文件系统
1.ext2文件系统

注意:文件名并没有存储在inode中,目录的大小为4096,用ls显示的是蓝色的,目录、记录项。组里边有多少块,取决于块的大小。
磁盘分区完毕后还需要进行格式化(format),之后操作系统才能够使用这个分割槽。 为什么需要进行『格式化』呢?这是因为每种操作系统所配置的文件属性/权限并不相同, 为了存放这些文件所需的数据,因此就需要将分割槽进行格式化,以成为操作系统能够利用的『文件系统格式(filesystem)』。
stat 文件名,可以查看IO块大小,文件大小,以及Inode号,硬链接数,权限等信息。
(1)block:
对于ext2/ext3文件系统而言,硬盘分区被划分为一个个的block。一个block的大小是由格式化的时候确定的,并且不可以更改。例如mke2fs的-b选项可以设定block大小为1024、2048或4096字节(都是扇区大小512的整数倍)。而上图中启动块(Boot Block)的大小是确定的1024字节,启动块是由PC标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能使用启动块。
(2)Block Group:
启动块之后才是ext2文件系统的开始,ext2文件系统会根据分区的大小划分为数个Block Group。而每个Block Group都有着相同的结构组成。
(3)Super Block:
SuperBlock描述整个分区的文件系统的信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。还有一个valid bit数组,来记录此文件系统是否被挂载。Super Block在每个块组的开头都有一份拷贝。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。
(4)GDT,Group Descriptor Table
Group Descriptor Table,块组描述符。整个分区分成多少个块组就对应有多少个块组描述符。每个块组描述符(Group Descriptor)存储一个块组的描述信息,块位图块 号,inode位图块号,inode表块号,数据块快号,空闲inode计数,空闲块计数,自由块计数等等。如果一旦块组描述符意外损坏就会丢失整个块组的数(5)块位图(Block Bitmap)
(5)块位图
Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用。本身占用一个块的大小,主要使用其的一个bit位来代表本块组中的一个块,bit为1表示该块已用,这个bit为0表示该块空闲可用。
用df命令统计整个磁盘的已用空间非常快是因为只需要查看每个块组的块位图即可,而不需要搜遍整个分区。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。
一个块组中的块是这样利用的:数据块(Data Block)存储所有文件的数据,比如某个分区的块大小是1024字节,某个文件是2049字节,那么就需要三个数据块来存,即使第三个块只存了一个字节用df命令统计整个磁盘的已用空间非常快呢?因为只需要查看每个块组的块位图即可,而不需要搜遍整个分区。相反,用du命令查看一个较大目录的已用空间就非常慢,因为不可避免地要搜遍整个目录的所有文件。
与此相联系的另一个问题是:在格式化一个分区时究竟会划出多少个块组呢?主要的限制在于块位图本身必须只占一个块。用mke2fs格式化时默认块大小是1024字节,可以用-b参数指定块大小,现在设块大小指定为b字节,那么一个块可以有8b个bit,这样大小的一个块位图就可以表示8b个块的占用情况,因此一个块组最多可以有8b个块,如果整个分区有s个块,那么就可以有s/(8b)个块组。格式化时可以用-g参数指定一个块组有多少个块,但是通常不需要手动指定,mke2fs工具会计算出最优的数值
(6)inode位图(inode Bitmap)
和块位图类似,本身占一个块,其中每个bit表示一个inode是否空闲可用。
(7)inode表(inode Table)
正如前文所述的那样,一个文件的的数据信息被存储到数据块。除了文件名以外的其他文件信息和真正数据块的指向都是存放在inode中。每个文件都有一个inode,一个块组中的所有inode组成了inode表。inode Table占多少个块在格式化时就要决定并写入块组描述符中,每个inode的大小是固定的128bit,(inode存放文件的属性,文件的属性和内容是分开的)一个1024Bit大小的块里能存放8个inode所以格式化的时候就确定了inode的数目大小,而每个文件都会占用一个inode(硬链接除外),所以我们可以创建的文件的数目也是要受到inode数目大小的限制的。
(8)数据块 Data Block
对于常规文件,文件的数据存储在数据块中。
对于目录,该目录下的所有文件名和目录名以及i节点值存储在数据块中。 对于符号链接,如果目标路径名较短则直接保存在inode中以便更快地查找,如果目标路径名较长则分配一个数据块来保存。
设备文件、FIFO和socket等特殊文件没有数据块,设备文件的主设备号和次设备号保存在inode中。
命令 df
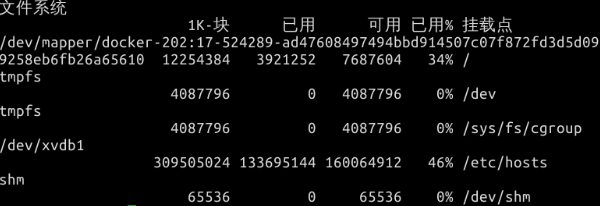
思考:hello文件是如何存进去的?
进入先在GDT中查找inode bit map,在inode bit map中查找哪个inode空闲,申请并将hello文件的描述信息写入,数据块指针(最多15个指针,若超过15个可采用间接寻址)指向数据数据块,文件内容在数据块,对应的的块位置。
在目录中查找某一个文件时,时根据文件名查找打记录项,根据记录项中的inode,对应查找数据指针,定位到具体的数据内容。
2.目录中记录项文件类型


3、数据块寻址
如果一个文件有多个数据块,这些数据块很可能不是连续存放的,应该如何寻址到每个块呢?实际上,根目录的数据块是通过其inode中的索引项Blocks[0]找到的,事实上,这样的索引项一共有15个,从Blocks[0]到Blocks[14],每个索引项占4字节。前12个索引项都表示块编号,例如上面的例子中Blocks[0]字段保存着24,就表示第24个块是该文件的数据块,如果块大小是1KB,这样可以表示从0字节到12KB的文件。如果剩下的三个索引项Blocks[12]到Blocks[14]也是这么用的,就只能表示最大15KB的文件了,这是远远不够的,事实上,剩下的三个索引项都是间接索引。
索引项Blocks[12]所指向的块并非数据块,而是称为间接寻址块(Indirect Block),其中存放的都是类似Blocks[0]这种索引项,再由索引项指向数据块。设块大小是b,那么一个间接寻址块中可以存放b/4个索引项,指向b/4个数据块。所以如果把Blocks[0]到Blocks[12]都用上,最多可以表示b/4+12个数据块,对于块大小是1K的情况,最大可表示268K的文件。如下图所示,注意文件的数据块编号是从0开始的,Blocks[0]指向第0个数据块,Blocks[11]指向第11个数据块,Blocks[12]所指向的间接寻址块的第一个索引项指向第12个数据块,依此类推。
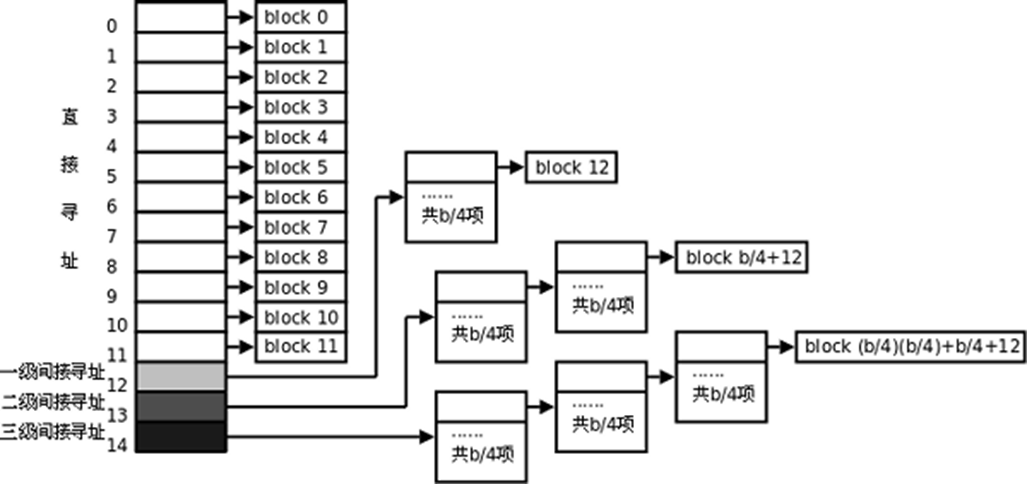
从上图可以看出,索引项Blocks[13]指向两级的间接寻址块,最多可表示(b/4)2+b/4+12个数据块,对于1K的块大小最大可表示64.26MB的文件。索引项Blocks[14]指向三级的间接寻址块,最多可表示(b/4)3+(b/4)2+b/4+12个数据块,对于1K的块大小最大可表示16.06GB的文件。
可见,这种寻址方式对于访问不超过12个数据块的小文件是非常快的,访问文件中的任意数据只需要两次读盘操作,一次读inode(也就是读索引项)一次读数据块。而访问大文件中的数据则需要最多五次读盘操作:inode、一级间接寻址块、二级间接寻址块、三级间接寻址块、数据块。实际上,磁盘中的inode和数据块往往已经被内核缓存了,读大文件的效率也不会太低。
4.链接
硬链接inode号和所链接的文件是一样的,相当于仅仅新创建了一个记录项。当rm删除文件时(硬链接),是将inode计数减一,并把记录项删除。当硬链接计数减为0时,才会真正的删除文件(将Block Bitmap翻转,并不时真正的将数据块清楚,过手机格式化之后数据不会真正的丢失,可以选择用大的数据包将其覆盖)
note:(1)硬链接通常要求在同一文件系统
(2) 符号链接没有文件系统限制
(3)通常不允许创建目录的硬链接,某些unix系统下超级用户可以创建目录的硬链接。(容易造成死循环)
(4)创建目录项以及增加硬链接计数应当是一个原子操作。
int symlink(const char *oldpath,const char *newpath);
ssize_t readlink(const char *path,char *buf,size_t bufsize );//读符号链接所指向的文件名字,不如文件内容。
int unlink(const char *pathname)
unlink作用:
(1)如果是符号链接,删除符号链接
(2)如果是硬链接,硬链接数减1,当减为0时,释放数据块和inode
(3)如果文件硬链接为0,但有进程已打开该文件,并持有文件描述符,则等该进程关闭该文件时,kernel才真正删除该文件
(4)利用该特性创建临时文件,先open或creat创建一个文件,马上unlink此文件。(如在线看视频,在看的时候缓存,关掉的时候自动清除,就是利用此技术)
5.有关文件系统的几个常用函数
rename
#include<stdio.h>
int rename(const char *oldpath,const char *newpath);
chdir
#include<unistd.h>
int chdir(const char *path);
int fchdir(int fd);
改变当前进程的工作目录
getcwd
#include<unistd.h>
char *getcwd(char *buf,size_t size);
char *getwd(char *buf);
char *get_current_dir_name(void);
获取当前进程的工作目录
示例:
#include<stdio.h> #include<,unistd.h> #define SIZE 4096 int main(void) { char buf[SIZE];
chdir("/");
printf("%s ",getcwd(buf,sizeof(buf)));
return 0;
}
输出:/
pathconf
#include<unistd.h>
long fpathconf(int fd,int name);
long pathconf(char *path,int name);
与文件或目录相关联的运行时限制(pathconf和 pathconf函数)
#include<stdio.h> int main(void) { printf("%ld ",fpathconf(STDOUT_FILENO,_PC_NAME_MAX); return 0; }
