一. uptime
root@calm:~# uptime 21:35:44 up 54 days, 11:50, 1 user, load average: 0.04, 0.09, 0.04
这里主要关注load average参数,3个值分别表示最近1分钟,5分钟,15分钟的系统负载值。此部分值可参考CPU的个数或者核数,CPU的信息可用lscpu或者cat /proc/cpuinfo查看
如果5分钟的负载值或15分钟的负载值长期超过CPU个数的2倍,说明系统当前处于高负载,需要优化
如果数值长期低于CPU个数或核数,说明系统运行正常
如果长期处于1以下,说明CPU资源没得到有效利用
二. vmstat
这是个较全面的性能分析工具,可观察进程状态,内存使用情况,swap使用情况,磁盘的IO, CPU的使用等信息
1. 基本用法
root@calm:~# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 106932 177760 447260 0 0 7 13 1 3 1 0 98 0 0
不加任何参数,vmstat命令只输出一条记录,这个数据是自系统上次重启之后到现在的平均数值
root@calm:~# vmstat 1 3 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 106044 178532 447636 0 0 7 13 1 3 1 0 98 0 0 0 0 0 105896 178532 447644 0 0 0 0 174 417 1 1 98 0 0 0 0 0 105896 178532 447644 0 0 0 0 177 445 2 0 98 0 0
其中1表示刷新时间间隔。如果不指定,只显示一条结果。3表示刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
2. vmstat输出结果参数说明
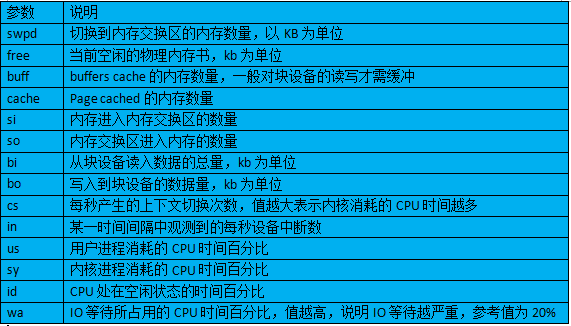
3. 各自值性能分析
1)process第一列r表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数,说明CPU不足;第二列b表示在等待资源的进程数,等待的资源有I/O或内存交换等
2)CPU列显示了用户进程和内核所消耗的CPU的时间百分比。us的值较高时,说明用户消耗的CPU时间多,us+sy的参考值为80%,如果长期大于80%说明可能存在CPU不足
3)swap列表示系统交换分区使用情况,一般si,so的值都为0,如果他们长期不为0,则表示系统内存不足
4)io列显示磁盘读写状况,这里设置的bi+bo参考值为1000,如果大于1000,切wa的值较大,这表示系统磁盘IO有问题
5)system项显示采集间隔内发生的中断数,in和cs的值越大,就会看到由内核消耗的CPU时间越多。