ascii:字母,数字,特殊字符:1个字节,8位 Unicode:16位 两个字节 升级 32 位 四个字节 utf-8:最少一个字节 8位表示。 英文字母 8位 1个字节 欧洲16位,2个字节
中文24位,3个字节
gbk:中文2个字节,英文字母1个字节。
int:bit_lenth() 二进制的位数的长度
bool:True False
str: str --->bool :bool(str): ''--->False
str:
s = 'alexsb'
s1 = s[1]
s2 = s[1:3]
s3 = s[0:] s[:]
s4 = s[0:-1]
s5 = s[0:3:2]
s6 = s[2::-2]
capitalize首字母大写
upper()全大写
lower()全小写
find通过元素找索引,找不到-1
index()通过元素找索引,找不到 报错
swapcase 大小写翻转
replace(old,new,count)
isdigit() 返回bool值
isapha()
isnumpha()
startswith endswith
title 首字母大写
center()居中
strip()lstrip rstrip
split
format 格式化输出
{}
{0}{1}{2}{0}
{name}{age}{hobby} name= age+ hobby
len() 长度
count 计数
for i in 可迭代对象: pass
列表
增删改查
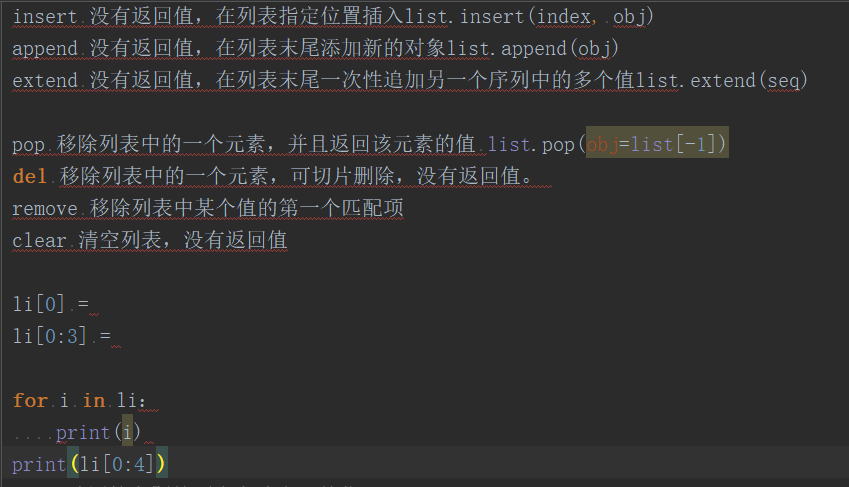
增:
li = [1,'a','b',2,3,'a'] # li.insert(0,55) #按照索引去增加 # print(li)
list.insert(index, obj)
- index -- 对象 obj 需要插入的索引位置。
- obj -- 要插入列表中的对象。
# # li.append('aaa') #增加到最后 # li.append([1,2,3]) #增加到最后 # print(li) # # li.extend(['q,a,w']) #迭代的去增 # li.extend(['q,a,w','aaa']) # li.extend('a') # li.extend('abc') # li.extend('a,b,c') # print(li)
extend挺特别,看一下例子:
li.extend('a,b,c')
最后输出的是:
['a', ',', 'b', ',', 'c']
extend如果后面是一个列表,就把列表里面的单个元素加到li里面,
如果是仅仅一个字符串,就把字符串每个字符分开行程一个个单一的元素添加到li。
列表的增
删:
# l1 = li.pop(1) #按照位置去删除,有返回值 # print(l1) # del li[1:3] #按照位置去删除,也可切片删除没有返回值。 # print(li) # li.remove('a') #按照元素去删除 # print(li) # li.clear() #清空列表
改:
# 改 # li = [1,'a','b',2,3,'a'] # li[1] = 'dfasdfas' # print(li) # li[1:3] = ['a','b'] # print(li)
查:
切片去查,或者循环去查
# for i in li: # print(i) # print(li[0:2])
总结:
其他操作。
count(数)(方法统计某个元素在列表中出现的次数)。
1 a = ["q","w","q","r","t","y"]
2 print(a.count("q"))
index(方法用于从列表中找出某个值第一个匹配项的索引位置)
1 a = ["q","w","r","t","y"]
2 print(a.index("r"))
sort (方法用于在原位置对列表进行排序)。
reverse (方法将列表中的元素反向存放)。
1 a = [2,1,3,4,5] 2 a.sort()# 他没有返回值,所以只能打印a 3 print(a) 4 a.reverse()#他也没有返回值,所以只能打印a 5 print(a)
列表的循环
for循环:用户按照顺序循环可迭代对象的内容。
msg = '老男孩python是全国范围内最好的python培训机构'
for item in msg:
print(item)
li = ['alex','银角','女神','egon','太白']
for i in li:
print(i)
dic = {'name':'太白','age':18,'sex':'man'}
for k,v in dic.items():
print(k,v)
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
li = ['alex','银角','女神','egon','太白']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1):
print(index,name)
for index, name in enumerate(li, 100): # 起始位置默认是0,可更改
print(index, name)
range:指定范围,生成指定数字。
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)
列表的嵌套
li = ['taibai','武藤兰','苑昊',['alex','egon',89],23] print(li[1][1]) name = li[0].capitalize() # print(name) li[0] = name li[0] = li[0].capitalize() li[2] = '苑日天' print(li[2].replace('昊','ritian')) li[2] = li[2].replace('昊','ritian') li[3][0] = li[3][0].upper() print(li)
元祖
元组被称为只读列表,即数据可以被查询,但不能被修改,所以,字符串的切片操作同样适用于元组。例:(1,2,3)("a","b","c")
#儿子不能改,孙子可能可以改。
tu = (1,2,3,'alex',[2,3,4,'taibai'],'egon') print(tu[3]) print(tu[0:4]) for i in tu: print(i) tu[4][3]=tu[4][3].upper() print(tu) tu[4].append('sb') print(tu) s = 'alex' s1 = 'sb'.join(s) print(s1) 列表转化成字符串 list -----> str join li = ['taibai','alex','wusir','egon','女神',] s = '++++'.join(li) str ----->list split() print(s) range [1,2,3,4,5,6,.......100........] for i in range(3,10): print(i) for i in range(10): print(i) for i in range(0,10,3): print(i) for i in range(10,0,-2): print(i) for i in range(10,-1,-2): print(i) li = [1,2,3,5,'alex',[2,3,4,5,'taibai'],'afds'] for i in li: if type(i) == list: for k in i: print(k) else:print(i) for i in range(len(li)): if type(li[i]) == list: for j in li[i]: print(j) else:print(li[i])