name=name) def run(self): print("我的线程运行了。") def main(): mt = MyThread("AAA") mt.start() print(mt.getName()) if __name__ == "__main__": try: main() finally: sys.exit()

为什么main函数的代码是主线程呢?
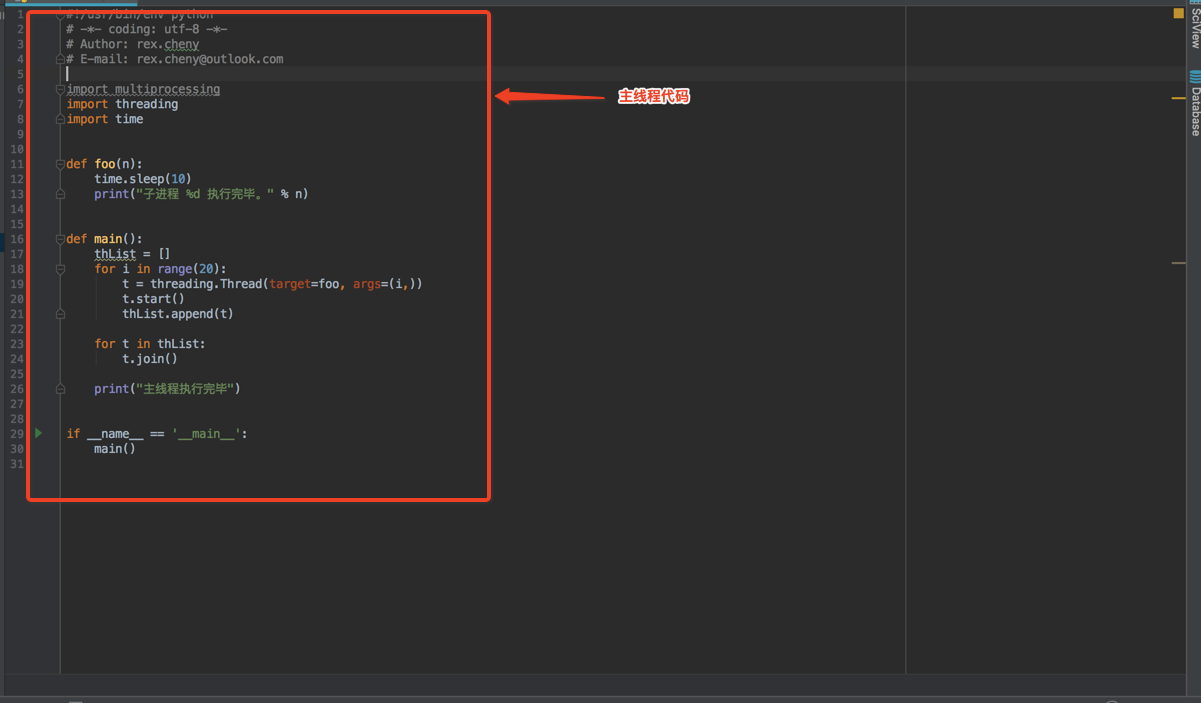
加入该py文件名称为a.py。你通过python ./a.py运行,这里的进程是python解释器或者是虚拟机,a.py里面的代码就是该进程主要执行的代码段,这就是一项任务,也就是主线程。
如果我运行20个线程你看看效果,在休眠20秒内,你查看系统只有一个进程存在,也就是Python解释器。
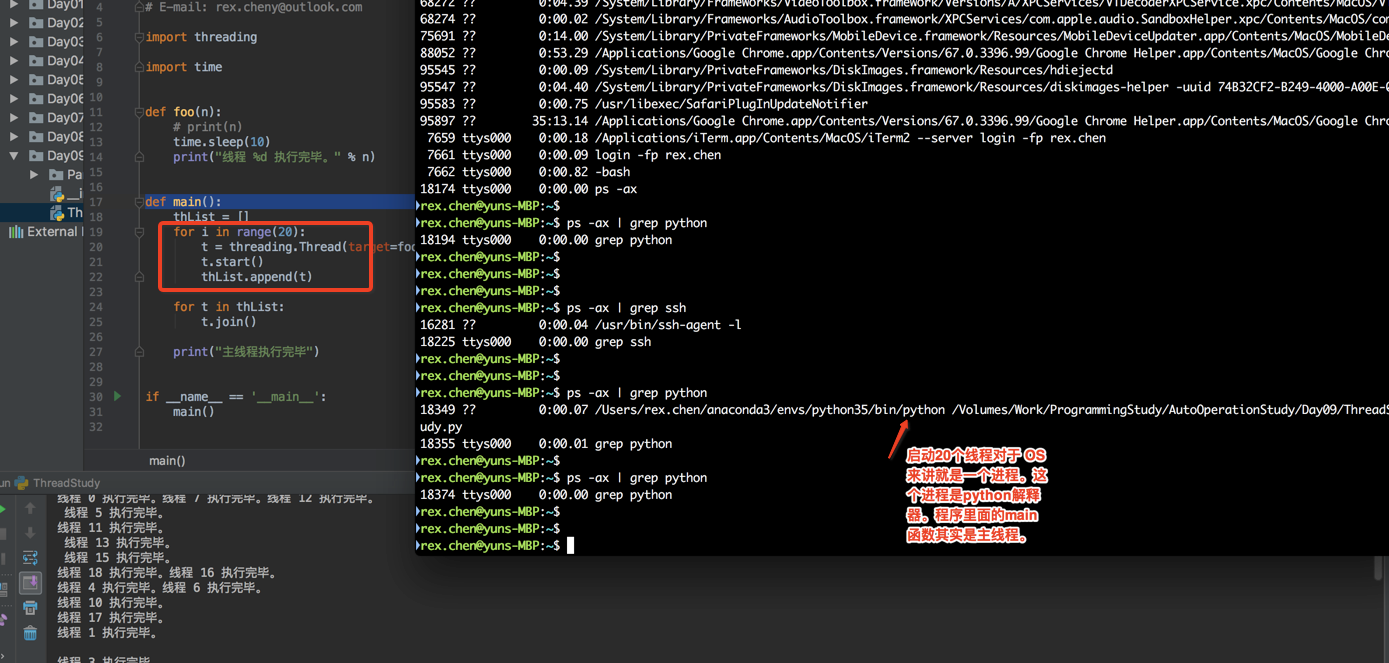
如果改为20个进程呢?

再次运行,这次我们把进程号打印出来,你主程序是19311,其他20个的父进程都是19311,这20个都是fork出来的子进程。在类Unix操作系统有fork,在Windows上没有,它应该是通过其他方式产生的子进程。

真的有20个,其实是21个,为什么?还是一样的道理,20个是你生成的,那这20个是由谁生成的呢?当然是你上面这段代码,这段代码由谁执行呢,当然是Python解释器啊,所以先由解释器运行起来执行这段代码(一个进程),然后产生的20个进程。所以是21个。

这里是为什么是22个,哈哈,本条命令本身就包含关键词python,所以也算一个统计值但是它并不算是进程就是一个关键字而已。