Redis 主从复制
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
Redis集群主从复制(一主两从)搭建配置教程【Windows环境】
主从复制核心原理
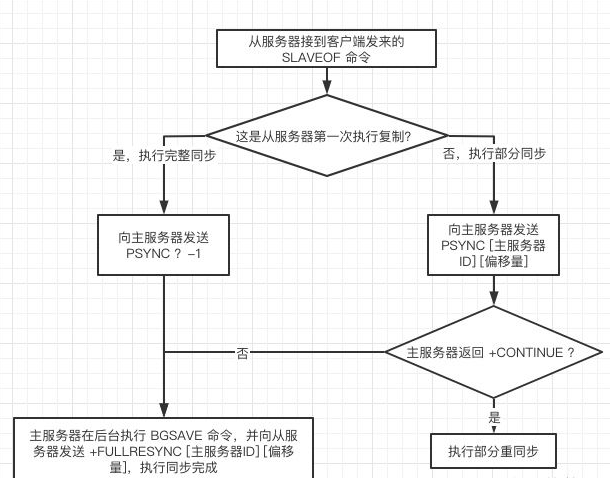
当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,
同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,
接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。
slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
面试问答
生产环境Redis的部署
Redis cluster,10 台机器,5 台机器部署了 redis 主实例,另外 5 台机器部署了 redis 的从实例,每个主实例挂了一个从实例,5 个节点对外提供读写服务,每个节点的读写高峰qps可能可以达到每秒 5 万,5 台机器最多是 25 万读写请求/s。
机器是什么配置?
32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 redis 进程的是10g内存,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。
5 台机器对外提供读写,一共有 50g 内存。因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
你往内存里写的是什么数据?每条数据的大小是多少?
人员数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 300 万条人员数据,占用内存是 30g,仅仅不到总内存的 60%。目前高峰期每秒就是 3500 左右的请求量。
其实大型的公司,会有基础架构的 team 负责缓存集群的运维。
Redis Cluster

Redis 集群模式的工作原理能说一下么?在集群模式下,redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?
简介
Redis Cluster是一种服务端Sharding技术,3.0版本开始正式提供。Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行
方案说明
- 通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384 个槽位
- 每份数据分片会存储在多个互为主从的多节点上
- 数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
- 同一分片多个节点间的数据不保持一致性
- 读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
- 扩容时时需要需要把旧节点的数据迁移一部分到新节点
在 Redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。
16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。
节点间的内部通信机制
基本通信原理
集群元数据的维护有两种方式:集中式、Gossip 协议。redis cluster 节点间采用 gossip 协议进行通信。
分布式寻址算法
- hash 算法(大量缓存重建)
- 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- redis cluster 的 hash slot 算法
优点
- 无中心架构,支持动态扩容,对业务透明
- 具备Sentinel的监控和自动Failover(故障转移)能力
- 客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- 高性能,客户端直连redis服务,免去了proxy代理的损耗
缺点
- 运维也很复杂,数据迁移需要人工干预
- 只能使用0号数据库
- 不支持批量操作(pipeline管道操作)
- 分布式逻辑和存储模块耦合等