数据库规范化
第一范式(1NF)
第一范式(1NF):数据表中的每一列(每个字段)必须是不可拆分的最小单元,也就是确保每一列的原子性;如下图的表设计就不符合第一范式:其中”家庭地址”列还可以细分为城市、区、街道;在国外更多的程序把”姓名”列也分成2列,即”姓”和“名”。
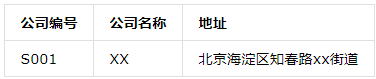
符合第一范式的设计应该是:

第二范式(2NF)
在1NF的基础上,非Key属性必须完全依赖于主键,要求表中的所有列,都必须依赖于主键,而不能有任何一列与主键没有关系。第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
如下图,一个表描述了公司信息,员工信息等,这样就造成了大量数据的重复,不符合第二范式:
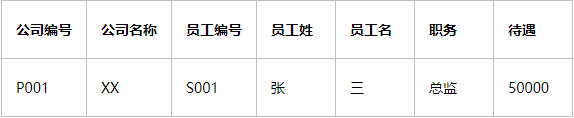
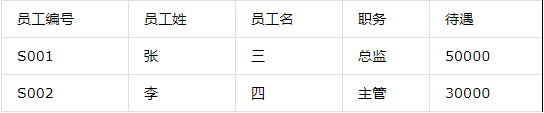
按照第二范式,我们可以将表进行拆分:

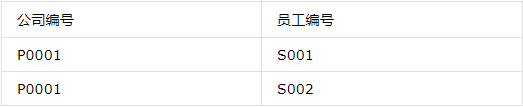
第三范式(3NF)
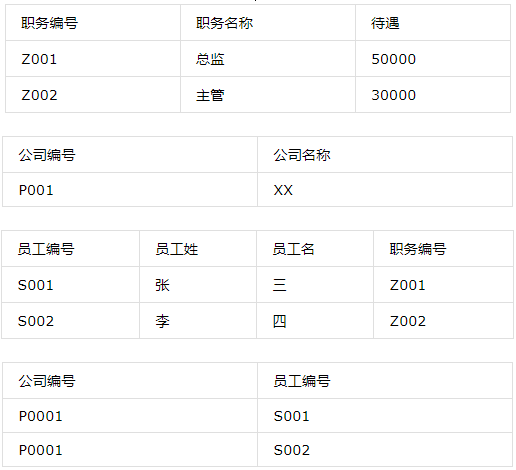
第三范式是在第二范式基础上,更进一层,第三范式的目标就是确保表中各列与主键列直接相关,而不是间接相关。即各列与主键列都是一种直接依赖关系,则满足第三范式。第三范式要求各列与主键列直接相关,我们可以这样理解,假设李四是张三的手下,王五则是李四的手下,这时王五是不是张三的手下呢?从这个关系中我们可以看出,王五也是张三的手下,因为王五依赖于李四,而李四是张三的手下,所以王五也是。这中间就存在一种间接依赖的关系而非我们第三范式中强调的直接依赖。
如上图中,在员工信息表中包含:”员工编号”、”员工姓”、“员工名”,”职务”、”待遇”,而我们知道,薪资水平是有职务决定,这里”薪资水平”通过”职务”与员工相关,则不符合第三范式。我们需要将员工信息表进一步拆分,如下:
范式与效率
在我们设计数据库时,设计人员、客户、开发人员通常对数据库的设计有一定的矛盾,客户更喜欢方便,清晰的结果,开发人员也希望数据库关系比较简单,降低开发难度,而设计人员则需要应用三大范式对数据库进行严格规范化,减少数据冗余,提高数据库可维护性和扩展性。由此可以看出,为了满足三大范式,我们数据库设计将会与客户、开发人员产生分歧,所以在实际的数据库设计中,我们不能一味的追求规范化,既要考虑三大范式,减少数据冗余和各种数据库操作异常,又要充分考虑到数据库的性能问题,允许适当的数据库冗余。
