| 这个作业属于哪个课程 | 课程 |
|---|---|
| 这个作业要求在哪里 | |
| 这个作业的目标 | 疫情统计 |
| 作业正文 | .... |
| 其他参考文献 | ... |
一.我的Github仓库
https://github.com/Seway/InfectStatistic-main
二.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 750 | 800 |
| Analysis | 需求分析 (包括学习新技术) | 80 | 80 |
| Design Spec | 生成设计文档 | 30 | 40 |
| Design Review | 设计复审 | 30 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 100 | 90 |
| Coding | 具体编码 | 300 | 520 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 80 | 70 |
| Reporting | 报告 | 120 | 110 |
| Test Report | 测试报告 | 50 | 60 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 1820 | 2040 |
三.解题思路
1.输入
- 题目要求使用cmd来进行操作,根据输入的指令来执行程序,所以首先的分析输入的指令,得出要读取的日志目录,和输出文件的地址和文件名。
- 当输入输出设置好了,接下来就该对文件的内容进行处理,对日志中有可能出现的以下几种情况进行分析:
<省> 新增 感染患者 n人
<省> 新增 疑似患者 n人
<省1> 感染患者 流入 <省2> n人
<省1> 疑似患者 流入 <省2> n人
<省> 死亡 n人
<省> 治愈 n人
<省> 疑似患者 确诊感染 n人
<省> 排除 疑似患者 n人
- 可以得到输出日志需要的计算过程
a) 感染患者:新增感染患者+流入的感染患者+确认感染的疑似患者-死亡-治愈人数-流出的感染患者
b) 疑似患者:新增疑似患者+流入的疑似患者-确认感染的疑似患者人数-流出的疑似患者-排除疑似患者
- 输入的命令行分析,以下为命令的要求
-log 指定日志目录的位置,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-out 指定输出文件路径和文件名,该项必会附带,请直接使用传入的路径,而不是自己设置路径
-date 指定日期,不设置则默认为所提供日志最新的一天。你需要确保你处理了指定日期之前的所有log文件
-type 可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如 -type ip 表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。
-province 指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江
-date选项可以在对文件对象排序之后,进行对日期查验以及按序读取,-type和-province 选项可以在已得到的数据中进行根据要求筛选然后输出。
2.输出
- 根据作业的要求,按照一下格式进行输出:
全国 感染患者22人 疑似患者25人 治愈10人 死亡2人
福建 感染患者2人 疑似患者5人 治愈0人 死亡0人
浙江 感染患者3人 疑似患者5人 治愈2人 死亡1人
// 该文档并非真实数据,仅供测试使用
根据作业的要求,在输出前对已得到的数据项先对type和province的要求进行处理,选择要输出的数据项,然后要按照作业要求中的省份排序进行,排序好后进行排序。
四.设计实现过程
1.province_info类
- 用来储存单个省份的情况,用来组成数组集中管理,在之后的排序,筛选以及输出中使用
2.read_file函数
- 读取指定的日志文件,使用adjust_arry函数对文件中的内容进行分析,将得出的结果实时更新到数组中对应的项目
3.adjust_arry函数
- 根据文件的内容,对每一条数据进行分析,得出语句的内容,将得到的信息更新到province_info数组中
4.sort_file函数
- 对log目录下的文件进行排序,方便-date日期的查验以及按照日期进行信息整理
5.summary函数
- 对已得到的信息进行统计得到全国的情况
6.output函数
- 根据主函数中获取的命令,针对type,province,date项进行函数的筛选,在根据省份排序输出
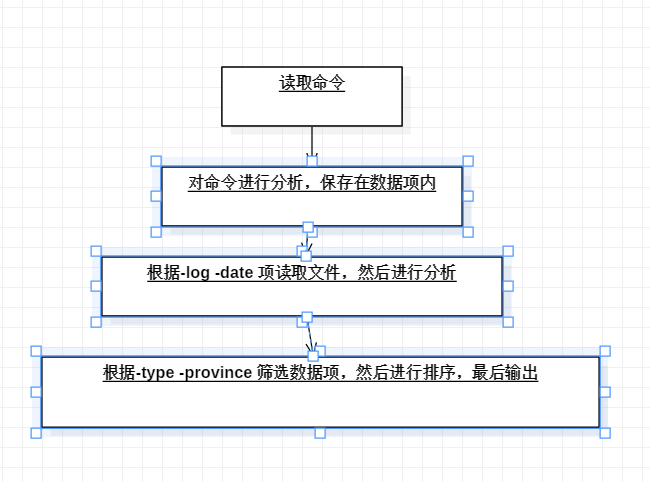
五.代码说明。展示出项目关键代码,并解释思路。
1.在读入文件对象后,对文件对象进行按日期排序,返回一个文件对象数组,方便之后的排序,验证日期以及按照顺序处理指定日期之前的文件
//对指定目录下的文件按照日期进行排序
private File[] sort_file(String log) throws IOException {
File file=new File(log);//创建指定目录的File对象
File[] files = file.listFiles();
List fileList = Arrays.asList(files);
//按照日期升序对file对象进行排序
Collections.sort(fileList, new Comparator<File>() {
@Override
public int compare(File o1, File o2) {
if (o1.isDirectory() && o2.isFile())
return -1;
if (o1.isFile() && o2.isDirectory())
return 1;
return o1.getName().compareTo(o2.getName());
}
});
return files;
}
2.读取文件中的某一行文字,对其进行单独的处理,根据文字的内容判断它会对那个省份的情况产生影响,产生什么样的影响,然后对保存省份情况的数组做出项对应的更新.
//对某行文字进行判断并对数据队列进行调整
private void adjust_arry(String line){
String[] lines=line.split(" ");
if(lines[0].equals("//")) return;//省略注释部分
//判断该条信息所对应的省份是否被创建
boolean success=false;
int where=0;
for( int i=0;i<infos.size();i++){
if(infos.get(i).name.equals(lines[0])){
success=true;
where=i;
}
}
if(success==false){
where=infos.size();
province_info e=new province_info(lines[0]);
infos.add(e);
}
//死亡或者治愈
if (lines.length==3){
if (lines[1].equals("死亡")){
int temp=trans_num(lines[2]);
infos.get(where).dead+=temp;
infos.get(where).infected-=temp;
}
else if (lines[1].equals("治愈")){
int temp=trans_num(lines[2]);
infos.get(where).cure+=temp;
infos.get(where).infected-=temp;
}
}
//其他情况
else if(lines.length==4){
if (lines[1].equals("新增")){
int temp=trans_num(lines[3]);
if (lines[2].equals("感染患者")){//新增感染患者
infos.get(where).infected+=temp;
}
else {//新增疑似患者
infos.get(where).suspected+=temp;
}
}
else if(lines[1].equals("疑似患者")){//确认感染
int temp=trans_num(lines[3]);
infos.get(where).suspected-=temp;
infos.get(where).infected+=temp;
}
else if(lines[1].equals("排除")){
int temp=trans_num(lines[3]);
infos.get(where).suspected-=temp;
}
}
//人口流动情况
else if(lines.length==5){
int temp=trans_num(lines[4]);//流动人数
int to=search_province(lines[3]);//患者流向的省份
if (lines[1].equals("感染患者")){//感染患者流动
infos.get(where).infected-=temp;
infos.get(to).infected+=temp;
}
else {//疑似患者流动
infos.get(where).suspected-=temp;
infos.get(to).suspected+=temp;
}
}
}
3.在输出最终的结果前,对数组按照顺序排序,符合作业的要求
//对现有的对象数组进行整理
private void Arrangement(){
set_heavy();
Comparator<province_info> comparator = new Comparator<province_info>(){
public int compare(province_info s1, province_info s2) {
return s1.heavy-s2.heavy;
};
};
//对输出队列排序
Collections.sort(infos,comparator);
}
4.输出文件时,按照命令的要求,对现有的数组进行筛选,选择输出的省份,信息项进行输出,以及对信息项的出现顺序进行调整。
//写入文件
private void output(String out) throws IOException {
String[] temp=out.split("\\");
String filename=temp[temp.length-1];//获取地址中的文件名
//System.out.println(filename);
String path=out.split(filename)[0];//将地址中的文件名剔除
File f1=new File(path);//传入文件/目录的路径
File f2=new File(f1,filename);//第一个参数为一个目录文件,第二个参数为要在当前f1目录下要创建的文件
PrintWriter printWriter =new PrintWriter(new FileWriter(f2,true),true);//第二个参数为true,从文件末尾写入 为false则从开头写入
if(province.size()==0){//不指定显示地区
if(type.size()==0){//不指定显示类别
for (int i=0;i<infos.size();i++){
printWriter.print(infos.get(i).name+" ");
printWriter.print("感染患者"+infos.get(i).infected+"人 ");
printWriter.print("疑似患者"+infos.get(i).suspected+"人 ");
printWriter.print("治愈"+infos.get(i).cure+"人 ");
printWriter.print("死亡"+infos.get(i).dead+"人
");
}
}
else{//指定显示类别
for(int i=0;i<infos.size();i++){
printWriter.print(infos.get(i).name+" ");
for (int j=0;j<type.size();j++){
char od=type.get(j).charAt(0);
switch (od){
case 'i':{
printWriter.print("感染患者"+infos.get(i).infected+"人 ");
break;
}
case 's':{
printWriter.print("疑似患者"+infos.get(i).suspected+"人 ");
break;
}
case 'c':{
printWriter.print("治愈"+infos.get(i).cure+"人 ");
break;
}
case 'd':{
printWriter.print("死亡"+infos.get(i).dead+"人 ");
break;
}
}
}
printWriter.println();//行末换号
}
}
}
else {//指定显示地区
for(int i=0;i<province.size();i++){
boolean get=false;
for (int j = 0; j < infos.size(); j++) {
if (province.get(i).equals(infos.get(j).name)) {
get=true;//该省份的信息存在
break;
}
}
if(get==false){//该省份的信息不存在
province_info tenp = new province_info(province.get(i));
infos.add(tenp);
}
}
Arrangement();//增加新的项目后重新排序
//记录需要输出的地区的数据项
for (int i = 0; i < province.size(); i++) {
for (int j = 0; j < infos.size(); j++) {
if (province.get(i).equals(infos.get(j).name)) {
infos.get(j).out=true;
break;
}
}
}
/* //如果想要显示的地区信息不存在 创建一个空数据项
if (t.size() < province.size()) {
for (int i = 0; i < province.size(); i++) {
if (!province.get(i).equals("none")) {
province_info tenp = new province_info(province.get(i));
infos.add(tenp);
t.add(infos.size() - 1);
}
}
}*/
if(type.size()==0) {//不指定显示类别
//输出需要输出的地区情况
for (int i = 0; i < infos.size(); i++) {
if(infos.get(i).out==true){
printWriter.print(infos.get(i).name + " ");
printWriter.print("感染患者" + infos.get(i).infected + "人 ");
printWriter.print("疑似患者" + infos.get(i).suspected + "人 ");
printWriter.print("治愈" + infos.get(i).cure + "人 ");
printWriter.print("死亡" + infos.get(i).dead + "人
");
}
}
}
else{//指定显示类别
for(int i=0;i<infos.size();i++){
if(infos.get(i).out==true){
printWriter.print(infos.get(i).name + " ");
for (int j=0;j<type.size();j++){
char od=type.get(j).charAt(0);
switch (od){
case 'i':{
printWriter.print("感染患者" + infos.get(i).infected + "人 ");
break;
}
case 's':{
printWriter.print("疑似患者" + infos.get(i).suspected + "人 ");
break;
}
case 'c':{
printWriter.print("治愈" + infos.get(i).cure + "人 ");
break;
}
case 'd':{
printWriter.print("死亡" + infos.get(i).dead + "人 ");
break;
}
}
}
printWriter.println();//行末换号
}
}
}
}
printWriter.print(" // 该文档并非真实数据,仅供测试使用
");
printWriter.close();//记得关闭输入流
}
六.单元测试截图和描述。
1.主函数的构建

2.文件读取函数

3.文件排序函数


4.对文件中的语句进行处理的函数


5.Arrangement函数对现有的数组按照省份排序

6.set_heavy 为数组中的某一项按照省份顺序设置权重的函数

7.summary 在完成对所有指定文件处理后得出全国的数据


8.ouput 在完成所有的统计后按照要求输出文件

9.trans_num 对语句中的数字使用正则进行处理
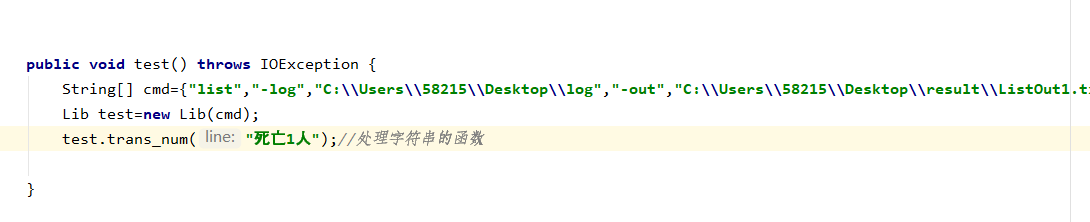
10.search_province 当处理文件中的语句时要对相应的数组中的数据项进行处理,该函数按照名字查找名字对应在数组中的位置

七.单元测试覆盖率优化和性能测试,性能优化截图和描述。
1.代码覆盖率


2.性能测试
八.给出你的代码规范的链接,即你的仓库中的codestyle.md
九.结合在构建之法中学习到的相关内容,撰写解决项目的心路历程与收获。
在开始项目之前,没有详细的设计,然后感觉写出来项目没有达到预期的结果,在实际撰写项目的过程中,对于很多之前不了解的地方有了新的理解,借这个机会有重新复习了一遍Java。虽然说设计没有很好,但是好在在开始项目前,我就决定要坚持把能供从主函数中分离的功能都做成函数,这样方便了之后的修改和查错,这样无疑提高了编程的效率。虽然,这一次的项目没有做的很好,但是让我明白了,在开始项目之前一定要尽可能的设计好项目,这样在实际编程的时候可以省去很多不必要的麻烦。
十.在github上寻找你在第一次作业中技术路线图相关的5个仓库,star并fork,在博客中提供名称、链接、简介(简介30字左右)
1.Vue-argon-design-system
Vue-argon-design-system是基于Design System for Bootstrap 4开发,它由100多个独立的组件构成,用户可以自由选择和组合,所有组件都可以采用颜色变化,你可以使用SASS文件轻松修改。
2.Vue-ydui
-
https://github.com/ydcss/vue-ydui
Vue-ydui 是 YDUI Touch 的一个Vue2.x实现版本,专为移动端打造,在追求完美视觉体验的同时也保证了其性能高效。在开始使用 vue-ydui 之前,有必要先了解 Vue 的相关基础知识以及Vue 组件,并了解移动端相关特性。
3.ElemeFE/element
-
https://github.com/ElemeFE/element
Element,一套为开发者、设计师和产品经理准备的基于 Vue 2.0 的组件库,提供了配套设计资源,帮助你的网站快速成型。通过基础的 24 分栏,迅速简便地创建布局。
4.airyland/vux
-
https://github.com/airyland/vux
基于 webpack+vue-loader+vux 可以快速开发移动端页面,配合 vux-loader 方便你在 WeUI 的基础上定制需要的样式。vux-loader 保证了组件按需使用,因此不用担心最终打包了整个 vux 的组件库代码。
5.ElemeFE/mint-ui
- https://github.com/ElemeFE/mint-ui
Mint UI 包含丰富的 CSS 和 JS 组件,能够满足日常的移动端开发需要。通过它,可以快速构建出风格统一的页面,提升开发效率。真正意义上的按需加载组件。可以只加载声明过的组件及其样式文件,无需再纠结文件体积过大。