一、值类型的数据:
var a1 = 0;
var a2 = 'hello str';
var a3 = null;
var a4 = false;
可以看到,这些值都是以键值对的形式存在于内存“栈”中,程序使用的时候,直接从“栈”中获取或修改即可
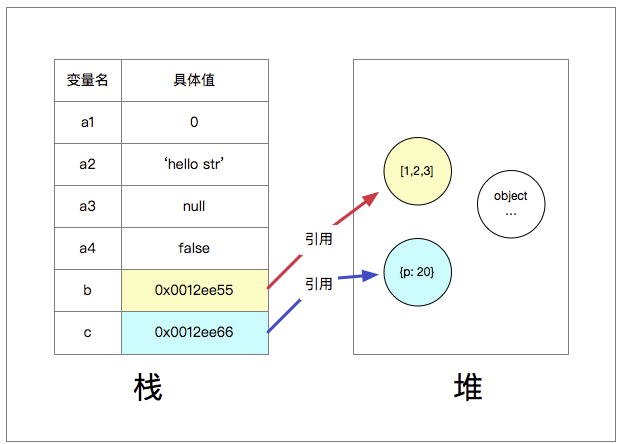
二、引用类型的数据:
var b = [1,2,3];
var c = {p: 20};
可以看到,这些值都是以键值对的形式存在于内存“栈”中,但key名(即变量名)对应的值是“一串计算机内存地址”(URL), 也就是栈中只保存引用类型的URL,URL对应的最终对象在内存的“堆”中
假如我们现在新增一个变量:
var d = b;
var e = c;
d与e是什么?对就是分别是b和c的值, [1,2,3] 和 {p: 20}
即
console.log(d) // [1,2,3]
console.log(e) // {p: 20}
内存中的情况是这样的:
可以看出,
d 中存的是b的指向堆中的地址
e 中存的是c的指向堆中的地址
浅拷贝是什么?
因此,我们修改d的值b的值会跟着同步变,因为改的是堆中同样地点的数据,把这种对引用类型来说,
var d = b;
var e = c;
只拷贝地址的方式的赋值叫浅拷贝

深拷贝是什么?
同样是以上赋值代码 var e = c;
稍作修改:
var f = JSON.parse(JSON.stringify(c));
JSON.stringify(c)是将c对象字符化
JSON.parse是将字符化后的c数据(即{p:20})转换成一个引用对象,新存入堆中,将新的“内存地址”指向f,就是这么个过程,跟浅拷贝区别在于,这里是在堆中新开辟内存存储空间,是一个新对象,跟以前的对象无关,新的对象拥有不同的内存地址
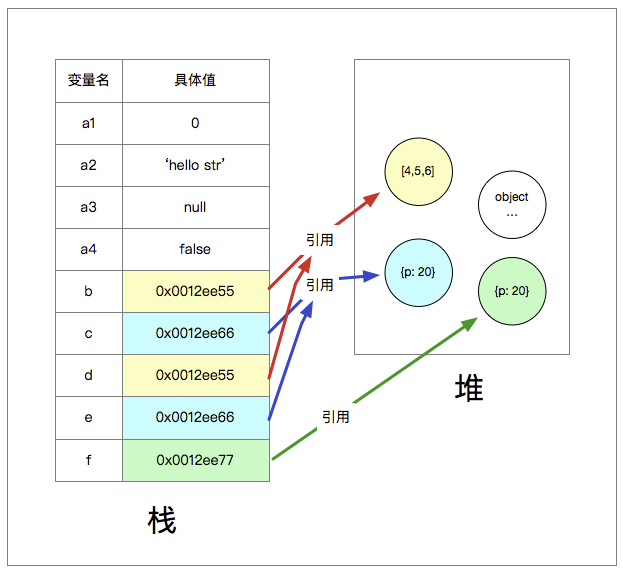
当修改f.p = 30时,这时,c的值仍然是{p:20} 而不是{p: 30},因为f与c已经不是同一个地址了,互不影响
实现深拷贝的方法有很多,比如写一个普通递归函数(遍历就对象的键值,赋值给一个新对象)