所谓运行模式,就是指spark应用跑在什么地方。mr程序可以在本地运行,也可以提交给yarn运行。这个概念是一样的。
跟其他Hadoop生态圈的组件一样,spark也需要JDK的环境,此外还需要SCALA环境。所以在安装spark之前要先安装好JDK和SCALA。
( 我的 jdk 版本是 1.8 scala 版本是 2.11.8 hadoop 版本是 2.7.3 spark 版本是 2.2.1 都是源生的apache版本)
1、本地模式:
只要下载编译好的tar包,上传到服务器,在指定目录下解压,编辑 spark-env.sh即可。
解压后在spark的conf目录下有一个spark-env.sh.template文件,这是一个模板文件,最好不要直接修改,自己复制一份。
cp spark-env.sh.template spark-env.sh
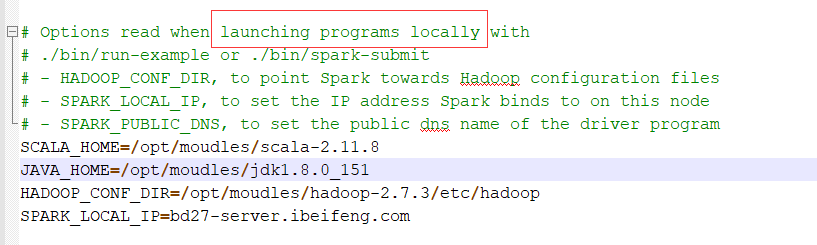
在配置文件中找到 launching programs locally 这一行。它表示如果是本地运行模式,需要配置哪些参数。
为了安全起见,又声明了一下JAVA_HOME和SCALA_HOME。
spark和mr一样,只是一个计算框架,本身不提供数据存储功能,数据可以是存储在本地的,也可以是存储在HDFS上的。
一般来说,数据都是存储在HDFS上,我们就需要建立spark和HDFS之间的连接,告诉spark HDFS在哪里。
而HDFS的信息,是配置在core-site.xml 和 hdfs-site.xml 这两个文件里的,只要能找到这两个文件,spark就可以知道HDFS的位置。所以我们只要告诉spark去哪里找这两个文件就行了。
到这里,本地运行模式就配置好了。测试一下:
既然是要使用HDFS,就需要先启动HDFS。
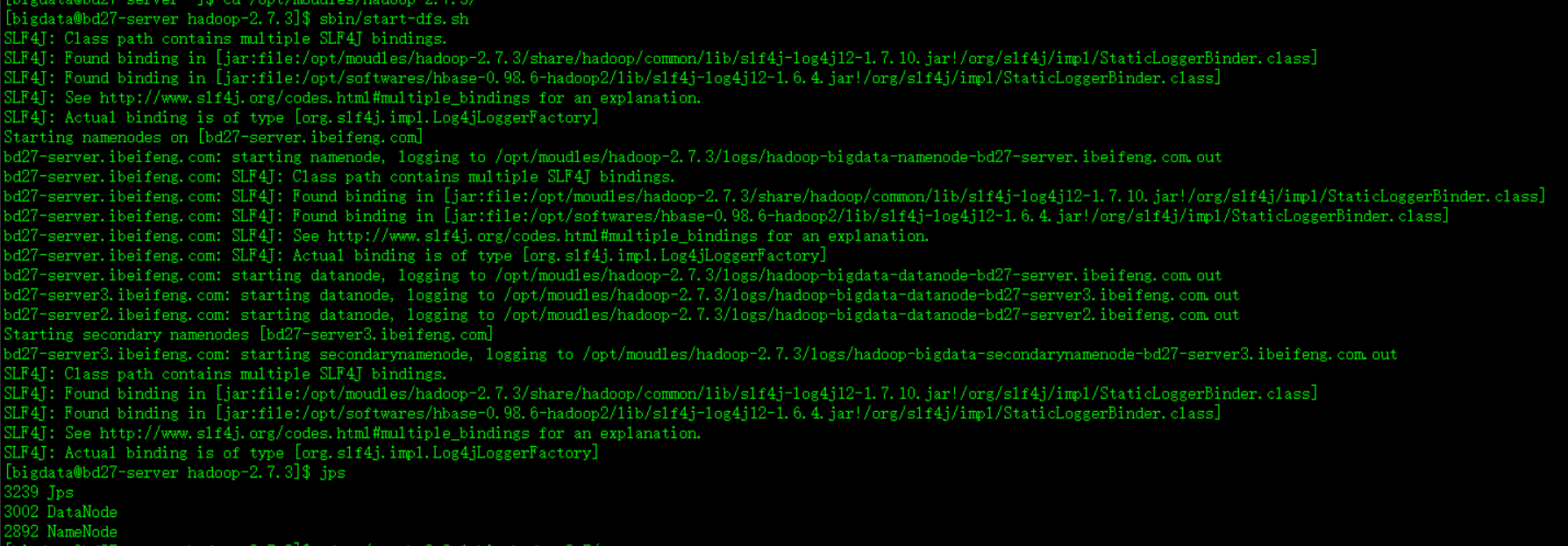
启动好HDFS,到spark的安装目录下,找到bin目录里面的命令 spark-shell 。 执行这个命令
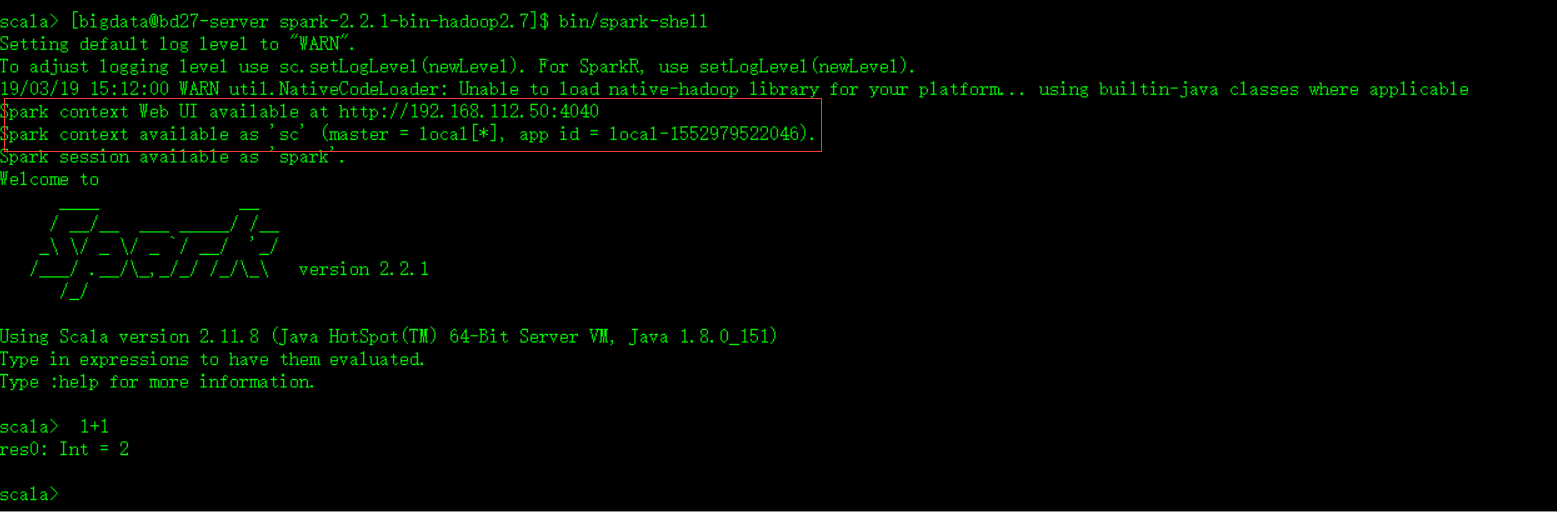
看到这个界面,spark本地模式就可以成功运行了。
可以看到提示符是 scala,说明这里可以敲scala代码。红框框里面的信息也比较重要。
敲一下spark官网的示例代码:

发现报错了,说文件不存在,给出的路径是 hdfs://bd27-server.ibeifeng.com:8020/user/bigdata/README.md。 也就是说 spark是到这个目录下面找输入文件的(我们只给了一个相对路径)。
[bigdata@bd27-server hadoop-2.7.3]$ bin/hdfs dfs -put /opt/moudles/spark-2.2.1-bin-hadoop2.7/README.md /user/bigdata/README.md
把这个文件上传到HDFS上,放到它默认去找的那个目录下面。

执行成功。
从这里我们可以看到,spark默认是到 HDFS 的 /user/用户名(我的用户名是 bigdata )/ 下面去找输入文件。

如果我们给它一个本地文件系统的路径,它也可以读取。但是我们要明确的给出 file:/// 这个schema。
为什么它默认读取HDFS呢? 就是因为我们给出了 HADOOP_CONF_DIR=/opt/moudles/hadoop-2.7.3/etc/hadoop 这个配置参数。相当于给出了 fs.defaultFS=hdfs://XXXXXXX
至于为什么执行第一句话不报错,执行第二句话会报错,那就是另一个话题了。