作业要求:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/956
git地址:https://git.coding.net/Dawnfox/wf4_2.git
一、第一次分析
测试用例:《战争与和平》,以https://coding.net/u/younggift/p/word_count_demo/git/blob/master/war_and_peace.txt 为输入数据。
分析工具:ptime.exe 下载
CPU参数(Intel(R) Core(TM) i5-6300HQ CPU @ 2.30GHz),题目没有说清楚是什么,此处我理解为是我电脑CPU的配置。
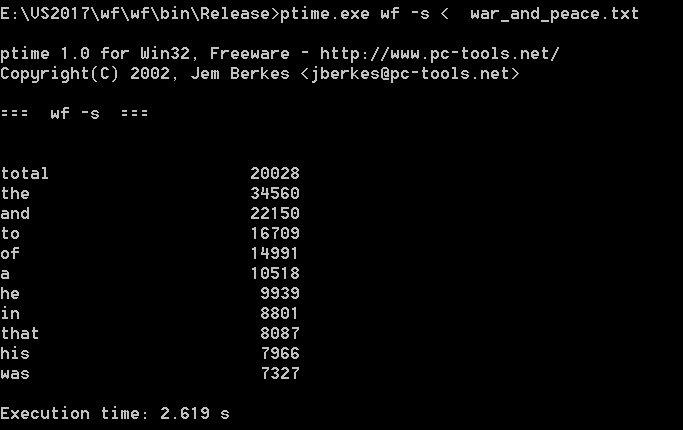
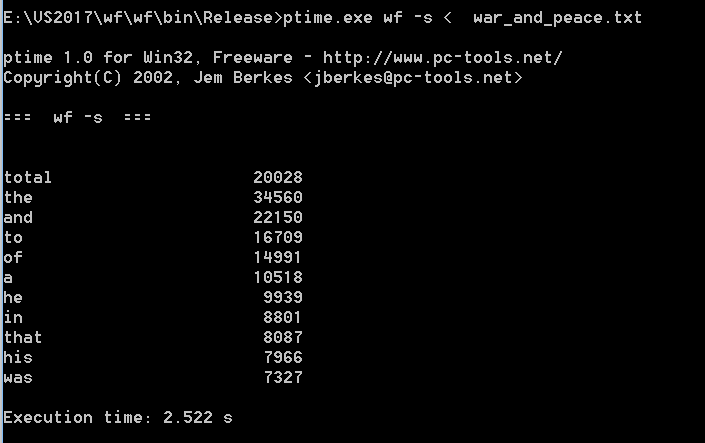
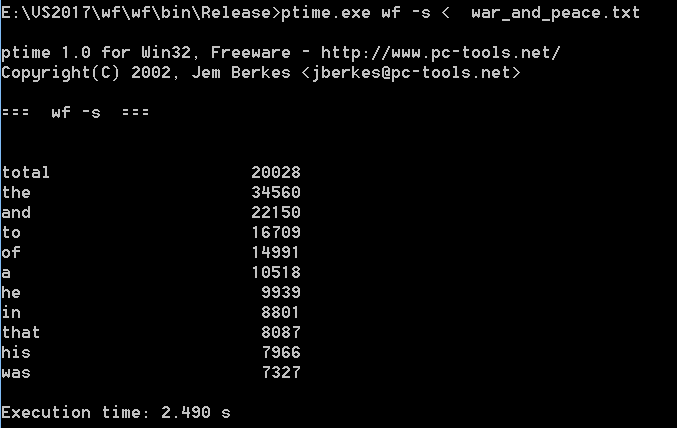
| 次数 | 消耗时间(s) |
|---|---|
| 第一次 | 2.619 |
| 第二次 | 2.522 |
| 第三次 | 2.490 |
| 平均 | 2.544 |
二、猜测存在的瓶颈
猜测一
正则表达式替换或者获取指定字符费时?
static private Regex regex1 = new Regex("(\d|\r|\n)");//空格替换数字和换行
static private Regex regex2 = new Regex(@"p{Pc}|p{Ps}|p{Pe}|p{Pi}|p{Pf}|p{Po}|p{N}|p{C}");//空格替换标点 短横线不替换
static private Regex regex3 = new Regex("(\w+)'\w+");//上撇号后面的内容舍去
s = regex1.Replace(s, " ");
s = regex3.Replace(s, "$1");
s = regex2.Replace(s, " ");
猜测二
字符串分割费时?
sl = s.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
三、profile分析0
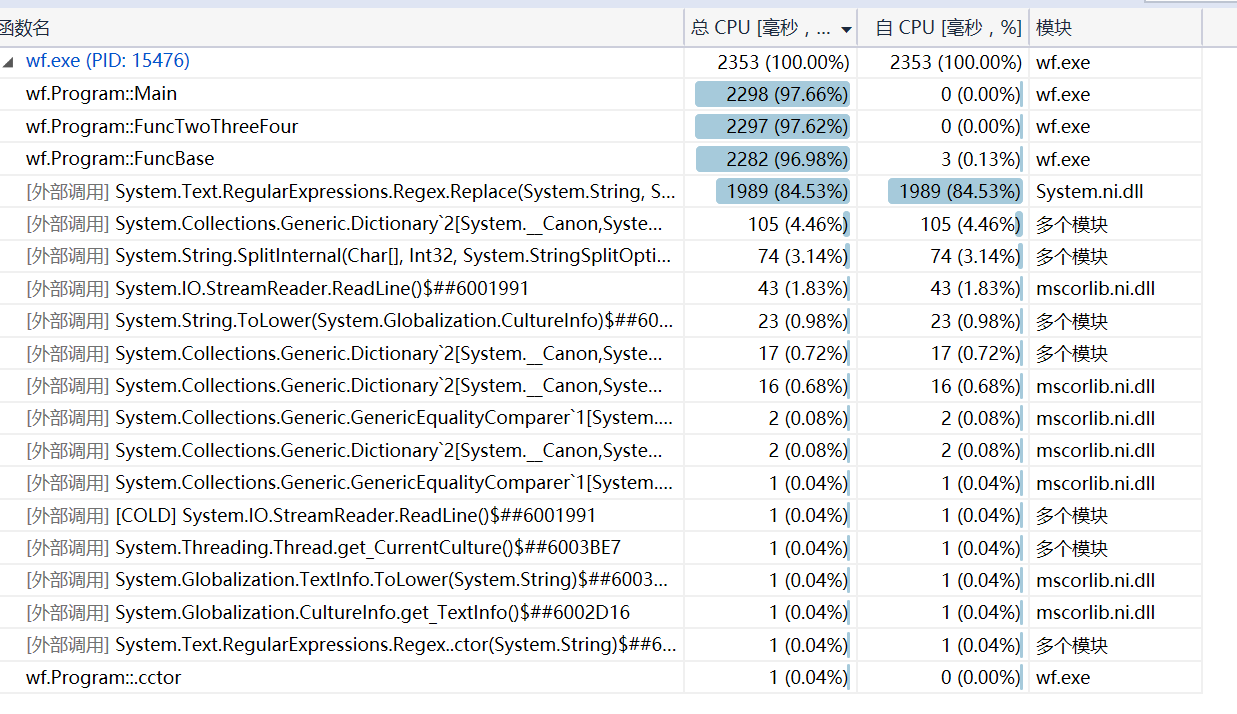

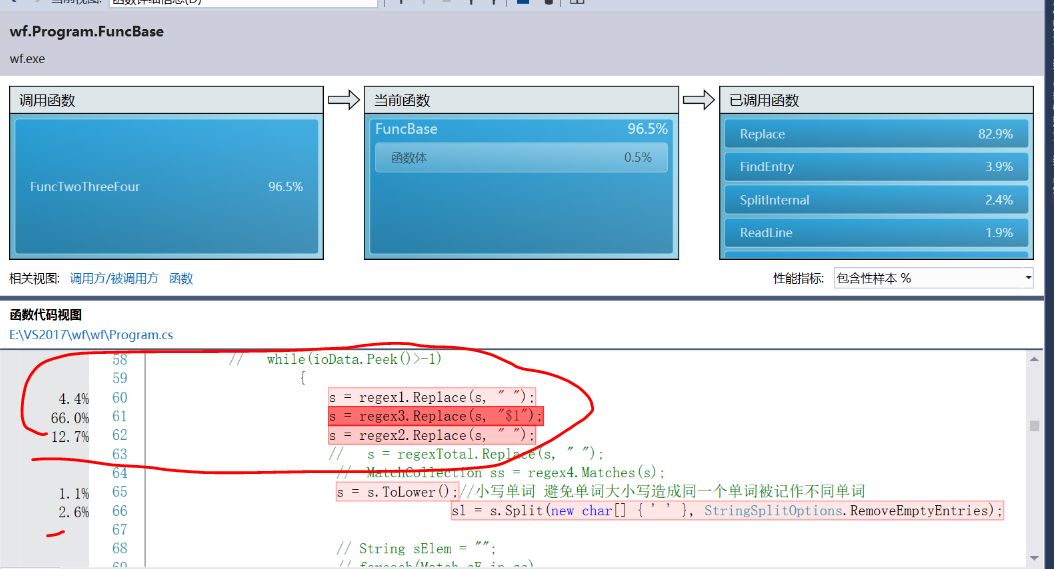
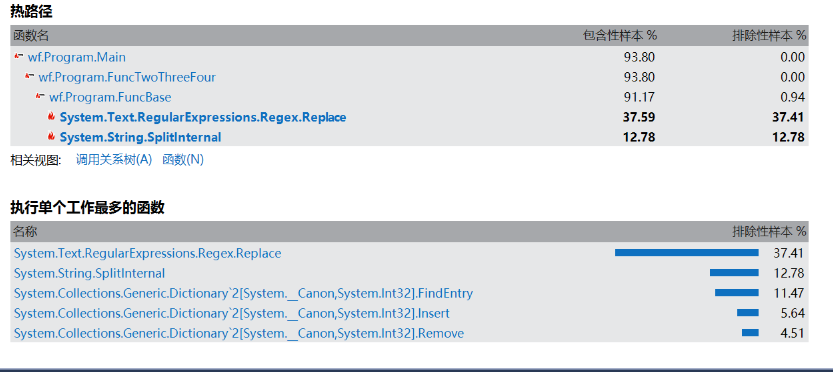
从图分析得知,调用最多的三个函数的名称为Replace、FindEntry以及SplitInternal。Replace占用82.9%的时间,是主要的效能瓶颈。目前用来replace的三个正则表达式分别是用空格来替换数字和换行、用空格来替换标点,短横线不替换、上撇号后面的内容舍去。正则表达式1(regex1)用时占比4.4%,正则表达式(regex2)用时占比12.7%,正则表达式3(regex3)用时占比66.0%。正则表达式3需要捕获匹配到的内容并替换原来的字符串,这里的查找+替换操作可能比较费时?
四、程序改进
从profile分析0我发现了正则匹配字符串时最费时,于是乎,将正则表达式1(regex1)和正则表达式(regex2)合并成一个正则表达式,减少正则匹配的次数。同时,将正则表达式2((regex2))对标点符号的匹配改成将标点符号枚举出来,同时去掉正则表达式3(regex3)(形如I'm 的单词出现频率相对于整篇文章所占比例低)。总的来说一定程度上损失了程序统计单词的正确度,换来效率的提升。
static private Regex regexTotal = new Regex(@"[~!@#$%^&*()+=|\}]{[:;<,>?/""]+|d|
", RegexOptions.IgnorePatternWhitespace);
// s = regex1.Replace(s, " ");
// s = regex3.Replace(s, "$1");
// s = regex2.Replace(s, " ");
s = regexTotal.Replace(s, " ");
五、profile分析1
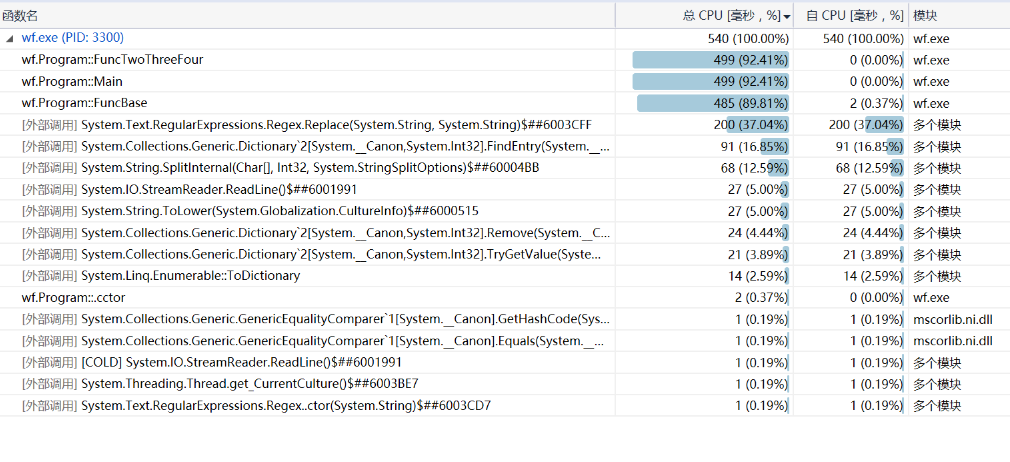
| Replace用时(ms) | FindEntry用时(ms) | SplitInternal用时(ms) | |
|---|---|---|---|
| profile分析0 | 1989 | 105 | 74 |
| profile分析1 | 200 | 91 | 68 |
补充:其实应该多次测量取平均值。单次测试值其实并不具有代表性。
六、第二次分析
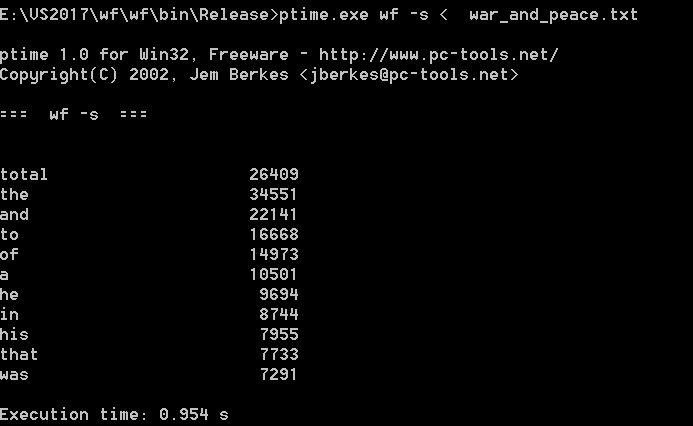
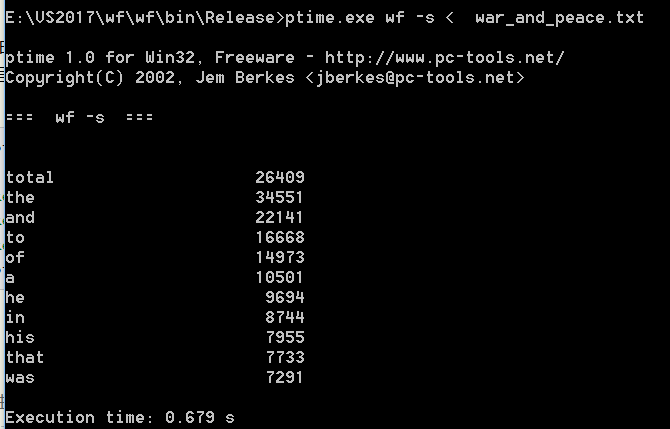
| 次数 | 消耗时间(s) |
|---|---|
| 第一次 | 0.952 |
| 第二次 | 0.679 |
| 第三次 | 0.710 |
| 平均 | 0.781 |

七、单词统计结果分析
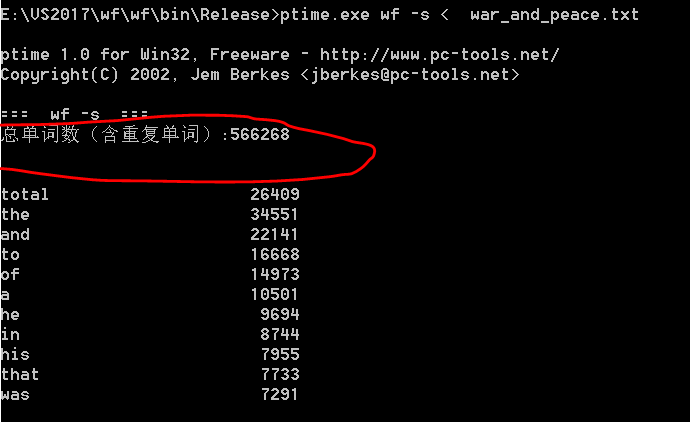
未优化前获得单词总数为565760,优化一次后获得单词总数566268,从word统计测试用例《战争与和平》单词总数为568286。
未优化误差为2526,优化一次后的误差为2018。从数据上看貌似优化后更接近word统计的单词数。
画红圈图为程序优化一次后的运行结果截图如下。
未优化程序的运行结果截图如下。
