源代码github地址
https://github.com/sunxiangguo/2CLSTM
但是没有开放数据集, 所以需要自己填数据集
摘要
这篇文章说他们认为文本的结构也是一个包含人物性格的重要特征,所以他们使用了一个名叫2CLSTM的模型,由一个双向的LSTM(Long Short Term Memory networks)和一个CNN(卷积神经网络)组成,用于侦测人物性格。同时提出**Latent Sentence Group(LSG)**这个概念来表示一组在某些方面连接很紧密的句向量。最后用这个LSG来分类得到5大性格的true和false。
2CLSTM 过程
2CLSTM包括4个部分, 词嵌入, 2LSTM处理句向量,得到关于上下文的语义信息, CNN学习LSG特征, Softmax分类, 这也就是为什么这个总的模型叫做2CLSTM。
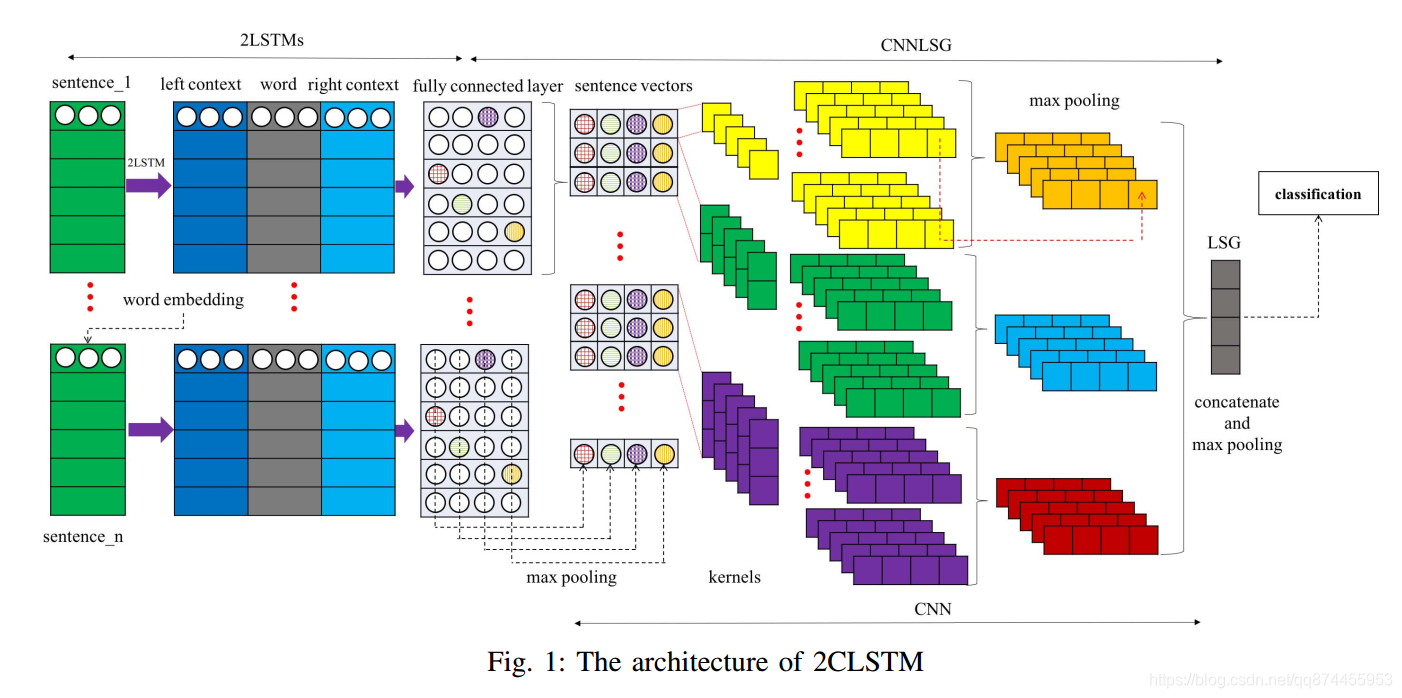
1. 词嵌入
词嵌入说白了就是把单词变成一个向量,或者说把词空间映射成一个连续的向量空间,这里提前使用了GloVe 的已经训练好的词矩阵得到词向量,把单词变为一个100维的向量, 论文里建议最好从数据集里训练出词向量。
2. 2LSTM处理
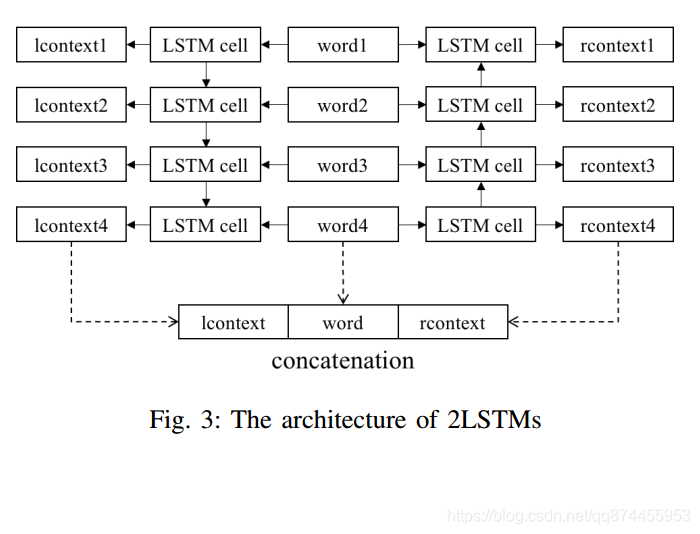
论文介绍了LSTM, 这里不做过多介绍,关键的一点就是作者通过对词 分别输入到两个LSTM得到词左边和词右边的上下文
此图可以说明
3. CNN学习LSGCNN学习LSG
Sentence Group表示在逻辑和语义结构上紧密相连的几个连续句子,如坐标关系,偏好关系,因果关系等。但是,探测这些具体关系对于大多数文本任务来说是不切实际的。实际运用上,我们经常专注于探测某些维度中句子向量之间的关系。这也就是为什么我们使用Latent 这个词。
所以我们得到LSG 的定义
Latent Sentence Group (LSG) is defined as a synthesis that consists of a number of sentence vectors which are closely connected in some coordinates.
LSG( Latent Sentence Group)定义为一组在某些方面连接很紧密的句向量。
具体我们使用CNN来学习到LSG特征, 每个word通过Fully connected layer ,得到句子向量。 然后在每个维度中,我们使用1,2,3-gram 内核来学习每个坐标中的LSG特征。 通过 dense layer和max pooling layer ,最终得到LSG。
4. Softmax分类
把得到的LSG用Softmax来进行分类
使用此公式计算概率
