一、总结本单元两次作业的架构设计
1. 第一次作业
第一次作业要求解析UML类图,实现查询功能。由于输入的UML元素是无序的,比较散乱,可以通过id和parentId等联系将输入的无序元素组合成一个树状结构。树的顶层结构是UmlClass和UmlInterface,其下层是UmlAttribute/UmlOperation/UmlAssociation/UmlGeneralization/UmlInterfaceRealization,而UmlOperation下层又有UmlParameter,所构造的树状结构如下。
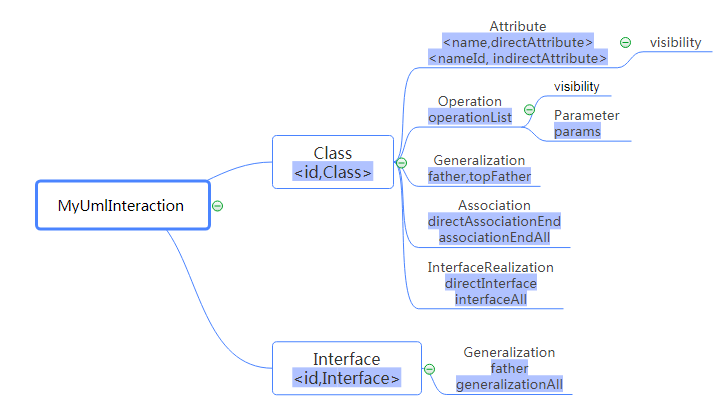
针对上图做几点解释:
- 图中的有色部分为为了实现树的连接或查询所使用的结构名。其中,<id,Class>表示这是一个键为id,值为Class结构的Hashmap,<id,Interface>同理。opeationList表示一个由Operation结构组成的ArrayList结构,params等同理。
- 为了提高查询的速度,大多采用Hashmap结构存储,使得通过元素的id可以快速访问元素结构。为了建立树状结构,对课程组下发的jar包中的某些类,我自行构造了一些结构,用于将不同的元素连接起来,例如:图中的Class/Interface/Operation均重新构造了MyUmlClass/MyUmlInterface/MyUmlOperation。
- 由于输入的UML元素是无序的,因此,在建立树状结构之前,我将每种元素暂时存放到了对应的队列中,再依次处理每种类型的结构并建树。需要注意的是,需要最先处理Class和Interface;对Parameter的处理要在Operation之前;在处理Association和AssociationEnd时,需要先记录下每个AssociationEnd的reference项对应的类或接口,再根据Association中的end1和end2项找到对应的AssociationEnd,从而找到对应的类或接口。这样才能保证按照树的层次建树,避免出错。
- 由于针对Attribute/Generalization/Association/InterfaceRealization的查询会涉及父类的情况,包含类的继承、接口的继承和类实现接口,因此,在自行构造的MyUmlClass结构中,针对这几种查询,我在存储本类自己的属性、关联对端、父类和直接实现的接口的同时,也存储了本类由于继承等原因得到的全部属性、关联对端、父类和实现的接口。这样,在进行相关的查询时,可以用递归的方式求得本类直接及间接得到的以上所有元素,且可以保证这种递归至多进行一次,从而减少了查询的时间。例如,在对Class中Attribute元素的管理时,使用<name,directAttribute>这个Hashmap表示本类自己实现的属性名和属性结构的键值对,<nameId,indirectAttribute>则表示本类所继承的各个类的nameId和这些类间接实现的属性结构的对应,从而在执行CLASS_ATTR_COUNT和CLASS_ATTR_VISIBILITY操作时可以通过直接访问本Class所管理的Attribute元素,较为快速地得到结果,而不需要在每次查询时都向上递归查找。
第一次作业的类图如下所示:
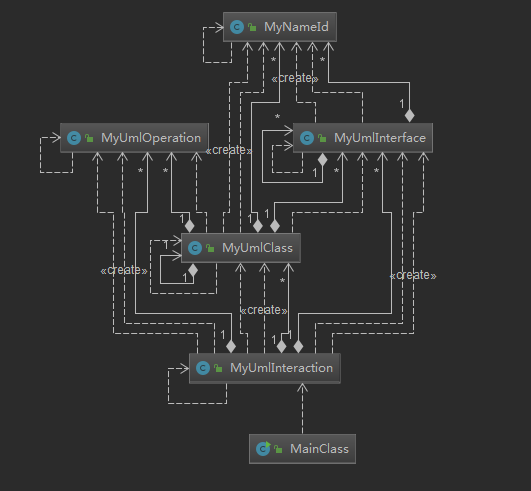
可见,各类之间的关联度比较高,从树状图中也可得知,由于MyUmlClass中记录了大量信息,使得这个类比较复杂,涉及的数据结构比较多,代码冗余度比较高。
2. 第二次作业
第二次作业在第一次作业的基础上增加了UML状态图、UML顺序图的查询和类的规则检查。其中,UML状态图和UML顺序图的查询较为简单,且他们与之前实现的UML类图在本次作业中处于平行地位(实际在UML中并不是平行的,例如:状态图是类图的下层结构),因此可以通过扩展第一次作业的树状结构实现查询。树状结构如下:
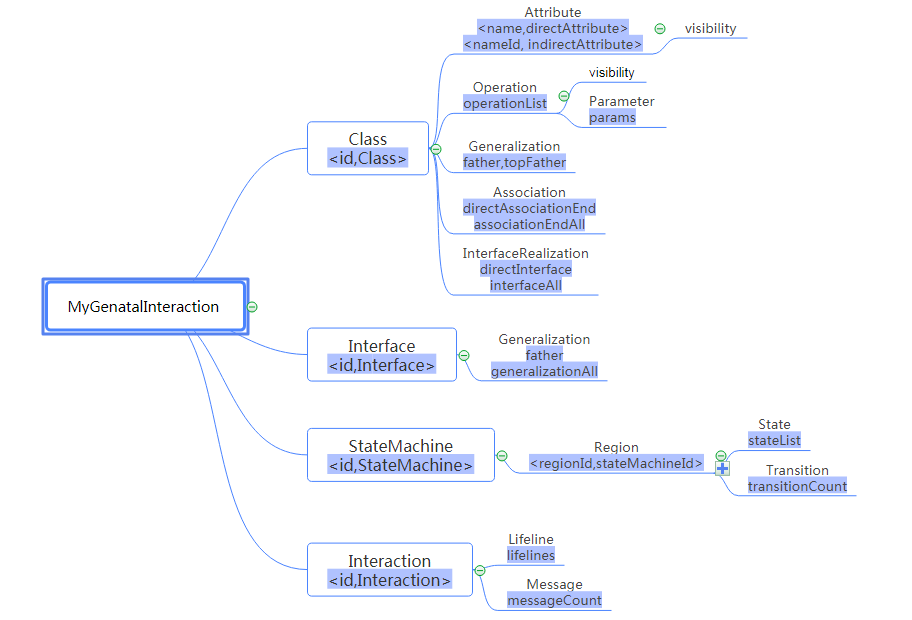
可见,类图部分与第一次作业中完全相同,仅仅增加了状态图和顺序图的分支。
与上一次作业相同,我依然对一些结构自行设计了相应的类,比如:MyUmlStateMachine/MyUmlState/MyUmlInterantion/MyUmlLifeline。
由于本次作业限制一个StateMachine中有且仅有一个Region,其状态图的状态和转移均是在这个region中的,因此Region这一层可以省略掉,我使用两个Hashmap使得一个状态通过两次查询找到自己对应的StateMachine。首先对于state结构,其中的parentId即为region的id,又通过<regionId,stateMachineId>可以得到这个状态所属于的状态机id,又通过<id,StateMachine>可以得到状态机结构,进而建立树结构。
由于本次涉及的状态一共有三种:PseudoState/State/FinalState,我将其归类于MyUmlState这一个类中。一开始的要求中可以存在状态机中有多个初始状态和终止状态的情况,且所有的初始状态会被解析为同一个初始状态,所有的终止状态会被解析为同一个终止状态。因此,我构造了TypeId这个结构并结合Set集合来计算状态机中的状态数目。这需要重写equals和hashcode函数,使得当状态类型相等并且都是初始状态或者都是终止状态时,不管id如何都判定为相等状态,否则,需要在类型和id都相等时才可以被判定为同一种状态,如下所示:
1 public boolean equals(Object o) {
2 if (o == null || !(o instanceof MyTypeId)) {
3 return false;
4 } else {
5 MyTypeId temp = (MyTypeId) o;
6 if (temp.getType().equals(this.type) && (this.type.equals("start")
7 || (this.type.equals("final")))) {
8 return true;
9 } else if ((temp.getId().equals(this.id)) &&
10 (temp.getType().equals(this.type))) {
11 return true;
12 } else {
13 return false;
14 }
15 }
16 }
17
18 public int hashCode() {
19 String str;
20 if (type.equals("normal")) {
21 str = id + " " + type;
22 } else {
23 str = type;
24 }
25 return str.hashCode();
26 }
此外,由于需要查询某个状态的所有后继状态,在自行构造的MyUmlState结构中,我增加了如下两个结构用来处理这种查询,
1 private ArrayList<MyUmlState> directSubsequentState; //直接后继
2 private Set<MyTypeId> subsequentStateIdAll = null; //全部可达后继状态
其中,subsequentStateIdAll使用上面所说的MyTypeId+Set集合并使用递归方法统计不重复的全部可达后继状态,与第一次作业不同的是,第一次作业所涉及的递归部分不会成环,即不会存在循环继承的情况,因此,如果需要求某个类通过继承得到的全部属性、关联对端等,至多进行一次递归;然而,可达后继有可能出现成环的情况,即出现类似A->B->C->A的状态转移,因此,为保证正确性,如果求某个类的全部可达状态,则需要重新递归计算(即使曾经算出来过结果)。
相比于状态图,顺序图的查询更加简单,且不会涉及递归的情况,由于需要查询IncomingMessage,在MyUmlLifeline类中有如下结构,用于记录所有IncomingMessage的id。
1 private Set<String> incomingMsgId;
除增加了对状态图和顺序图的查询之外,第二次作业还增加了对类图的三条检验。其中,R001和R003是在类和接口的角度检验,可以借助第一次作业的结构实现,只进行了简单的改写。R002是在全局的角度检验,为了能从全局的角度看到各个类和接口在实现、继承上的联系,我采用了图结构。图中的点表示一个类或接口,边表示类的继承、类实现接口和接口继承,那么,这就将R002转化成了“找出图中所有的环和环中的元素“,可以采用DFS实现这一检验。
第二次作业的类图如下,
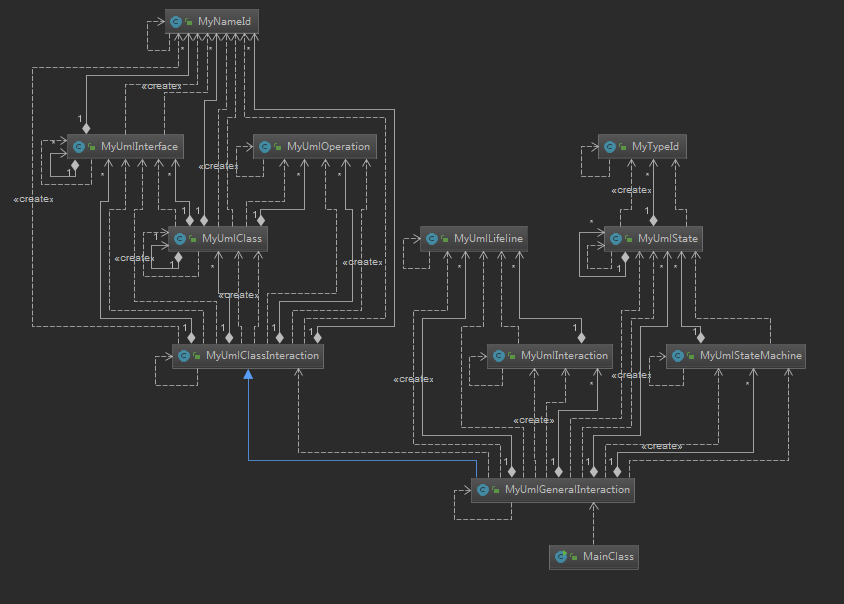
有关类图的查询和规则检查在MyUmlClassInteraction类中,有关状态图和顺序图的查询在MyUmlGeneralInteraction中,并采用继承实现所要求的全部接口。为构造树结构,类与类之间的关联度仍然比较高;为实现类图查询和规则检查,MyUmlClassInteraction中代码量较多,存在冗余。
二、总结自己在四个单元中架构设计及OO方法理解的演进
1. 第一单元
第一单元是一个从面向过程到面向对象的过渡单元,课程组通过递增式的任务让我认识到架构设计的重要性。
在第一次作业中,涉及的因子项比较简单,使用了求导类和因子类完成整个工程,在求导类中实现多项式合法性的检验和多项式的求导,并使用ArrayList结构存储多项式中的每个因子,在因子类中实现因子的求导。
在第二次作业中,增加了对正余弦函数的求导,使用主控类、求导类和因子类,主控类负责检验多项式合法性,求导类负责多项式求导和同类项合并,依然使用ArrayList结构存储求导后的结果,因子类负责不同因子求导。第二次作业的架构和第一次作业类似,尽管这可以勉强支持当前的任务要求,但是在第三次作业面前完全崩塌。
由于第三次作业可以支持嵌套求导,我重新推翻原来的设计,并采用树结构管理多项式。这也提醒我,在架构设计时,需要提高架构的可扩展性,这样,在新需求出现时,可以避免大量重写。第三次作业使用了继承构建多项式树,父类是结点类,子类有常数因子类、幂函数因子类、三角函数因子类、加法类、减法类、乘法类、嵌套类,并通过重写子类的求导方法,实现对多项式的求导,此外,仍采用主控类检验多项式合法性并构建多项式树。
由于在前两次作业中,还没有适应面向对象的思想,比较关注实现的细节,不太懂类应该怎么划分,也并没有很好地建立类之间的联系。在第三次作业中,使用树结构可以较好地描述因子、项、多项式之间的关系,将结点类之间的关系和各因子、项、多项式之间的关系相对应,并且采用继承实现树中的每个结点,通过重写求导方法,将分支结点的求导结果和左右子树的求导结果联系起来,通过调用根节点的求导方法即可实现对整个多项式的自动求导,更加具有面向对象的特征。
2. 第二单元
第二单元主要向我们介绍了多线程的思想,第一次作业旨在让我们学会多线程类共享时如何避免冲突,后两次作业则更考验大家的架构设计。
在第一次作业中,要求模拟傻瓜调度的单电梯,采用主类、电梯类和调度器类完成,电梯类以线程的形式存在,调度器类则作为共享类的形式存在,并使用synchronized避免冲突,主类则负责创建共享的调度器并启动电梯线程。
吸取了第一单元中架构可扩展性不足的经验教训,我在第二次作业时就开始考虑任务可能扩展的情况,并采用了”调度器负责电梯间调度,电梯内部调度算法负责乘客的调度“的架构,主要有主类、电梯类和调度器类。调度器仍作为共享对象的形式存在,调度器主要负责提供电梯线程主请求,给予电梯运动的方向,而在这过程中的ALS捎带算法则作为电梯内部的调度算法实现,电梯在每一楼层可以根据自己上下行的状态和电梯内外乘客的请求判断是否应该打开电梯门。在第一次作业中,大多将synchronized修饰词加到方法上,通过锁住方法所在的整个类,实现一个方法的同步,但这样效率较低,所以在第二次作业中,使用synchronized(object)的写法,只需锁住可能会产生冲突的对象,而不会锁住整个类,提高同步效率。
第三次作业是对第二次作业在广度上的扩展,延用了第二次的架构,由于第三次作业需要支持换乘,我使用了两层调度器,采用了主控类、请求类、电梯类、主调度器类、副调度器类。主调度器类以线程的形式存在,用于可以支持换乘,因此,电梯也成为了可以产生请求的一方。主调度器从输入和电梯采用一定调度算法将请求分配给对应电梯的副调度器,并由副调度器存储本电梯需要完成的请求。这里的副调度器与第二次作业中调度器的功能类似,给电梯提供主请求,并由电梯内部自行执行调度算法。此外,由于不同电梯具有不同参数,采用工厂模式实现电梯,增加了架构的可扩展性,在这种设计下,如果增加电梯的数目,需要改写的部分并不多。
在面向对象方面,三次作业中,均对调度器、请求、电梯建立不同的类,通过调度器管理请求队列和电梯,通过电梯内部的调度算法管理电梯内部请求,将请求的处理分成了调度器阶段和电梯阶段,更好地模拟现实世界中事物的联系。
3. 第三单元
第三单元主要内容为JML语言。鉴于有时工程项目比较大,需要团队合作完成,便可采用JML语言描述类和方法的行为,让他人可据此实现接口,从而完成整个工程的功能。这一单元主要提高了我阅读JML并实现相关代码的能力,但是自己写JML还不够熟练,可能存在一些逻辑上的问题。
第一次作业较为简单,只需要完成给定的MyPath类和MyPathContainer类即可。由于任务限制时间比较严格,在MyPath类中,除了使用ArrayList结构按序存储路径上的结点之外,还使用HashSet存储路径中不重复结点;在MyPathContainer类中,采用HashMap结构存储路径id到路径的双向映射,提高查询速度。
第二次作业在第一次的基础上引入了图结构,实现了图类,在图类中完成对图加减边的修改、最短路径算法以及结点连通性判断,并采用HashMap实现邻接表,用邻接矩阵缓存最短路径结果。
第三次是实现一个可换乘的地铁系统,分析可知,第三次作业实质是第二次作业在广度上的扩展,由于第二次作业中已经实现了图结构,在完成第三次作业时,基于第二次作业的架构,实现了4个边权不同的图——最短路径图、最小换乘图、最小票价图、最小不满意度图,并使用同样的最短路径算法。此外,由于第三次作业需要支持换乘,在建立图时与第二次作业有细微差别,采用拆点的方法,并增加”总点“将拆分的各点连接起来,这些所涉及的均是具体实现的部分,架构上讲,第三次作业基本沿用了第二次的架构,并将第二次作业中图类所包含的缓存矩阵分离出来,单独封装成类,提高灵活性。
本单元作业完成的过程中,均是先花费较大精力在架构设计上,分析好类的划分、结构的使用之后,再开始写代码,由于提前完成了架构设计,这使得在写代码的过程中不需要花费过多的脑力思考结构方面的问题,可以将更多的经历放在代码实现上,提高了写代码的效率和正确率,节省了debug的时间。
除了阅读指导书之外,本单元还需要阅读下发的jar包开源代码,由于每次实现的接口均是在原有的基础上递增的,故采用继承逐步实现每次作业的接口,将不同次作业的接口封装在不同的类中,便于维护。
由于第三单元所实现的类均是给定的,因此在面向对象方面并没有很好的体现。第一次作业仅实现了任务要求的MyPath和MyPathContainer类,后两次作业由于需要使用图结构,故建立了图类和缓存类用于计算最短路径,并在第三次作业中采用工厂模式实现不同边权的图。
4. 第四单元
作为课程的最后一单元,又面临考期的压力,第四单元将三次作业的内容压缩到了两次作业中,难度方面,我觉得第一次作业要难于第二次作业。
第一次作业要求实现类图的多个查询,针对UML元素间的联系,采用树结构将每个UML元素联系起来,将原本无序的UML元素输入有序化。为避免超时,除了采用查询时间复杂度较小的HashMap结构之外,还对于查询涉及父类的UML元素,缓存了父类包含的元素,防止多次递归增加时间。
第二次作业也是在广度上对第一次作业进行了扩充。由于在第一次作业中,采用了树形结构将UML类图的元素联系起来,在加入了状态图和顺序图之后,仅仅是给这个树增加了两个新的分支,因此,对于第一次作业实现的内容几乎不需要改动。此外,由于在第一次作业中已经缓存了因继承所实现的所有元素,第二次作业的规则检查部分可以依赖第一次作业中实现的这些结构来完成。
本单元作业也是花费了较长时间在架构设计上,尤其是第一次作业,这也让我意识到,一个好的架构,可以缩短在功能扩展时因设计所需要的时间,同时可以避免大规模的结构修改。
经过了前三个单元的训练,本单元在架构设计上更轻松;在面向对象方面,也可以通过自己实现一些类来刻画UML元素之间的关系,类的划分更合理,类之间联系的建立也更清晰。
三、总结自己在四个单元中测试理解与实践的演进
- 第一单元:手动构造测试样例,需要考虑每种情况。由于第一单元存在WRONG FORMAT的检测,构造的测试样例分为正常输入和异常输入两部分,且均要进行正确性测试和边界测试。测试的数据限制规定了输入数据的长度范围,因此除了进行常规长度输入的测试之外,还需要测试最大长度的输入,避免越界情况的出现。
- 第二单元:这一单元的测试主要难点在于实现在某个精确的时间点实时投放测试数据。为了解决这一问题,在IDEA的Terminal中使用命令行和管道”|“将测试程序的标准输出重定向到被测程序的标准输入,在测试程序中结合sleep(time)实现在某个精确的时间输出测试数据,并通过管道的重定向,将这一标准输出重定向到被测程序的标准输入。除了实现实时测试之外,测试数据的构造也需要考虑多方面,比如,由于第二单元使用了ALS捎带算法,因此测试数据需要考虑可捎带和不可捎带两种情况。由于多线程测试时的错误不可复现,因此,在最开始的测试时,主要关注代码逻辑,虽然多线程测试时使用断点是无法复现bug的,但是断点测试可以测出某个线程内部的逻辑问题,而线程间的逻辑问题需要手动在代码中插入System.out.print,并通过观察、分析输出查找代码的问题。
- 第三单元:由于这一单元是实现规定的接口,且存在一些自动化测试的工具,故采用手动测试和自动化测试相结合的方式。自动化测试方面,使用Junit4可以对实现的每个接口方法单独测试,通过构造测试样例,并采用AssertEquals断言比较,可以检验出每个接口方法的问题。这种测试方法便于我们快速定位出错位置,而不需要漫长的一步步调试。在手动测试方面,还是跟前两个单元一样,构造输入的测试样例。由于这一单元实现的方法除了正常功能之外,还有异常功能,因此,在测试时,需要测试异常的情况,观察所报出的异常结果是否正确。由于第三单元开始限制程序运行时间,除了正确性测试之外,还需要压力测试。压力测试方面,采用自动化的方式,构造较长的结点序列和较多数目的指令,并输出程序运行时间,观察是否在要求的时间内。这里,由于评测机运行时间和本地运行时间不同,且本地无法测到CPU时间,只能采用估计的方法,尽可能防止超时。
- 第四单元:由于UML的测试数据可以由课程组下发的jar包导出,还是采用手动测试的方法,使用StarUML画出不同情况的UML图,并导出UML图解析得到的数据,再自行构造指令进行测试。与第三次作业相同,除正常功能测试之外,需要构造异常测试样例,观察异常输出是否正确。由于第四次作业也限制了时间,也需要相应的压力测试,尤其是第一次作业,实际CPU运行时间限制在了2s内,时间比较短,故需要构造大量UML元素和指令的测试数据检验是否会超时。
四、总结自己的课程收获
尽管这门课程主要教授面向对象方法,但是在四个单元的11次作业中,我收获了很多,主要如下,
- 代码风格有所提高。从第一次作业到最后一次作业,代码风格的检查是永不缺席的,课程组下发的checkstyle也在日常写代码的过程中,提醒我应该注意代码风格,让我养成了良好的习惯。代码风格中对于方法行数的检查,也让我意识到方法简练、功能单一的重要性,提高了我划分方法的能力,尽可能让每个方法具备单一的功能。
- 架构设计能力提高。与第一次写作业时一上来就写代码不同,在后面的作业中,我花费了较大的精力在架构设计上,虽然目前还没有达到很好的架构设计能力,但在每次作业的训练中,所设计架构的可扩展性逐渐提高。
- 编程能力提高。OO这一学期,感觉是我目前代码量最大的一个学期。每周的作业练习,进一步提高了我的代码能力和调试能力,提高了编写代码的正确性,节省了调试的时间。
- 学会了面向对象的编程方法。接触这门课之前,大多采用面向过程的编程,难以站在一个较为宏观的角度思考问题,一不小心想着想着就想到实现细节中了。经过这门课之后,我学会了用对象刻画问题,用对象之间的关系描述现实世界事物的联系。
- 逐渐养成了一套”分析需求->架构设计->细节设计->编程实现->测试"的工程模式。
- 融合多方面计算机知识。无论是第二单元的多线程,还是后两个单元的图论算法,都体现了OO这门课程不单单是一门面向对象的课程,它将之前所学的操作系统、数据结构、算法等课程结合起来,提高了大家的应用能力。
- 学习新语言,接触新工具。第三单元学习了JML语言,规范化地描述类中的方法,接触了Junit4自动化测试工具。第四单元学习了UML语言,除可以使用UML工具画类图、状态图、顺序图等之外,更加了解UML元素的层次结构。
五、立足于自己的体会给课程提三个具体改进建议
- 增加研讨课。由于高工大三没有开设研讨课,虽然在日常与同学的交流中,可以相互学习好的架构,但并不系统,也不清楚真正好架构的标准应该是什么。在研讨课上可以通过相互交流,学习好的架构设计方法和巧妙的算法,达到更好的学习效果。
- 定期发放实验课答案。虽然实验课可以提供理论课学习和课下编码的衔接桥梁,但有的题目并不能在与同学的讨论中得到统一的答案,希望能在实验课结束的一周内发放实验课的答案,让同学们可以及时纠正错误。
- CPU时间问题。由于最后两个单元都涉及对实际CPU运行时间的限制,然而本地测试的运行时间与评测机的运行时间并不相同,希望课程组能开设CPU运行时间的测试平台,让同学们课下可以测试自己程序的运行时间。