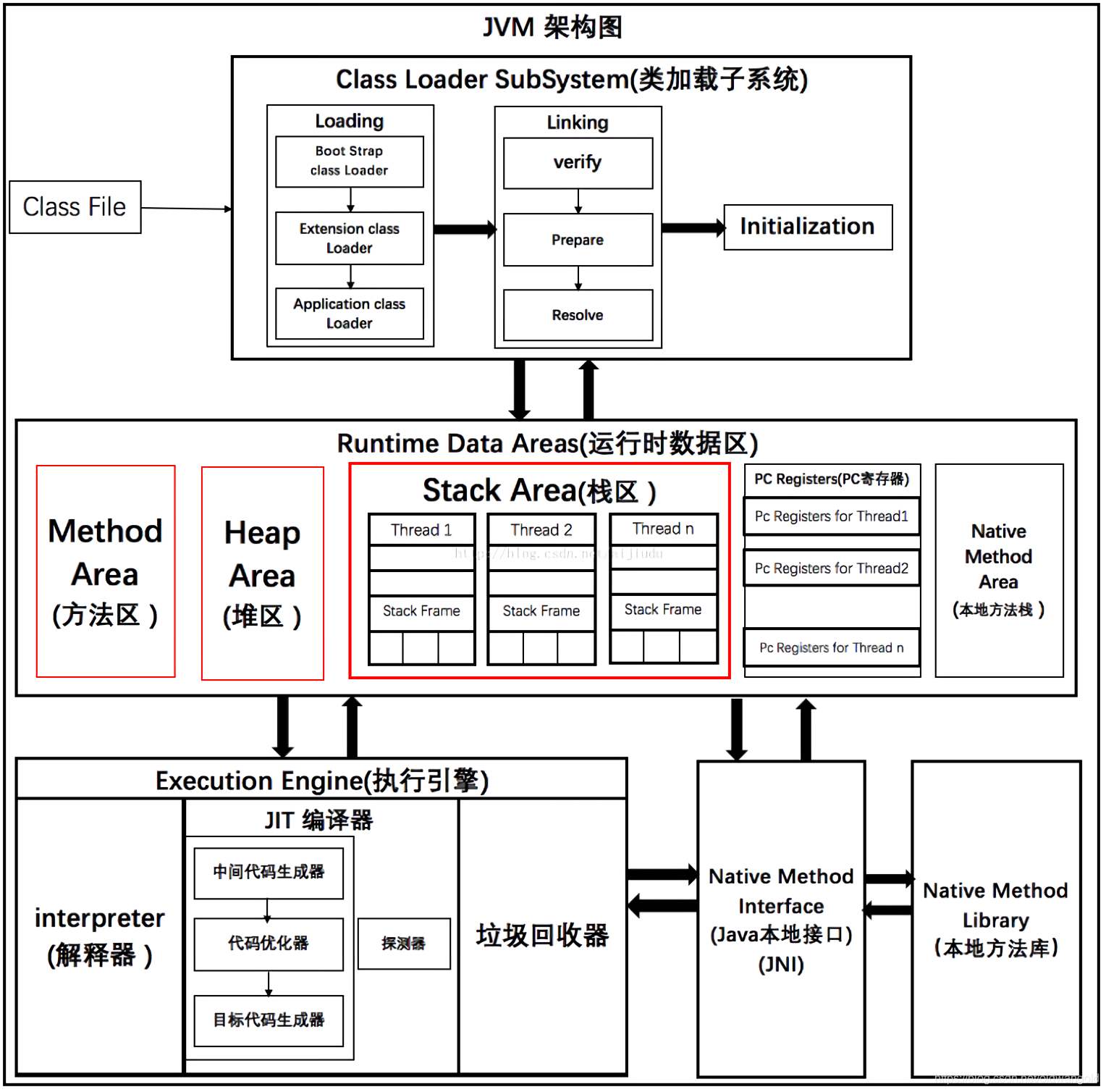
JVM架构
双亲委派机制
类装载器采用的机制是双亲委派模式:当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
BootstrapClassLoader启动类加载器:
c++编写,加载java核心库 java.*,构造ExtClassLoader和AppClassLoader。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作
ExtClassLoader标准扩展类加载器
java编写,加载扩展库,如classpath中的jre ,javax.*或者java.ext.dir 指定位置中的类,开发者可以直接使用标准扩展类加载器。
AppClassLoader系统类加载器
java编写,加载程序所在的目录,如user.dir所在的位置的class
CustomClassLoader用户自定义类加载器
java编写,用户自定义的类加载器,可加载指定路径的class文件
类加载器测试
public class Car {
public int age;
public static void main(String[] args) {
Car car = new Car();
System.out.println(car);
Class<? extends Car> aClass = car.getClass();
System.out.println(aClass);
ClassLoader classLoader = aClass.getClassLoader();
System.out.println(classLoader);//sun.misc.Launcher$AppClassLoader
System.out.println(classLoader.getParent());//sun.misc.Launcher$ExtClassLoader jre8libext
System.out.println(classLoader.getParent().getParent());//null rt.jar即root.jar
}
}
双亲委派机制源码
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
作用
1、防止重复加载同一个.class。通过委托去向上面问一问,加载过了,就不用再加载一遍。保证数据安全。
2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.clas,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
沙箱安全机制
Java安全模型的核心就是Java沙箱(sandbox),沙箱是一个限制程序运行的环境。沙箱机制就是将 Java 代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。沙箱主要限制系统资源访问:CPU、内存、文件系统、网络。
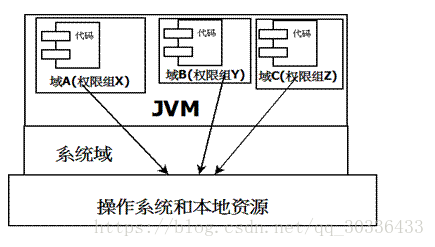
Native(JNI)
进入本地方法栈Native Method Area/Stack
public class Thread implements Runnable {
public synchronized void start() {
try {
start0();
}
}
private native void start0();
}
方法区
静态变量static、常量final、类信息Class(构造方法、接口定义)、运行时的常量池,都保存在方法区中,实例变量保存在堆内存中
栈
一种数据结构,先进后出。(main方法先执行,后结束)(区别于队列的先进先出FIFO)
存放的内容:基本数据类型、对象引用、实例方法
运行原理:栈帧,程序正在执行的方法一定在栈的顶部,栈溢出会报错StackOverFlowError
三种JVM版本
- Sun公司的HotSpot
- Oracle的JRockit
- IBM的j9 VM
堆
- Heap,一个JVM只有一个堆内存,堆内存的大小是可以调节的
- 存放对象的实例
- 堆里边还分三个区域:新生区(伊甸园区+幸存0区+幸存1区)、养老区、永久区(jdk8以后叫元空间)
- 轻GC、重GC(full GC)
- 垃圾回收主要在 伊甸园区 和 养老区
- OOM:java.lang.OutOfMemoryError: Java heap space
永久区
这个区是常驻内存的,用来存放Jdk自身携带的Class对象、Interface元数据,存储的是Java运行时的一些环境或类信息,这个区域不存在垃圾回收,关闭虚拟机释放。
- jdk1.6:永久代,常量池是在方法区
- jdk1.7:永久代,但是慢慢退化了,
去永久代,常量池在堆中(方法区) - jdk1.8:无永久代,常量池在元空间(方法区),逻辑上存在
JVM调优
public class Test {
public static void main(String[] args) {
long max = Runtime.getRuntime().maxMemory();//虚拟机试图使用的最大内存 默认电脑内存的1/4
long total = Runtime.getRuntime().totalMemory();//jvm初始化总内存 默认电脑内存的1/64
System.out.println("max:"+max+"byte,"+max/(double)1024/1024+"MB");
System.out.println("total:"+total+"byte,"+total/(double)1024/1024+"MB");
//OOM调试jvm调优:-Xms1024m -Xmx1024m -XX:+PrintGCDetails
}
}
项目中定位OOM的工具:Jprofiler(idea+windows)、MAT(eclipse)
- 能够看到代码第几行出错,内存快照分析
- 分析Dump内存文件,快速定位内存泄漏
- 获得堆中的数据
- 获得大的对象
import java.util.ArrayList;
//-Xms设置初始化内存分配大小 1/64
//-Xmx设置最大内存分配 1/4
//-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class Demo03 {
byte[] bytes = new byte[1024 * 1024];
public static void main(String[] args) {
ArrayList<Demo03> list = new ArrayList<>();
int count = 0;
try {
while (true) {
list.add(new Demo03());
count++;
}
} catch (Exception e) {
System.out.println("count:"+count);
e.printStackTrace();
}
}
}
当最小堆占满后,会尝试进行GC,如果GC之后还不能得到足够的内存(GC未必会收集到所有当前可用内存)分配新的对象,那么就会扩展堆,如果-Xmx设置的太小,扩展堆就会失败,导致OutOfMemoryError错误提示。
JVM调优汇总
1、堆大小设置
JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制、系统的可用虚拟内存限制、系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。原笔者在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-Xmx3550m:设置JVM最大可用内存为3550M。
-Xms3550m:设置JVM初始内存为3550m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k: 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。 - java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4:设置年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代)。设置为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5
-XX:SurvivorRatio=4:设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxPermSize=16m:设置持久代大小为16m。
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象在年轻代的存活时间,增加在年轻代即被回收的概率。
2、回收器选择
JVM给了三种选择:串行收集器、并行收集器、并发收集器,但是串行收集器只适用于小数据量的情况,所以这里的选择主要针对并行收集器和并发收集器。默认情况下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行判断。
-
吞吐量优先的并行收集器
如上文所述,并行收集器主要以到达一定的吞吐量为目标,适用于科学技术和后台处理等。
典型配置:
- java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC:选择垃圾收集器为并行收集器。此配置仅对年轻代有效。即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时多少个线程一起进行垃圾回收。此值最好配置与处理器数目相等。 - java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0支持对年老代并行收集。 - java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。 - java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100 -XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开。
- java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-
响应时间优先的并发收集器
如上文所述,并发收集器主要是保证系统的响应时间,减少垃圾收集时的停顿时间。适用于应用服务器、电信领域等。
典型配置:
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC:设置年老代为并发收集。测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明。所以,此时年轻代大小最好用-Xmn设置。
-XX:+UseParNewGC:设置年轻代为并行收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值。 - java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=5 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection:打开对年老代的压缩。可能会影响性能,但是可以消除碎片
- java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
3、辅助信息
JVM提供了大量命令行参数,打印信息,供调试使用。主要有以下一些:
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps -XX:+PrintGC:PrintGCTimeStamps可与上面两个混合使用
- -XX:+PrintGCApplicationConcurrentTime:打印每次垃圾回收前,程序未中断的执行时间。可与上面混合使用
- -XX:+PrintGCApplicationStoppedTime:打印垃圾回收期间程序暂停的时间。可与上面混合使用
- -XX:PrintHeapAtGC:打印GC前后的详细堆栈信息
- -Xloggc:filename:与上面几个配合使用,把相关日志信息记录到文件以便分析。
4、常见配置汇总
- 堆设置
- -Xms:初始堆大小
- -Xmx:最大堆大小
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
- -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
- -XX:MaxPermSize=n:设置持久代大小
- 收集器设置
- -XX:+UseSerialGC:设置串行收集器
- -XX:+UseParallelGC:设置并行收集器
- -XX:+UseParalledlOldGC:设置并行年老代收集器
- -XX:+UseConcMarkSweepGC:设置并发收集器
- 垃圾回收统计信息
- -XX:+PrintGC
- -XX:+PrintGCDetails
- -XX:+PrintGCTimeStamps
- -Xloggc:filename
- 并行收集器设置
- -XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
- -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
- -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
- 并发收集器设置
- -XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
- -XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
5、调优总结
-
年轻代大小选择
- 响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
- 吞吐量优先的应用:尽可能的设置大,可能到达Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。
-
年老代大小选择
-
响应时间优先的应用:年老代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、高回收频率以及应用暂停而使用传统的标记清除方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
- 并发垃圾收集信息
- 持久代并发收集次数
- 传统GC信息
- 花在年轻代和年老代回收上的时间比例
减少年轻代和年老代花费的时间,一般会提高应用的效率
-
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
-
-
较小堆引起的碎片问题
因为年老代的并发收集器使用标 记、清除算法,所以不会对堆进行压缩。当收集器回收时,他会把相邻的空间进行合并,这样可以分配给较大的对象。但是,当堆空间较小时,运行一段时间以后, 就会出现“碎片”,如果并发收集器找不到足够的空间,那么并发收集器将会停止,然后使用传统的标记、清除方式进行回收。如果出现“碎片”,可能需要进行如下配置:
- -XX:+UseCMSCompactAtFullCollection:使用并发收集器时,开启对年老代的压缩。
- -XX:CMSFullGCsBeforeCompaction=0:上面配置开启的情况下,这里设置多少次Full GC后,对年老代进行压缩
垃圾回收
GC的作用区域:方法区和堆
主要是回收新生代
- 新生代
- 幸存区(from,to)
- 老年区
GC有两种:轻GC,重GC(全局GC)
GC算法
引用计数法
计数为0的淘汰
缺点计数器成本
复制算法
GC执行时,将非垃圾对象复制到另一块内存空间中,并且保证内存上的连续性,然后直接清空之前使用的内存空间(from复制到to,谁空谁是新的to。)
好处无内存碎片,坏处也是显而易见的,直接损失了一半的可用内存。最佳实践:存货对象少,垃圾对象多的情况下,非常高效
标记清除法
扫描标记不可达对象,清除不可达对象
缺点两次扫面浪费时间+内存碎片,优点是不需要额外的空间
标记压缩
标记清除的方式之上,整理碎片
总结
内存效率:复制算法>标记清除算法>标记压缩算法(时间复杂度)
内存整齐度:复制算法=标记清除算法>标记压缩算法
内存利用效率:标记压缩算法=标记清除算法>复制算法
没有最好的算法,只有最合适的算法:分代收集
年轻代,存货率低:复制算法
老年代,存货率高:标记清除(碎片不是太多)+标记压缩