【场景】客户端大量连接,如果采用多线程方式的话,线程上下文切换导致性能不佳。因此采用io多路复用。
一、上下文切换
对于单核CPU来说(对于多核CPU,此处就理解为一个核),CPU在一个时刻只能运行一个线程,当在运行一个线程的过程中转去运行另外一个线程,这个叫做线程上下文切换(对于进程也是类似)。
由于可能当前线程的任务并没有执行完毕,所以在切换时需要保存线程的运行状态,以便下次重新切换回来时能够继续切换之前的状态运行。举个简单的例子:比如一个线程A正在读取一个文件的内容,正读到文件的一半,此时需要暂停线程A,转去执行线程B,当再次切换回来执行线程A的时候,我们不希望线程A又从文件的开头来读取。
因此需要记录线程A的运行状态,那么会记录哪些数据呢?因为下次恢复时需要知道在这之前当前线程已经执行到哪条指令了,所以需要记录程序计数器的值,另外比如说线程正在进行某个计算的时候被挂起了,那么下次继续执行的时候需要知道之前挂起时变量的值时多少,因此需要记录CPU寄存器的状态。所以一般来说,线程上下文切换过程中会记录程序计数器、CPU寄存器状态等数据。
说简单点的:对于线程的上下文切换实际上就是 存储和恢复CPU状态的过程,它使得线程执行能够从中断点恢复执行。
虽然多线程可以使得任务执行的效率得到提升,但是由于在线程切换时同样会带来一定的开销代价,并且多个线程会导致系统资源占用的增加,所以在进行多线程编程时要注意这些因素。
文件描述符:内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。
打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
——百度百科
二、select:
监听文件描述符的数据结构,当有数据时,轮询遍历整个数据结构找到有数据的文件描述符进行读取操作
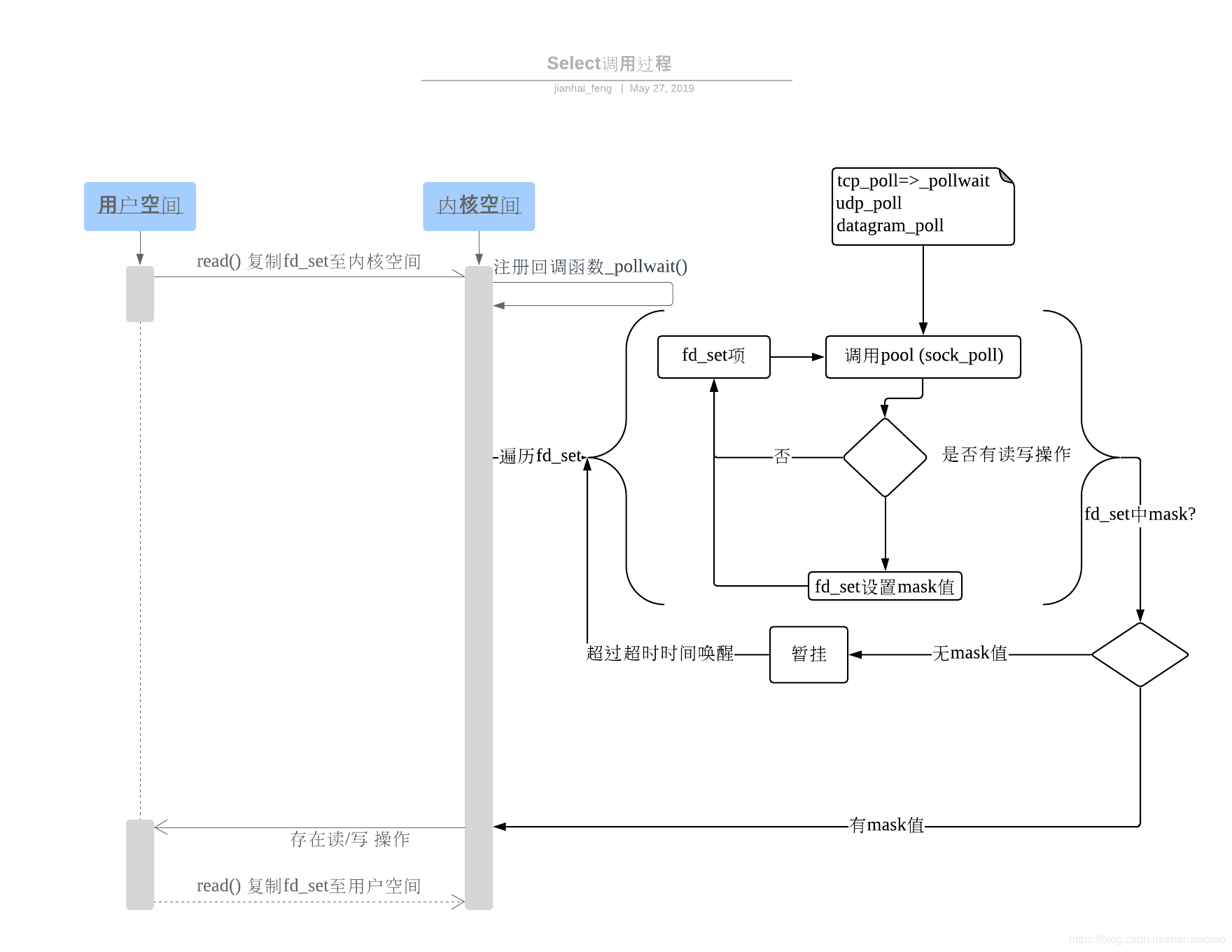
优点:将fd复制到内核态操作效率提高
缺点:
- 单个进程可监视的fd数量被限制,即能监听端口的大小有限(bigmap)。32位机默认是1024个。64位机默认是2048.
- 复制fd到内核态任然需要很大开销
- 每次文件描述符有数据时,不知道是哪个或者哪几个,需要遍历整个数据结构,即O(n)
三、poll
和select差不多,但是采用链表存储文件描述符,没有大小限制
优点:大小没有限制、pollfds数据结构可重用(进行读取操作之前short revents恢复为0)
缺点:复制到内核态需要开销;需要轮询遍历操作O(n);
四、epoll
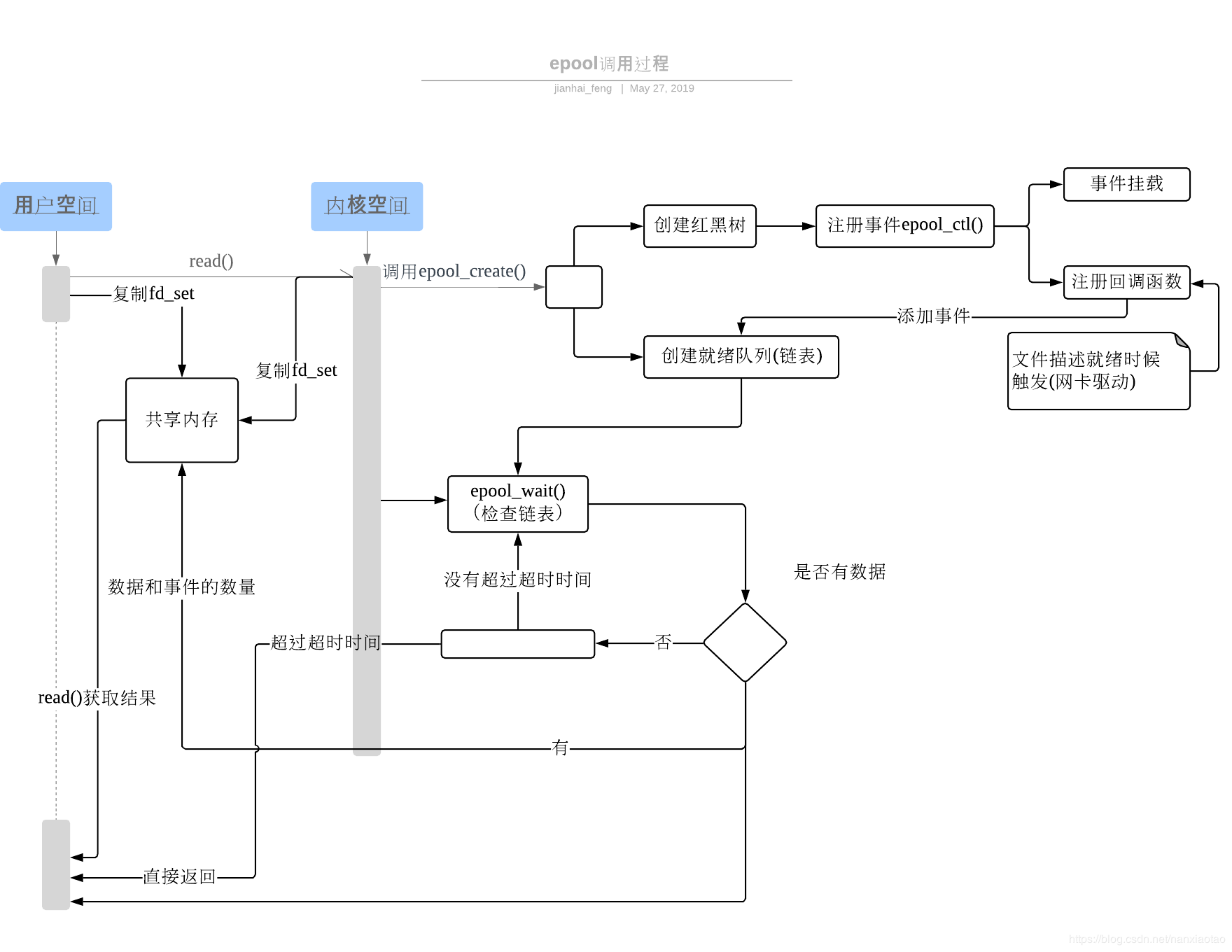
当有数据来时,将有数据的fd排到前面,epoll_wait方法返回有数据的fd个数,然后遍历这几个有数据的fd - O(1))
内核态和用户态共享文件描述符的存储结构,不用再复制。并且时间复杂度为O(1).
【epoll的工作方式】
epoll的两种工作方式:1.水平触发(LT)2.边缘触发(ET)
LT模式:若就绪的事件一次没有处理完要做的事件,就会一直去处理。即就会将没有处理完的事件继续放回到就绪队列之中(即那个内核中的链表),一直进行处理。
ET模式:就绪的事件只能处理一次,若没有处理完会在下次的其它事件就绪时再进行处理。而若以后再也没有就绪的事件,那么剩余的那部分数据也会随之而丢失。
由此可见:ET模式的效率比LT模式的效率要高很多。只是如果使用ET模式,就要保证每次进行数据处理时,要将其处理完,不能造成数据丢失,这样对编写代码的人要求就比较高。
注意:ET模式只支持非阻塞的读写:为了保证数据的完整性。