上一篇笔记讲到globals总是固定指向模块名字空间,而locals则指向当前作用域环境
在初步了解后,我们甚至可以直接修改名字空间来建立关联引用,这与传统变量定义方式有所不同
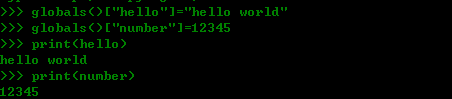
并非所有时候都能直接操作名字空间,函数执行使用缓存机制,直接修改本地名字控件未必有效,在正常编码时,应尽可能的避免直接修改名字空间
在名字空间里,名字只是简单字符串主键,其自身数据结构里没有任何目标对象信息,通过名字访问目标对象的本质就是以名字作为主键去字典里读取目标对象指针引用。也正因为如此,名字可以重新关联另一个对象,完全不在乎其类型是否与前任相同
赋值操作仅是让名字在名字空间里重新关联,而非修改原对象
和一个名字只能引用一个对象不同,单个对象可以同时有多个名字,无论是在相同或不同的名字空间里

必须使用is判断两个名字是否引用同一对象,相等操作符并不能确定两个名字指向同一个对象,这涉及操作符重载,或仅用来比较值是否相等

理解方式:python中一次声明创建一个对象,1234被声明了两次,所以是不同的对象,拥有不同的id值,is是判断id值是否相同的,所以返回false,==是判断值是否相同,所以返回的是true
补充:
如下图所示,x和y值相同,且值为一个较小的值时,x is y被判断为true

引用
https://blog.csdn.net/xiongchengluo1129/article/details/78770177?utm_source=blogxgwz2
int清楚写了[-5, 256] 这些小整数被定义在了这个对象池里.所以当引用小整数时会自动引用整数对象池里的对象的. string对象也是不可变对象,python有个intern机制,简单说就是维护一个字典,这个字典维护已经创建字符串(key)和它的字符串对象的地址(value),每次创建字符串对象都会和这个字典比较,没有就创建,重复了就用指针进行引用就可以了. string实现了intern共享?我觉得是一种空间效率和时间效率的妥协。相比于数字,string本身参与的运算要少很多,而且string本身占据的空间也大许多,因此string的主要问题在于不共享带来的空间浪费,所以string实现了很费时间的intern操作。对于数字情况正好相反。作为一个数字,需要做的运算要比string多太多了,而且大小比string也小很多。如果在计算10000+20000之前先花好久查找重复对象,导致一个1ms完成的加法花了100ms,我肯定想砸电脑的。 float类型可以认为每个赋值都是创建一个对象,因为float有点多,所以没必要和int一样了. tuple它是不可变对象,理应和int和string一样会做一个缓存,但是书上没有说明,于是看了看源码,发现tuple的数据结构很简单,简单到不能再简单,就是一个数组,里面是元组的迭代对象,这个对象指向的是各个元素.最关键的是元组没有实现intern机制!所以元组虽然是不可变对象,但它同时也是一个数组,这个数组和c里的数组一样,每次创建都会分配内存空间。
所以上述代码中,因为123在这个小整数对象池里,所以两次申明其实指向了同一个对象,此时x和y拥有了同一个id值,所以此时 x is y被判定为true
总结:
Python中的对象包含三要素:id、type、value
其中id用来唯一标识一个对象
type标识对象的类型
value是对象的值
is判断的是a对象是否就是b对象,是通过id来判断的
==判断的是a对象的值是否和b对象的值相等,是通过value来判断的