原博客地址:
https://www.cnblogs.com/brucemengbm/p/6875340.html
五大经常使用算法 之 动态规划法
一、基本概念
动态规划过程是:每次决策依赖于当前状态。又随即引起状态的转移。
一个决策序列就是在变化的状态中产生出来的,所以,这样的多阶段最优化决策解决这个问题的过程就称为动态规划。
动态规划是运筹学中用于求解决策过程中的最优化数学方法。
当然。我们在这里关注的是作为一种算法设计技术,作为一种使用多阶段决策过程最优的通用方法。
它是应用数学中用于解决某类最优化问题的重要工具。
假设问题是由交叠的子问题所构成,我们就能够用动态规划技术来解决它。一般来说,这种子问题出如今对给定问题求解的递推关系中,这个递推关系包括了同样问题的更小子问题的解。动态规划法建议,与其对交叠子问题一次重新的求解,不如把每一个较小子问题仅仅求解一次并把结果记录在表中(动态规划也是空间换时间的)。这样就能够从表中得到原始问题的解。
动态规划经常常使用于解决最优化问题,这些问题多表现为多阶段决策。
关于多阶段决策:
在实际中,人们经常遇到这样一类决策问题:即因为过程的特殊性,能够将决策的全过程根据时间或空间划分若干个联系的阶段。
而在各阶段中。人们都须要作出方案的选择。我们称之为决策。而且当一个阶段的决策之后,经常影响到下一个阶段的决策,从而影响整个过程的活动。这样,各个阶段所确定的决策就构成一个决策序列,常称之为策略。
因为各个阶段可供选择的决策往往不止一个。因而就可能有很多决策以供选择,这些 可供选择的策略构成一个集合,我们称之为同意策略集合(简称策略集合)。每一个策略都对应地确定一种活动的效果。我们假定这个效果能够用数量来衡量。
因为不同的策略经常导致不同的效果,因此,怎样在同意策略集合中选择一个策略,使其在预定的标准下达到最好的效果。经常是人们所关心的问题。我们称这种策略为最优策略,这类问题就称为多阶段决策问题。
多阶段决策问题举例:机器负荷分配问题
某种机器能够在高低两种不同的负荷下进行生产。在高负荷下生产时。产品的年产量g和投入生产的机器数量x的关系为g=g(x),这时的年完善率为a,即假设年初完善机器数为x,到年终时完善的机器数为a*x(0<a<1);在低负荷下生产时,产品的年产量h和投入生产的机器数量y的关系为h=h(y)。对应的完善率为b(0<b<0)。且a<b。
假定開始生产时完善的机器熟练度为s1。
要制定一个五年计划,确定每年投入高、低两种负荷生产的完善机器数量,使5年内产品的总产量达到最大。
这是一个多阶段决策问题。
显然能够将全过程划分为5个阶段(一年一个阶段),每一个阶段開始时要确定投入高、低两种负荷下生产的完善机器数,并且上一个阶段的决策必定影响到下一个阶段的生产状态。决策的目标是使产品的总产量达到最大。这个问题常常使用数学方法建模,结合线性规划等知识来进行解决。
二、基本思想与策略
基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了实用的信息。
在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其它局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
因为动态规划解决的问题多数有重叠子问题这个特点。为降低反复计算。对每个子问题仅仅解一次,将其不同阶段的不同状态保存在一个二维数组中。
与分治法最大的区别是:适合于用动态规划法求解的问题,经分解后得到的子问题往往不是互相独立的(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)。
三、适用的情况
能採用动态规划求解的问题的一般要具有3个性质:
(1)、最优化原理:假设问题的最优解所包括的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
(2)、无后效性:即某阶段状态一旦确定。就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响曾经的状态。仅仅与当前状态有关;
(3)、有重叠子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到(该性质并非动态规划适用的必要条件,可是假设没有这条性质。动态规划算法同其它算法相比就不具备优势)。
四、求解的基本步骤
动态规划所处理的问题是一个多阶段决策问题。一般由初始状态開始。通过对中间阶段决策的选择,达到结束状态。这些决策形成了一个决策序列。同一时候确定了完毕整个过程的一条活动路线(一般是求最优的活动路线)。动态规划的设计都有着一定的模式。一般要经历下面几个步骤。
初始状态→│决策1│→│决策2│→…→│决策n│→结束状态
(1)划分阶段:依照问题的时间或空间特征。把问题分为若干个阶段。在划分阶段时。注意划分后的阶段一定要是有序的或者是可排序的。否则问题就无法求解。
(2)确定状态和状态变量:将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。
当然,状态的选择要满足无后效性。
(3)确定决策并写出状态转移方程:由于决策和状态转移有着天然的联系,状态转移就是依据上一阶段的状态和决策来导出本阶段的状态。所以假设确定了决策。状态转移方程也就可写出。但其实经常是反过来做。依据相邻两个阶段的状态之间的关系来确定决策方法和状态转移方程。
(4)寻找边界条件:给出的状态转移方程是一个递推式。须要一个递推的终止条件或边界条件。
一般,仅仅要解决这个问题的阶段、状态和状态转移决策确定了。就能够写出状态转移方程(包含边界条件)。
实际应用中能够按下面几个简化的步骤进行设计:
(1)分析最优解的性质。并刻画其结构特征。
(2)递归的定义最优解。
(3)以自底向上或自顶向下的记忆化方式(备忘录法)计算出最优值。
(4)依据计算最优值时得到的信息,构造问题的最优解。
五、算法实现的说明
动态规划的主要难点在于理论上的设计,也就是上面4个步骤的确定,一旦设计完毕。实现部分就会很easy。
使用动态规划求解问题,最重要的就是确定动态规划三要素:问题的阶段、每一个阶段的状态、从前一个阶段转化到后一个阶段之间的递推关系。
递推关系必须是从次小的问题開始到较大的问题之间的转化,从这个角度来说,动态规划往往能够用递归程序来实现,只是由于递推能够充分利用前面保存的子问题的解来降低反复计算,所以对于大规模问题来说。有递归不可比拟的优势。这也是动态规划算法的核心之处。
确定了动态规划的这三要素,整个求解过程就能够用一个最优决策表来描写叙述,最优决策表是一个二维表,当中行表示决策的阶段,列表示问题状态。表格须要填写的数据一般相应此问题的在某个阶段某个状态下的最优值(如最短路径。最长公共子序列,最大价值等),填表的过程就是依据递推关系,从1行1列開始,以行或者列优先的顺序,依次填写表格。最后依据整个表格的数据通过简单的取舍或者运算求得问题的最优解。
六、动态规划——几个典型案例
1、计算二项式系数
问题描写叙述:
计算二项式系数
问题解析:
在排列组合中,我们有下面公式:
当n>k>0时。C(n,k) = C(n-1,k-1) + C(n-1,k)
这个式子将C(n,k)的计算问题简化为(问题描写叙述)C(n-1,k-1)和C(n-1,k)两个较小的交叠子问题。
初始条件:C(n,n) = C(n,0) = 0;
我们能够用填矩阵的方式求解C(n,k):
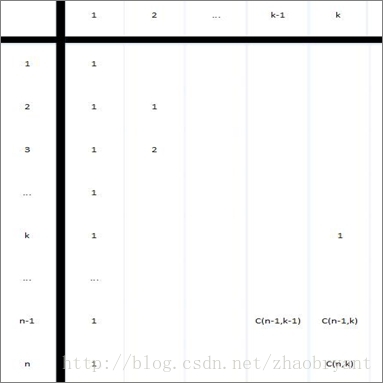
上图即为二项式系数矩阵表。
那么。我们要计算出任一C(n,k)。我们能够尝试求出全部的二项式系数表格。然后通过查表来进行计算操作。
这里,我们的构建二项式系数表的函数为(填矩阵):
int BinoCoef(int n, int k);
函数及详细程序实现例如以下:
#include <stdio.h>
#define MAX 100
int BinoCoef(int n, int k);
int main(){
int n,k,result;
printf("Please input n and k:
");
scanf("%d %d",&n,&k);
result = BinoCoef(n,k);
printf("The corrsponding coefficent is %d !
",result);
return 0;
}
int BinoCoef(int n, int k){
int data[MAX][MAX];
int i,j;
for(i=0;i<=n;i++)
{
for(j=0;j<=((i<k)?<p></p><p>i:k);j++)
{
if(i == 0||i == j)
data[i][j] = 1;
else
data[i][j] = data[i-1][j] + data[i-1][j-1];
}
}
return data[n][k];
} 这里,我们要注意动态规划时的这样几个关键点:
(1)、怎么描写叙述问题。要把问题描写叙述为交叠的子问题;
(2)、交叠子问题的初始条件(边界条件);
(3)、动态规划在形式上往往表现为填矩阵的形式;
(4)、递推式的依赖形式决定了填矩阵的顺序。
2、三角数塔问题:
问题描写叙述:
设有一个三角形的数塔。顶点为根结点。每一个结点有一个整数值。从顶点出发,能够向左走或向右走,要求从根结点開始,请找出一条路径,使路径之和最大。仅仅要输出路径的和。如图所看到的:
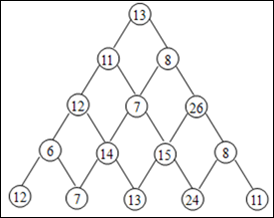
当然,正确路径为13-8-26-15-24(和为86)。
问题解析:
如今,怎样求出该路径?
首先,我们用数组保存三角形数塔,并设置距离矩阵d[i][j],用于保存节点(i,j)到最底层的最长距离,从而,d[1][1]即为根节点到最底层的最大路径的距离。
|
行/列 |
1 |
2 |
3 |
4 |
5 |
|
1 |
13 |
|
|
|
|
|
2 |
11 |
8 |
|
|
|
|
3 |
12 |
7 |
26 |
|
|
|
4 |
6 |
14 |
15 |
8 |
|
|
5 |
12 |
7 |
13 |
24 |
11 |
方法一:递推方式
相应函数:void fnRecursive(int,int);
对于递推方式。其基本思想是基于指定位置。逐层求解:
举例:找寻从点(1,1)開始逐层向下的路径的最长距离。
思想:自底向上的逐步求解(原因在于,这是一个三角形的矩阵形式,向上收缩,便于求解)。
首先。在最底层,d[n][j]=a[n][j](将最底层的节点到最底层的最长路径距离设置为节点值)。
然后。逐层向上进行路径距离处理,这里须要注意距离处理公式:
d[i-1][j] = min{ (d[i][j] + a[i-1][j]), (d[i][j+1] + a[i-1][j]) }
最后,递推处理路径距离至根节点就可以,这样就建立了一个完整的路径最长距离矩阵,用来保存三角数塔节点到最底层的最长路径距离。
方法二:记忆化搜索方式
相应函数:int fnMemorySearch(int i,int j);
记忆化搜索方式的核心在于保存前面已经求出的距离值,然后依据这些距离值能够求出后面所需求解的距离值。
该函数的返回值即为节点(i,j)到最底层的最长路径距离值。
这里,我们能够去考究这样几个问题:
(1)在什么时候结束?
(2)有何限制条件和一般情况处理?
问题1解析:
当d[i][j]>0时,则说明节点(i,j)到最底层的最长路径距离已经存在,因此直接返回该值就可以。
问题2解析:
限制条件:当节点(i,j)位于最底层时,即i==n时,这时d[i][j]应该初始化为a[i][j];
一般情况处理:即节点(i,j)的赋值问题。
这里有两种情况:
第一种情况,节点(i,j)相应的最长路径的下一层节点为左边节点:
此时,d[i][j] = a[i][j] + fnMemorySearch(i+1,j);
另外一种情况,节点(i,j)相应的最长路径的下一层节点为右边节点:
此时,d[i][j] = a[i][j] + fnMemorySearch(i+1,j+1);
代码实现:
#include <stdio.h>
#include <stdlib.h>
#define MAXN 101
int n,d[MAXN][MAXN];
int a[MAXN][MAXN];
void fnRecursive(int,int);
//递推方法函数声明
int fnMemorySearch(int,int);
//记忆化搜索函数声明
int main()
{
int i,j;
printf("输入三角形的行数n(n=1-100):
");
scanf("%d",&n);
printf("按行输入数字三角形上的数(1-100):
");
for(i=1; i<=n; i++)
for(j=1; j<=i; j++)
scanf("%d",&a[i][j]);
for(i=1; i<=n; i++)
for(j=1; j<=i; j++)
d[i][j]=-1;//初始化指标数组
printf("递推方法:1
记忆化搜索方法:2
");
int select;
scanf("%d",&select);
if(select==1)
{
fnRecursive(i,j);//调用递推方法
printf("
%d
",d[1][1]);
}
else if(select==2)
{
printf("
%d
",fnMemorySearch(1,1));//调用记忆化搜索方法
}
else
printf("输入错误!");
return 0;
}
void fnRecursive(int i,int j)
//递推方法实现过程
{
for(j=1; j<=n; j++)
d[n][j]=a[n][j];
for(i=n-1; i>=1; i--)
for(j=1; j<=i; j++)
d[i][j]=a[i][j]+(d[i+1][j]>d[i+1][j+1]?d[i+1][j]:d[i+1][j+1]);
}
int fnMemorySearch(int i,int j)
//记忆化搜索实现过程
{
if(d[i][j]>=0) return d[i][j];
if(i==n) return(d[i][j]=a[i][j]);
if(fnMemorySearch(i+1,j)>fnMemorySearch(i+1,j+1))
return(d[i][j]=(a[i][j]+fnMemorySearch(i+1,j)));
else
return(d[i][j]=(a[i][j]+fnMemorySearch(i+1,j+1)));
}3、硬币问题
问题描写叙述:
有n种硬币,面值分别为V1,V2,…,Vn元,每种有无限多。
给定非负整数S。能够选用多少硬币,使得面值之和恰好为S元,输出硬币数目的最小值和最大值。(1<=n<=100,0<=S<=10000,1<=Vi<=S)
问题解析:
首先证明该问题问题具有最优子结构。如果组合成S元钱有最优解。并且最优解中使用了面值Vi的硬币。同一时候最优解使用了k个硬币。那么,这个最优解包括了对于组合成S-Vi元钱的最优解。
显然,S-Vi元钱的硬币中使用了k-1个硬币。如果S-Vi元钱另一个解使用了比k-1少的硬币。那么使用这个解能够为找S元钱产生小于k个硬币的解。
与如果矛盾。
另外。对于有些情况下,贪心算法可能无法产生最优解。
比方硬币面值分别为1、10、25。
组成30元钱。最优解是3*10,而贪心的情况下产生的解是1*5+25。
对于贪心算法,有一个结论:如果可换的硬币单位是c的幂。也就是c^0、c^1、…、 c^k,当中整数c>1,k>=1。在这样的情况下贪心算法能够产生最优解。
上面已经证明该问题具有最优子结构,因此能够用动态规划求解该硬币问题。
====>>>:
设min[j]为组合成j元钱所需的最少的硬币数。max[j]为组合成j元钱所需的最多的硬币数。
从而有,对于最小组合过程。我们尽可能使用大面值的硬币(不是必定,否则成为贪心算法)。其满足以下的递推公式:
当j=0时,min[0] = 0。//即组合成0元钱的所需硬币数为0。显而易见。
当j>0时,假设j > Vk且min[j] < 1 + min[j-Vk]。则有min[j] = 1 + min[j-Vk]。对于这一步。其思想是尽可能通过大面值硬币来降低所需硬币数。
而对于最大组合过程。我们则是尽量使用小面值的硬币(此过程。同贪心算法一样)。其满足以下的递推公式:
当j = 0时,max[0] = 0。//显而易见。
当j > 0时。假设j > Vk且max[j] > 1 + max[j - Vk],则有max[j] = 1 + max[j-Vk];
如此,我们对整个面值构成过程进行了简单的处理,得到了不同面值和情况下所需的硬币数。
如今,举例来说明此过程:
就上面所提及的用1、10、25面值硬币来组成30元钱的过程,我们进行相关说明:
首先,min[0] = max[0] = 0。同一时候初始化min[i] = INF,max[i] = -INF,i!=0。
然后。我们依据上面的两个递推公式。能够得到min[]和max[]的终于数据。
其数据终于为:
min[] = {0,1,2,3,4,5,6,7,8,9,1,2,3,4,5,6,7,8,9,2,3,4,5,6,1,2,3,4,5,3};
max[] = {0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,…,28,19,30};
于是依据min[]和max[],我们便能够得到所需硬币数。并通过print_ans函数打印详细组合。
代码实现:
#include <stdio.h>
#include <stdlib.h>
#define INF 100000000
#define MAXNUM 10000
#define MONEYKIND 100
int n,S;
int V[MONEYKIND];
int min[MAXNUM],max[MAXNUM];
void dp(int*,int*);
//递推方法函数声明
void print_ans(int*,int);
//输出函数声明
int main()
{
int i;
printf("输入硬币的种数n(1-100):
");
scanf("%d",&n);
printf("输入要组合的钱数S(0-10000):
");
scanf("%d",&S);
printf("输入硬币种类:
");
for(i=1; i<=n; i++)
{
scanf("%d",&V[i]);
}
dp(min,max);
printf("最小组合方案:
");
print_ans(min,S);
printf("
");
printf("最大组合方案:
");
print_ans(max,S);
return 0;
}
void dp(int *min,int *max)
//递推过程实现
{
int i,j;
min[0] = max[0] = 0;
for(i=1; i<=S; i++)//初始化数组
{
min[i]=INF;
max[i]=-INF;
}
for(i=1; i<=S; i++)
for(j=1; j<=n; j++)
if(i>=V[j])
{
if(min[i-V[j]]+1<min[i]){
min[i]=min[i-V[j]]+1;//最小组合过程
//printf("%d
",min[i]);
}
if(max[i-V[j]]+1>max[i])
max[i]=max[i-V[j]]+1;//最大组合过程
}
}
void print_ans(int *d,int S)
//输出函数实现
{
int i;
for(i=1; i<=n; i++)
if(S>=V[i]&&d[S]==d[S-V[i]]+1)
{
printf("%d ",V[i]);
print_ans(d,S-V[i]);
break;
}
}
对于上面的代码,还须要说明的是print_ans函数的实现过程:
递归地打印出组合中的硬币(面值由小到大),每次递归时降低已打印出的硬币面值。
讨论:
贪心算法的适用性(仅指最小组合):
对于贪心算法,有一个结论:如果可换的硬币单位是c的幂。也就是c^0、c^1、…、 c^k,当中整数c>1,k>=1。在这样的情况下贪心算法能够产生最优解。
贪心算法的过程:对硬币面值进行升序排序。先取最大面值(排序序列最后一个元素)进行极大匹配(除法),然后对余数进行类上操作。
因此,在这里。注意贪心算法与动态规划的差别:
动态规划和贪心算法都是一种递推算法;
均由局部最优解来推导全局最优解。
不同点:
贪心算法:
(1)、贪心算法中。作出的每步贪心决策都无法改变,由于贪心策略是由上一步的最优解推导下一步的最优解,而上一部之前的最优解则不作保留。
(2)、由(1)中的介绍,能够知道贪心法正确的条件是:每一步的最优解一定包括上一步的最优解
动态规划算法:
(1)、全局最优解中一定包括某个局部最优解,但不一定包括前一个局部最优解,因此须要记录之前的全部最优解;
(2)、动态规划的关键是状态转移方程。即怎样由以求出的局部最优解来推导全局最优解。
(3)、边界条件:即最简单的,能够直接得出的局部最优解。