一、分类损失
1、交叉熵损失函数
公式:
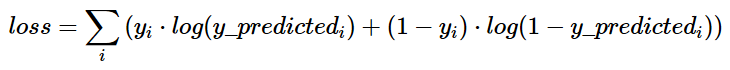
交叉熵的原理
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则:

有这样一个定理:当p=q时,交叉熵去的最小值.因此可以利用交叉熵比较一个分布与另一个分布的吻合情况.交叉熵越接近与熵,q便是针对p更好的逼近,实际上,模型的输出与期望输出越接近,交叉熵也会越小,这正是损失函数所需要的.
在对熵进行最小化时,将log2替换为log完全没有任何问题,因为两者只相差一个常系数.
在TensorFlow中实现交叉熵
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
其中y_表示期望的输出,y表示实际的输出(概率值),*为矩阵元素间相乘,而不是矩阵乘。
上述代码实现了第一种形式的交叉熵计算,需要说明的是,计算的过程其实和上面提到的公式有些区别,按照上面的步骤,平均交叉熵应该是先计算batch中每一个样本的交叉熵后取平均计算得到的,而利用tf.reduce_mean函数其实计算的是整个矩阵的平均值,这样做的结果会有差异,但是并不改变实际意义。
除了tf.reduce_mean函数,tf.clip_by_value函数是为了限制输出的大小,为了避免log0为负无穷的情况,将输出的值限定在(1e-10, 1.0)之间,其实1.0的限制是没有意义的,因为概率怎么会超过1呢。
由于在神经网络中,交叉熵常常与Sorfmax函数组合使用,所以TensorFlow对其进行了封装,即:
cross_entropy = tf.nn.sorfmax_cross_entropy_with_logits(y_ ,y)
2、sigmoid_cross_entropy_with_logits
函数定义
def sigmoid_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None):
函数意义
这个函数的作用是计算经sigmoid 函数激活之后的交叉熵。
为了描述简洁,我们规定 x = logits,z = targets,那么 Logistic 损失值为:
x−x∗z+log(1+exp(−x))
对于x<0的情况,为了执行的稳定,使用计算式:
−x∗z+log(1+exp(x))−x∗z+log(1+exp(x))
为了确保计算稳定,避免溢出,真实的计算实现如下:
max(x,0)−x∗z+log(1+exp(−abs(x)))max(x,0)−x∗z+log(1+exp(−abs(x)))
logits 和 targets 必须有相同的数据类型和数据维度。
它适用于每个类别相互独立但互不排斥的情况,在一张图片中,同时包含多个分类目标(大象和狗),那么就可以使用这个函数。
输入
_sentinel: 一般情况下不怎么使用的参数,可以直接保持默认使其为None
logits: 一个Tensor。数据类型是以下之一:float32或者float64。
targets: 一个Tensor。数据类型和数据维度都和 logits 相同。
name: 为这个操作取个名字。
输出
一个 Tensor ,数据维度和 logits 相同。
3、weighted_cross_entropy_with_logits
weighted_cross_entropy_with_logits(targets, logits, pos_weight, name=None):
此函数功能以及计算方式基本与tf_nn_sigmoid_cross_entropy_with_logits差不多,但是加上了权重的功能,是计算具有权重的sigmoid交叉熵函数
计算方法:
pos_weight∗targets∗−log(sigmoid(logits))+(1−targets)∗−log(1−sigmoid(logits))
参数:
_sentinel:本质上是不用的参数,不用填
targets:一个和logits具有相同的数据类型(type)和尺寸形状(shape)的张量(tensor)
shape:[batch_size,num_classes],单样本是[num_classes]
logits:一个数据类型(type)是float32或float64的张量
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
4、softmax_cross_entropy_with_logits
def softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
解释
这个函数的作用是计算 logits 经 softmax 函数激活之后的交叉熵。
对于每个独立的分类任务,这个函数是去度量概率误差。比如,在 CIFAR-10 数据集上面,每张图片只有唯一一个分类标签:一张图可能是一只狗或者一辆卡车,
但绝对不可能两者都在一张图中。(这也是和 tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None)这个API的区别)
说明
- 输入API的数据 logits 不能进行缩放,因为在这个API的执行中会进行 softmax 计算,如果 logits 进行了缩放,那么会影响计算正确率。
- 不要调用这个API去计算 softmax 的值,因为这个API最终输出的结果并不是经过 softmax 函数的值。
- logits 和 labels 必须有相同的数据维度 [batch_size, num_classes],和相同的数据类型 float32 或者 float64 。
- 它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象.
参数
输入参数
_sentinel: 这个参数一般情况不使用,直接设置为None就好 logits: 一个没有缩放的对数张量。labels和logits具有相同的数据类型(type)和尺寸(shape) labels: 每一行 labels[i] 必须是一个有效的概率分布值。 name: 为这个操作取个名字。
输出参数
一个 Tensor ,数据维度是一维的,长度是 batch_size,数据类型都和 logits 相同。
5、sparse_softmax_cross_entropy_with_logits
定义
sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None):
说明
此函数大致与tf_nn_softmax_cross_entropy_with_logits的计算方式相同,
适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
但是在对于labels的处理上有不同之处,labels从shape来说此函数要求shape为[batch_size],
labels[i]是[0,num_classes)的一个索引, type为int32或int64,即labels限定了是一个一阶tensor,
并且取值范围只能在分类数之内,表示一个对象只能属于一个类别
参数
_sentinel:本质上是不用的参数,不用填
logits:shape为[batch_size,num_classes],type为float32或float64
name:操作的名字,可填可不填