GitHub仓库地址:https://github.com/qwe8/personal-project
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 120 | 660 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 45 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 60 | 120 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 30 | 80 |
| · Test Repor | · 测试报告 | 10 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| | 合计 |450 |895
需求分析
对程序的功能进行需求分析如下:
统计文件的字符数,只需要统计Ascii码。
统计文件的单词总数,单词:至少以4个英文字母开头,跟上大小写字母数字符号,单词以分隔符分割,不区分大小写。
统计文件的有效行数:任何包含非空白字符的行,都需要统计。
统计文件中各单词的出现次数:输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
算法设计:
统计字符数和行数直接遍历,判断是否是单词也可以模拟一下,重点在于统计单词的次数和输出词频最多的单词。考虑如何统计单词的次数,很明显可以想到利用map,将单词放入map中++,但考虑到map的复杂度非常大(虽然纸面上是log级的,但map里存放字符串在常数会非常大,这是因为字符串的排序并不是O(1)的,会T得你怀疑人生),所以用map来统计单词次数不太好。
那么能用的数据结构有什么呢?目前我所知道的有两种,一是hash,二是字典树,首先这两种的时间复杂度肯定都完爆map,我选择用字典树来做而不选择hash,原因有四:
- 1 hash存在一定的碰撞率,要想降低碰撞率,可以增大空间,或者双重hash等等,但双重hash编码会变得复杂麻烦,时间加倍。
- 2 空间不知道开多大,题目并没有说单词数最多有多少,所以你空间开小了碰撞率急剧上升,空间开大了又变得臃肿,浪费。
- 3 hash的时间复杂度插入是O(n),字典树也是O(n)(n为单词长度),但hash的时间常数很大,因为其用到了乘法,还有取模,注意取模的复杂度相当于log,当然hash取值是O(1)的,字典树是O(n),但综合复杂度是字典树更优。
- 4 感觉写hash的人应该蛮多的,所以写写字典树。
以上分析都是我以为。
考虑要记录词频最多的10个单词,可以利用堆来存储,我使用stl的SET加pair来处理,首先SET是是一个可以自动排序的容器,插入删除查询时间复杂度为log级别,根据题目要求要排序两个东西,一个是单词词频,还有一个是字符串的字典序,可以将这两个东西放到pair当中,再将pair放入SET中,而SET里我们只需要放10个数据,多的删除即可。
算法到这里就设计完成了,字典树时间复杂度为O(N) (N为树大小,也差不多为单词字符数),记录词频最多10个单词时间复杂度为O(M*log(10)),由于没有用到复杂的运算,所以常数比较小。
计算模块实现过程
- 1 统计文件字符数:直接遍历到文件结束即可。
- 2 统计文件有效行数:整行读入,在遍历一遍数组,看是否存在非空字符。
- 3 统计文件的单词数:遍历输入的字符串,如果遇到连续一段合法字母或数字,将他们取出来,在判断开头是否存在4个字母,如果是单词的话,将这个单词插入到字典树中,然后单词数++即可。
字典树工作大概如下:
树上的节点定义为://gs为以这个字符为结尾的单词个数
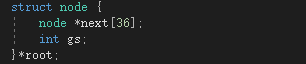
插入代词:
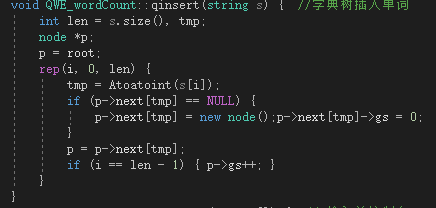
如果插入四个词,aa,aa,ab,bc(当然,这四个不属于所要求的单词,这里只是举个例子),那么树就会变成:
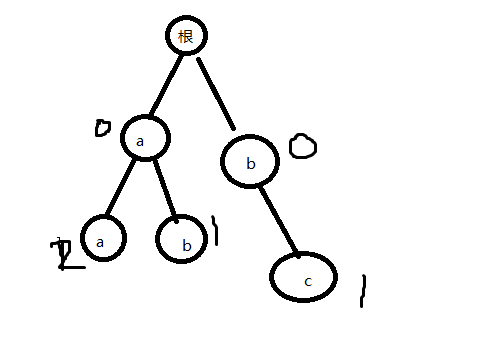
那么我们就可以通过遍历这棵树来找出所有单词的出现次数。 - 4 统计词频最大10个单词: 遍历字典树,遇到节点gs不为0就加入SET中,由于SET的排序是从小到大的,而我们要词频大的优先,所以我们只需要把gs变成负数即可,如果SET中数据个数大于10个,就删除最后一个。
整个功能被我封装成一个类:

各个函数之间的依赖关系:
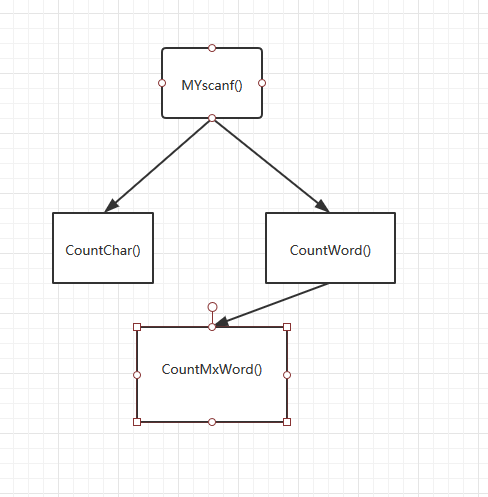
计算模块接口部分的性能改进
经行性能测试时,样例输入文件里有一百万个字符,两十万个单词,其中有十万个不同的单词。花费时间是4.95秒
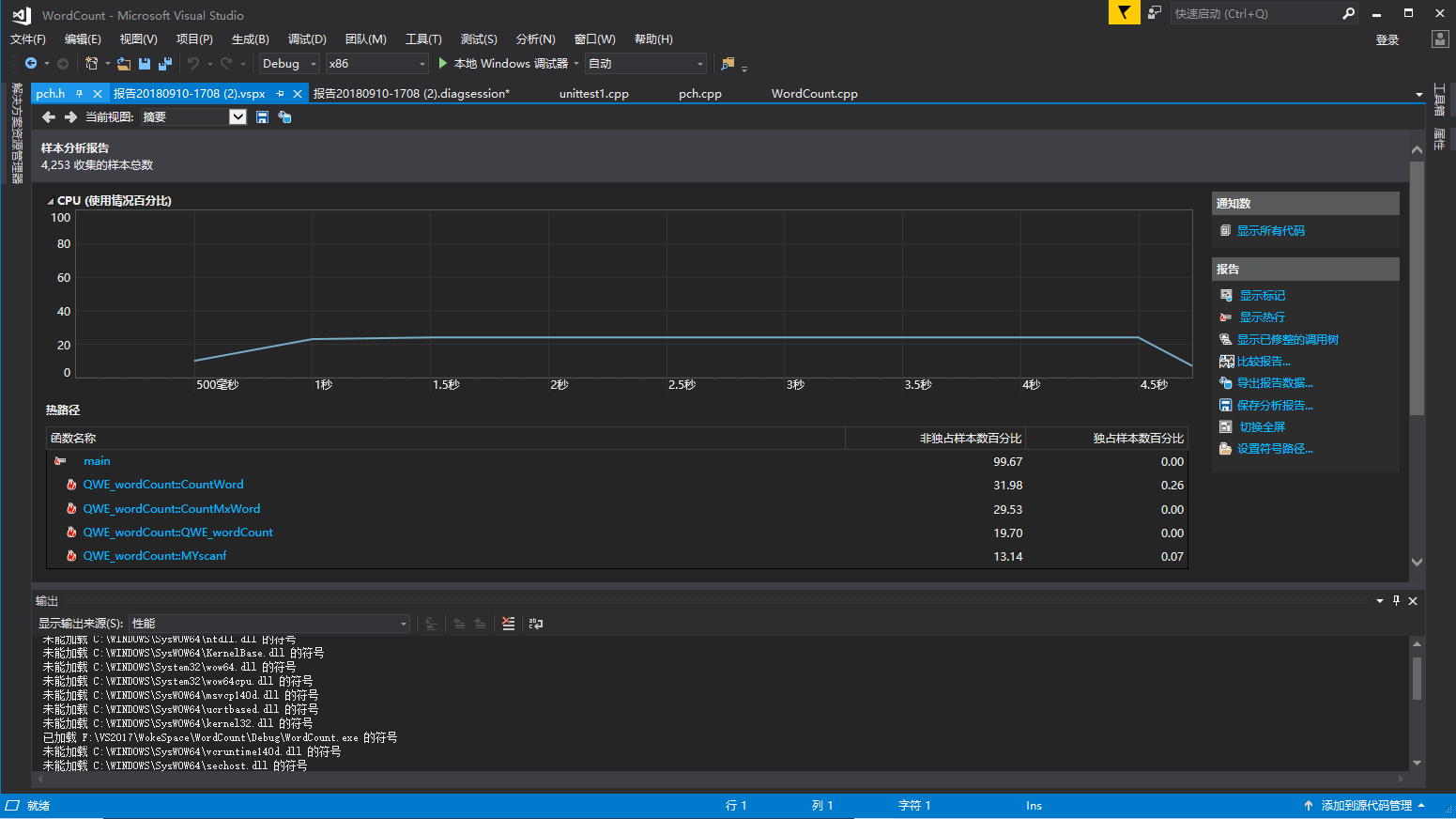
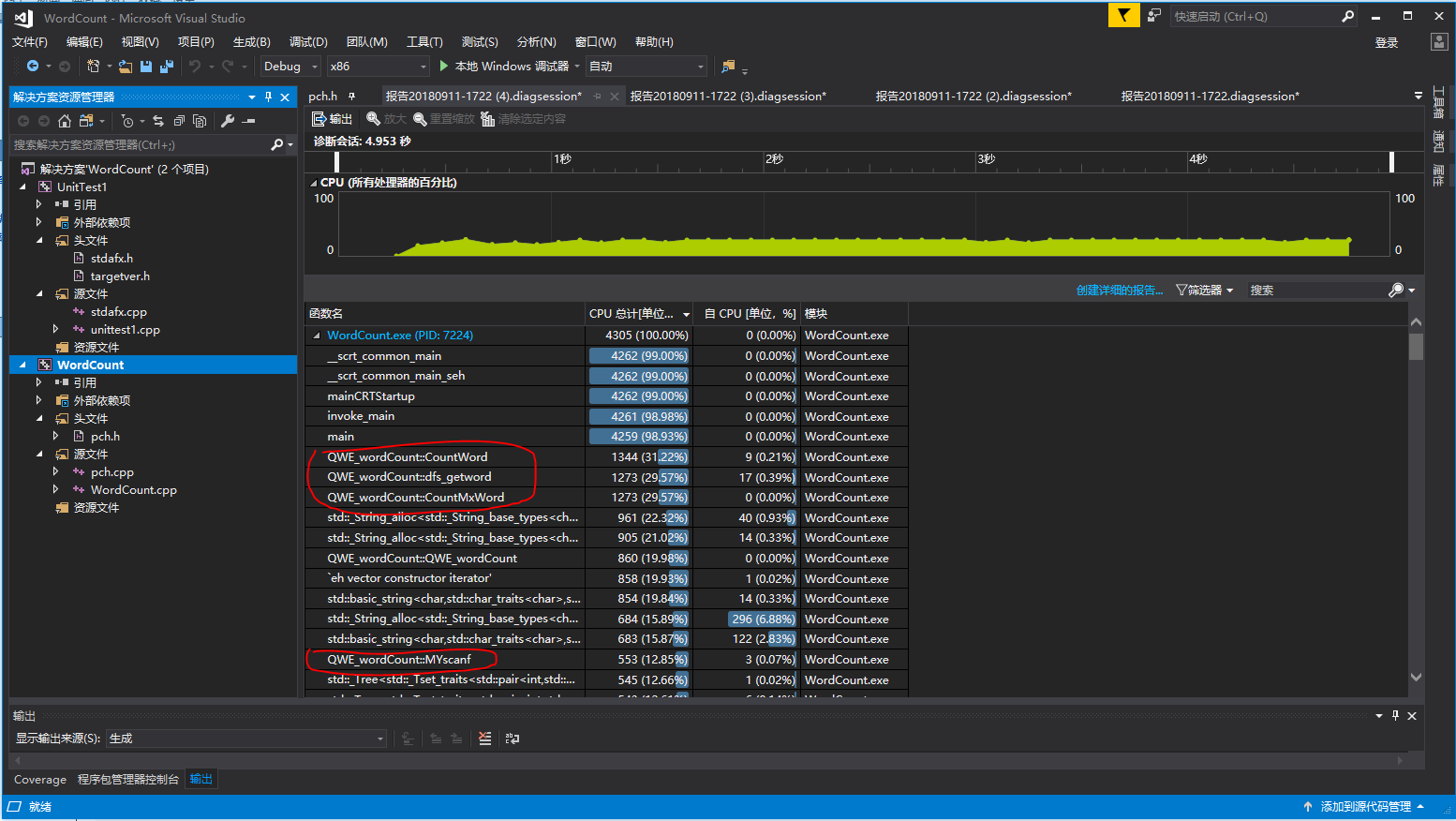
可以看到main函数占了99%的执行时间,在main函数中调用的几个函数中,CountWord()占用了31.98%的执行时间,CountMxWord()占用了29.53%的执行时间。
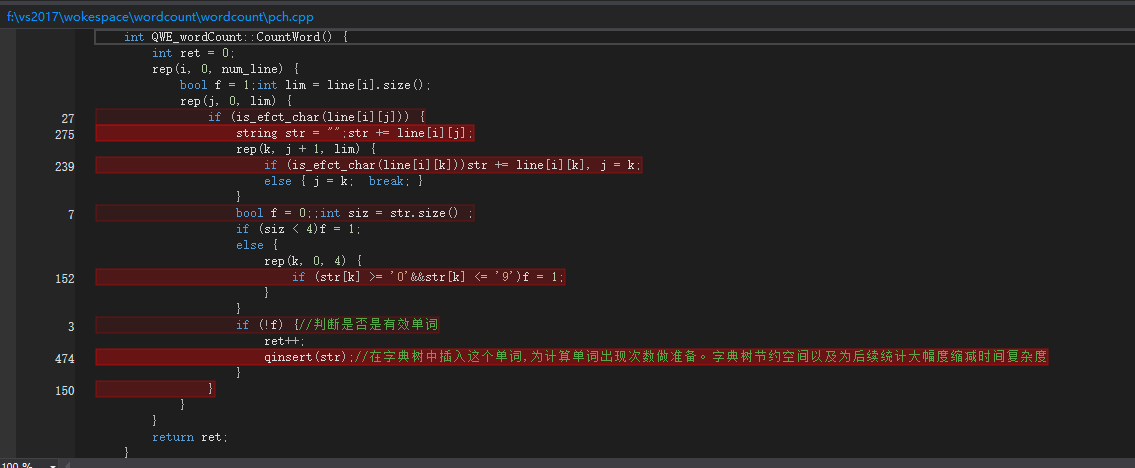
从算法的复杂度而言,这个程序的时间复杂度已经达到了我当前知识的最优了,要优化只能从一些小东西上入手,比如把c++的string改成char,cout改成print,少用c++的东西,因为比较慢。
计算模块部分单元测试展示
单元测试我构建了十一个样例,主要都是测试其功能的,下面展示部分测试:
TEST_METHOD(Testword)
{
A->init();
A->MYscanf("2.in");
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word,(int) 3);
// 测试统计单词数是否正确
}
TEST_METHOD(Testmxword1)
{
A->init();
A->MYscanf("3.in");
A->eft_word = A->CountWord();
A->CountMxWord();
A->it = A->qur.begin();
Assert::AreEqual(-A->it->first, (int)2);
Assert::AreEqual(A->it->second,(string) "qweee");
// 测试第一个最大词频单词
}
TEST_METHOD(Testmxword5)
{
A->init();
A->MYscanf("11.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)1000000);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)200000);
A->CountMxWord();
A->it = A->qur.begin();
Assert::AreEqual(-A->it->first, (int)2);
Assert::AreEqual(A->it->second, (string) "aaaa");
// 输入一百万个字符,二十万个单词,其中有十万种不同单词,用于测试性能
}
展示出来的第三个样例也就是我上面性能测试的样例
全部单元测试运行结果如下:
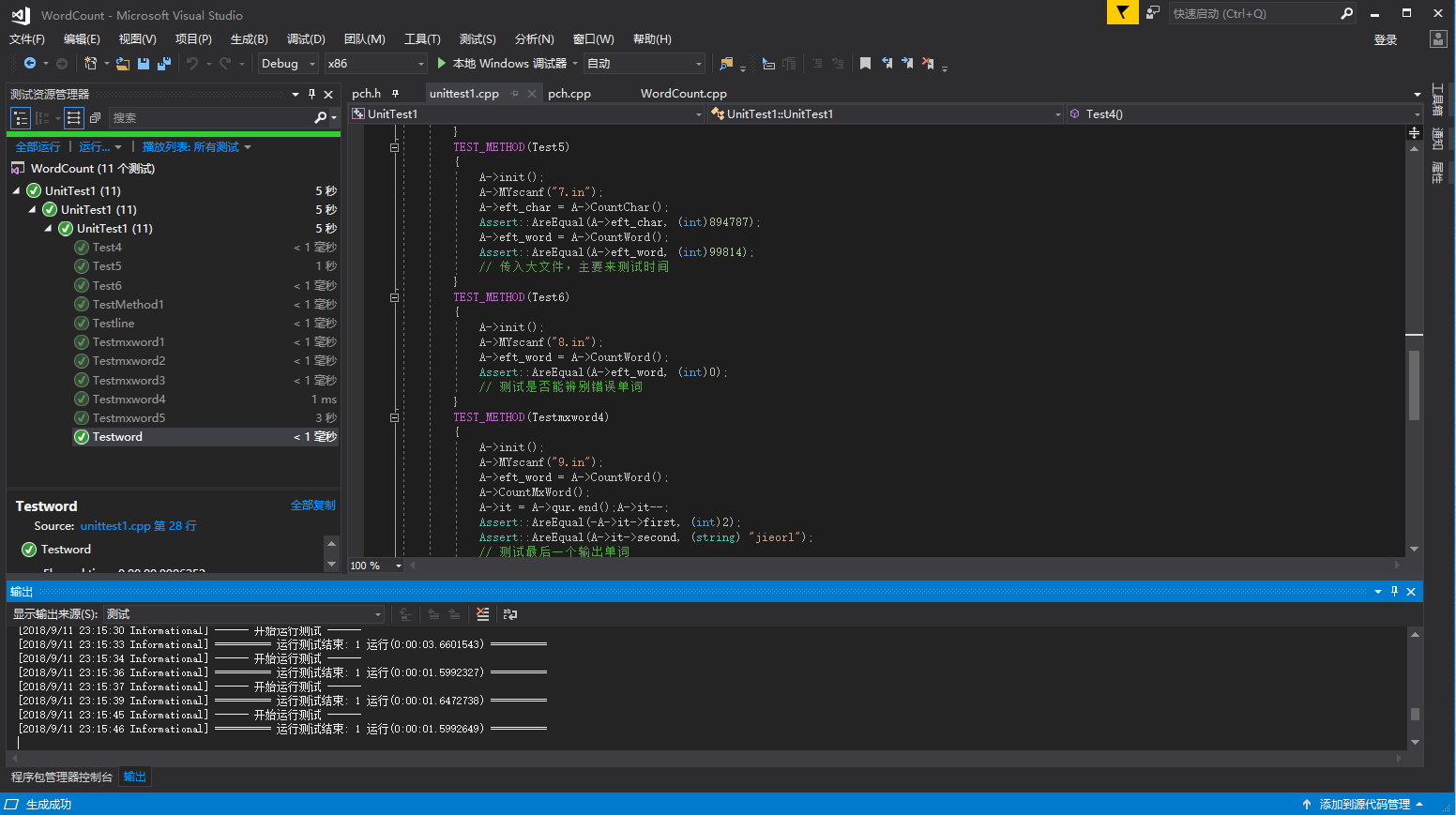
代码覆盖率:
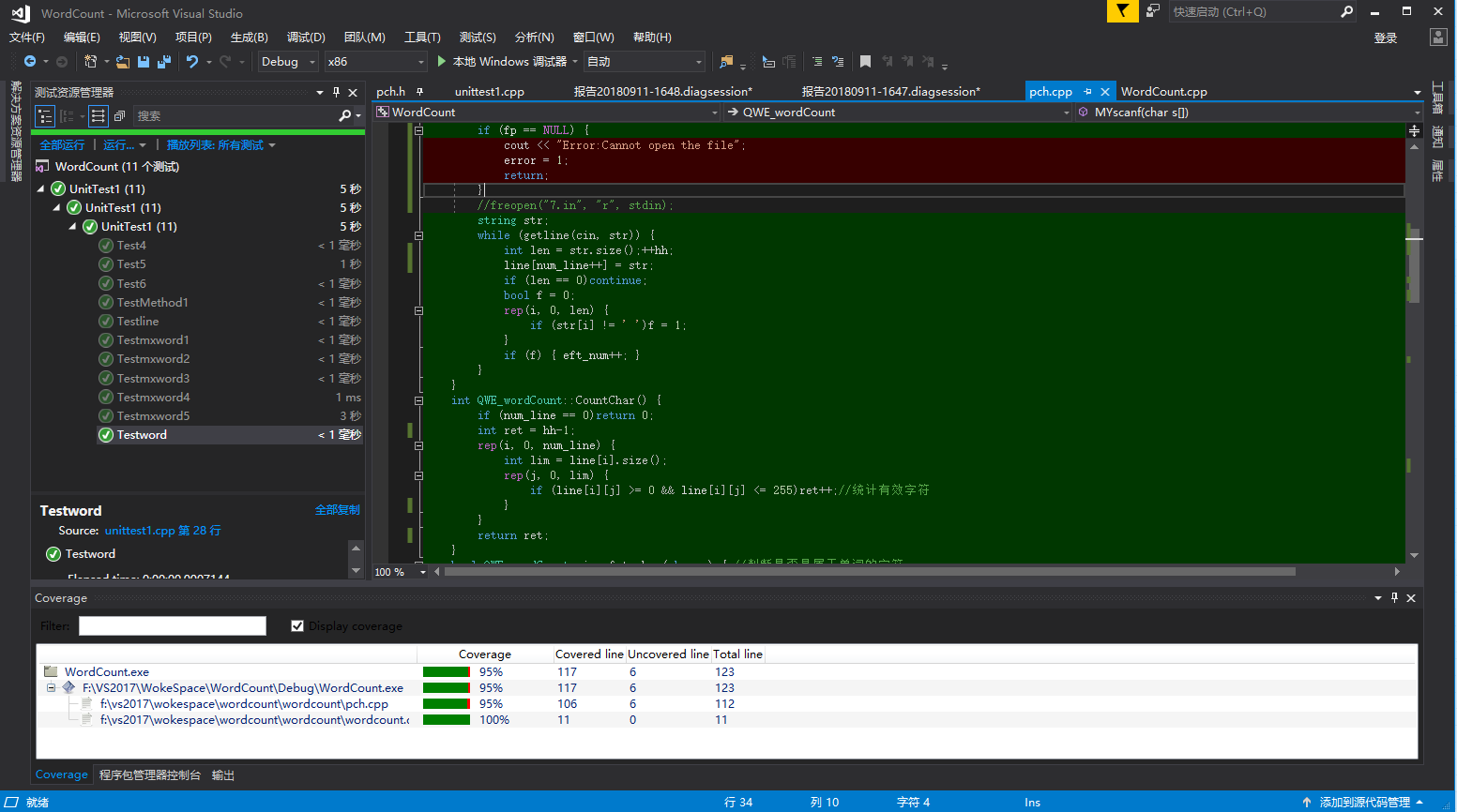
代码大部分都覆盖到了,就差个文件名出错时的代码没覆盖到。
异常处理
目前我只处理了三种情况,一种是输入错误文件名或文件不存在的情况,如下:
//测试单元
TEST_METHOD(Test4)
{
A->init();
A->MYscanf("6.in");
A->eft_char = A->CountChar();
Assert::AreEqual(A->eft_char, (int)0);
A->eft_word = A->CountWord();
Assert::AreEqual(A->eft_word, (int)0);
// 文件不存在。
}
处理代码:
fp=freopen(s, "r", stdin);
if (fp == NULL) {
cout << "Error:Cannot open the file";
error = 1;
return;
}
还有两种,分别是命令行参数过少或过多,处理如下:
int ifargcisok(int argc){
if(argc<=10){
printf("Error:Please input filename.
");
return 0;
}else if(argc>2){
printf("Error:Please do not enter too many parameters.
");
return 0;
}else return 1;
}
总结和感想
一开始做这个项目感觉这个项目很简单,没想到做起来如此之麻烦,和刷题真的是天差地别,刷题你不需要考虑什么封装啊,什么可读性啊,只要求运行速度足够快,代码足够简洁,能A就行,但做这种项目要考虑很多东西,还有各种测试,各种分析。我在这方面真的欠缺很多,比如看到刚看到题目,我想好了要用什么样的方法,然后我就直接莽过去写了,其实有很多地方没有考虑到,比如要如何封装,异常处理啊,等到全写完后才回过头来发现一些东西还没有覆盖到,然后又是各种添加新代码。
git是个很好用的开源社区,好久没用了,导致上传代码发生各种错误,还需继续学习。
通过这次个人项目,我学到了很多,也明白了项目和acm是有比较大的区别的,我将继续学习,为以后做大型的项目打下良好的基础。