首先, 还是新建一个 jupyter notebook, 然后引入 csv 文件(此文件我已上传到博客园):
import pandas as pd
import numpy as np
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/6_handling_missing_data_replace/weather_data.csv')
df
输出:
从上面的输出截图, 可以看到有很多不合理的数据, 这时可以用 replace() 函数来处理:
new_df = df.replace([-99999, -88888], np.NaN)
输出: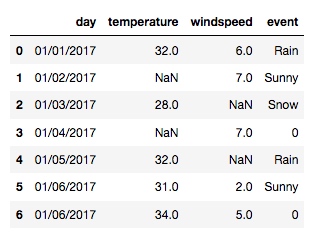
这时, 就还剩下 event 列里的 0 还没有改, 因为没办法简单粗暴地把数字 0 放到 replace 函数的数组里, 这样会影响其他列的值. 这个解决办法相信大家也都不会陌生了, 就是利用 python 的 dictionary:
new_df = df.replace({
'temperature' : -99999,
'windspeed':[-99999, -88888],
'event': '0'
}, np.NaN)
下面我们再来改下原 csv 文件, 把其中各别数据加上"单位":
如果我们想把多余的字母单位去掉, 可以用正则:
new_df = df.replace('[A-Za-z]','', regex=True)
这样替换之后, 大家可以看一眼输出结果, 发现 event 列的内容都没有了, 因为字母都被替换掉了. 所以还是要这样做:
new_df = df.replace({
'temperature': '[A-Za-z]',
'windspeed': '[A-Za-z]'
} ,'', regex=True)
下面再介绍另一个特性
首先
df = pd.DataFrame({
'score': ['exceptional', 'average', 'good', 'poor', 'average', 'exceptional'],
'student': ['rob', 'maya', 'jorge', 'tom', 'july', 'erica']
})
输出: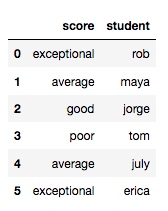
大家可以看到目前 score 列是用4个形容词来体现成绩的, 那如果想把它们按照等级换成 1-4分呢?
new_df = df.replace(['poor', 'average', 'good', 'exceptional'], [1, 2, 3, 4])
输出:
以上, 就是 replace() 函数的相关内容, enjoy~~~