业务场景:筛选项原功能是用mysql左模糊进行过滤查询,现业务要用es,怎么样才能满足原功能,又不损性能。
elasticsearch中有关于模糊查询的操作:wildcard
文档:https://blog.csdn.net/qq_22612245/article/details/82432107
另外的思路解决方案:使用分词
1、筛选项是中文类型
例:商品名称 :无糖麦芽糖口香糖
筛选这种,用中文分词即可满足业务场景
索引定义
"shopname": { "analyzer": "ik_max_word", "type": "text", "fields": { "raw": { "type": "keyword" } } }
2、筛选项是字母加数据类型
例:商品代码:abcde0001
因为在mysql中是左模糊,用户可能会筛abcde、abc、ab、abcde0、abcde0001,这种用中文分词就不能满足业务,而用es的wildcard性能不好,
综合考虑使用ngram分词器。
使用方法:
创建索引
{ "settings": { "analysis": { "analyzer": { "my_analyzer": { "tokenizer": "my_tokenizer" } }, "tokenizer": { "my_tokenizer": { "type": "ngram", "min_gram": 2, "max_gram": 3, "token_chars": [ "letter", "digit" ] } } } }, "mappings": { "properties": { "id": { "type": "keyword" }, "shopcode": { "analyzer": "my_analyzer", "type": "text", "fields": { "raw": { "type": "keyword" } } } } } }
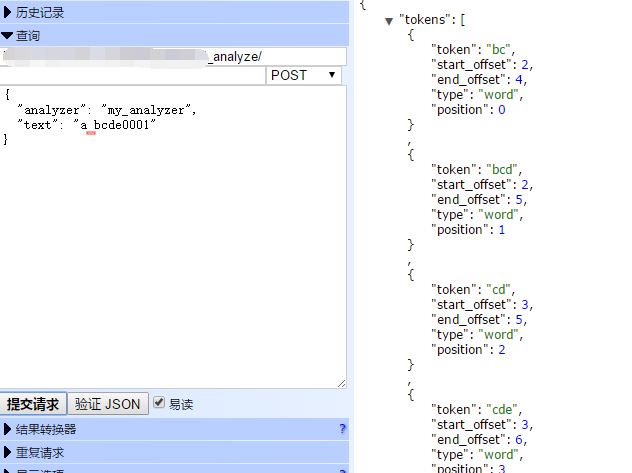
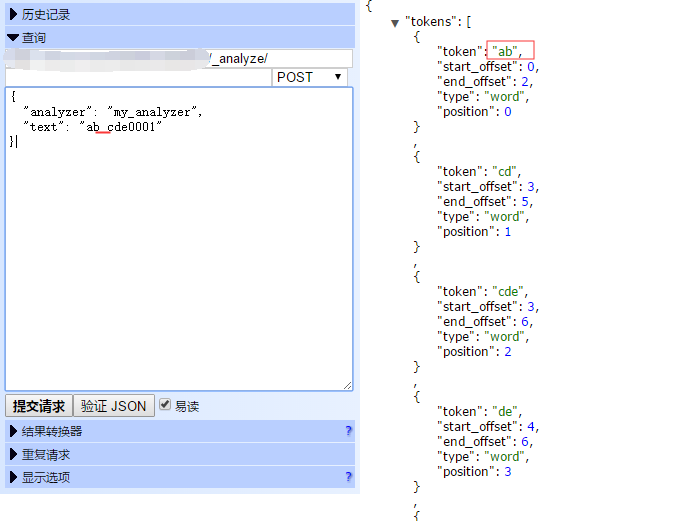
验证方法
POST my_index/_analyze { "analyzer": "my_analyzer", "text": "abcde0001" }
结果:

"min_gram": 2,"max_gram": 3, 这里是设置切的粒度,如果min设为1的话,切的粒度就太细,会占储存容量。
就算是设置成2,3也要注意因数据量过大分词后所占容量变多的情况
有空格的情况: