预处理
直接从文件生成图片数据
ImageDataGenerator,循环生成图片,在重复生成图片之前,会把所有图片都遍历一遍。而且如果图片总量不是生成批量的倍数的话,在生成重复图片的前一次的批量是不完整的。具体代码:
import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt datagen = ImageDataGenerator( #定义生成图片的模式,添加各种变换等,都是在范围内随机 rotation_range=40, #图片旋转的范围 width_shift_range=0.2, #图片水平位移的范围 height_shift_range=0.2, #图片垂直位移的范围 shear_range=0.2, #图片变倾斜的角度 zoom_range=0.2, #图片缩放的范围 horizontal_flip=True, #50%几率水平镜像 fill_mode='nearest') gener = datagen.flow_from_directory( #图片数据生成器 'D:/Datasets/dogs-vs-cats/train/test', #生成路径。这个文件夹中应该包括各个类别的图片,且每类图片保存在单独的文件夹中 target_size = (150,150), #生成图片的尺寸 batch_size=1, #每次生成多少图片数据 class_mode='binary') #生成图片的标签格式,这里只有两类,所以为二元标签,一个标量0或1 for i,j in gener:#生成的是:图片,标签 i/=255. print(j) plt.imshow(i[0]) plt.show()
序列长度统一化
pad_sequences,将array中长度不一的list类型的序列转换为长度相同的array。代码示例:
from tensorflow.keras.datasets import imdb from tensorflow.keras.preprocessing.sequence import pad_sequences max_feature = 10000 max_len = 500 (data_train,y_train),(data_test,y_test) = imdb.load_data(num_words=max_feature) x_train = pad_sequences(data_train,maxlen=max_len) x_test = pad_sequences(data_test,maxlen=max_len)
自定义数据生成器
A detailed example of data generators with Keras
使用数据生成器(data generators)解决训练数据内存问题
可视化
CNN显示层输出
from keras import models
使用
activation_model = models.Model( inputs = model.input, outputs = model_outputs)
来对原模型生成模型,生成的模型预测样本时能输出原模型对应层的计算结果。model.input是原模型model的输入层,model_outputs是这个模型的某些层,可以使用如:
model_outputs = [l.output for l in model.layers] #返回了原模型的所有层的输出
来定义。然后
activation = activation_model.predict(a_input)
获取某个输入的对应各个层的输出。
CNN显示层过滤器的效果
查看过滤器训练完成后产生的效果,可以使用该层输出的均值关于输入的梯度来梯度下降,迭代输入的随机图片,使这个均值极小化,然后迭代完成后的图片就是过滤器的效果。具体代码:
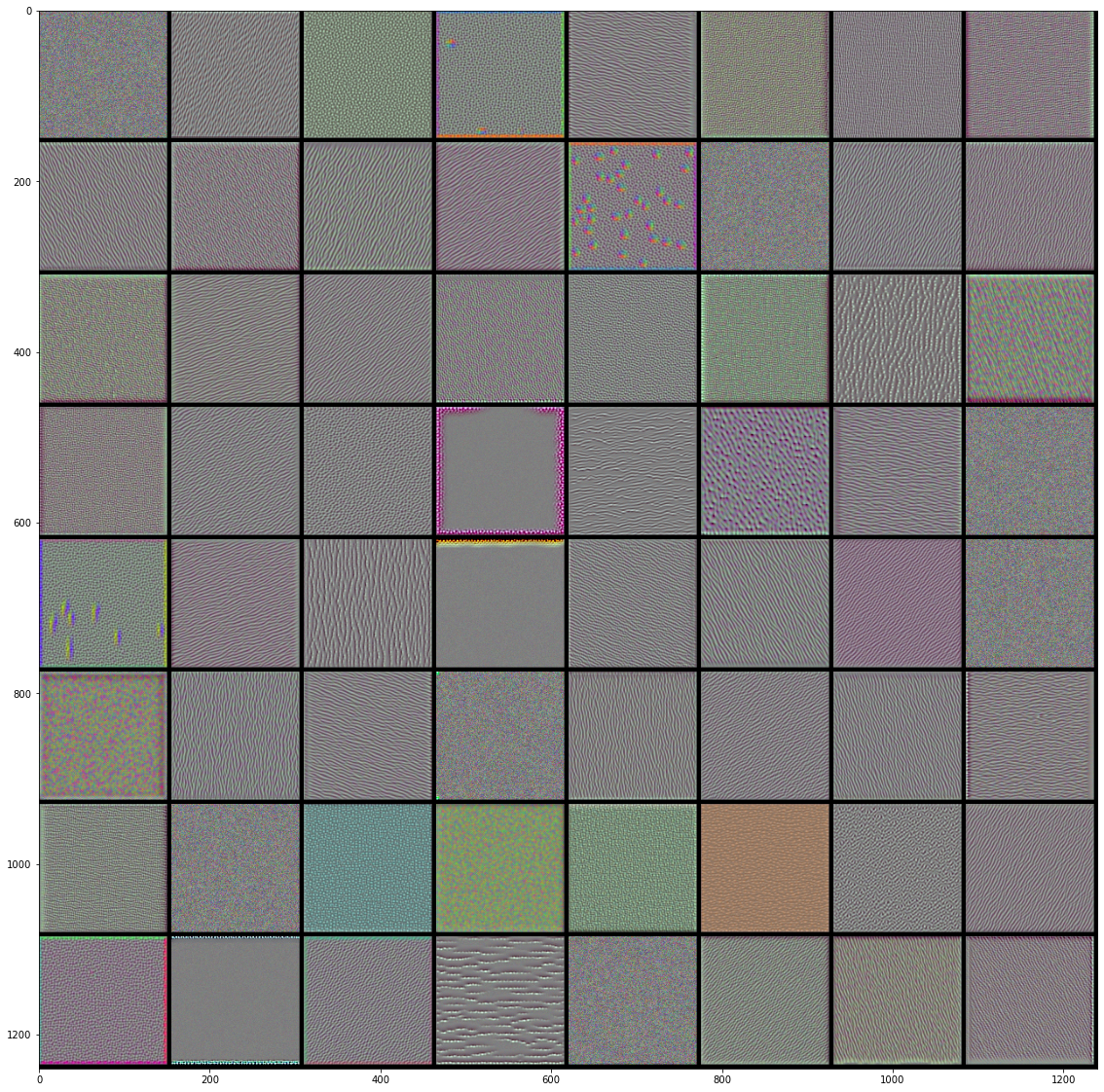
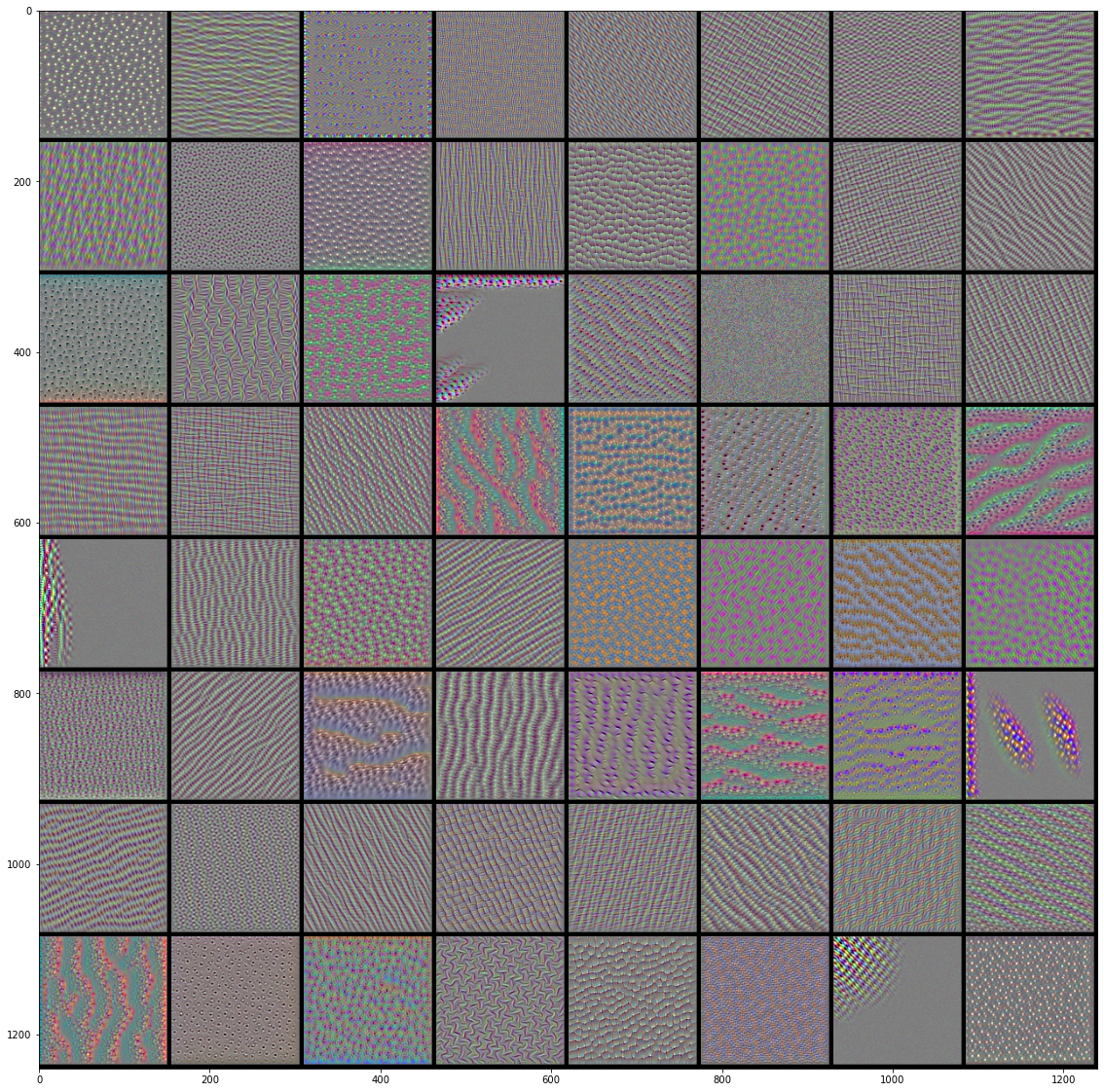
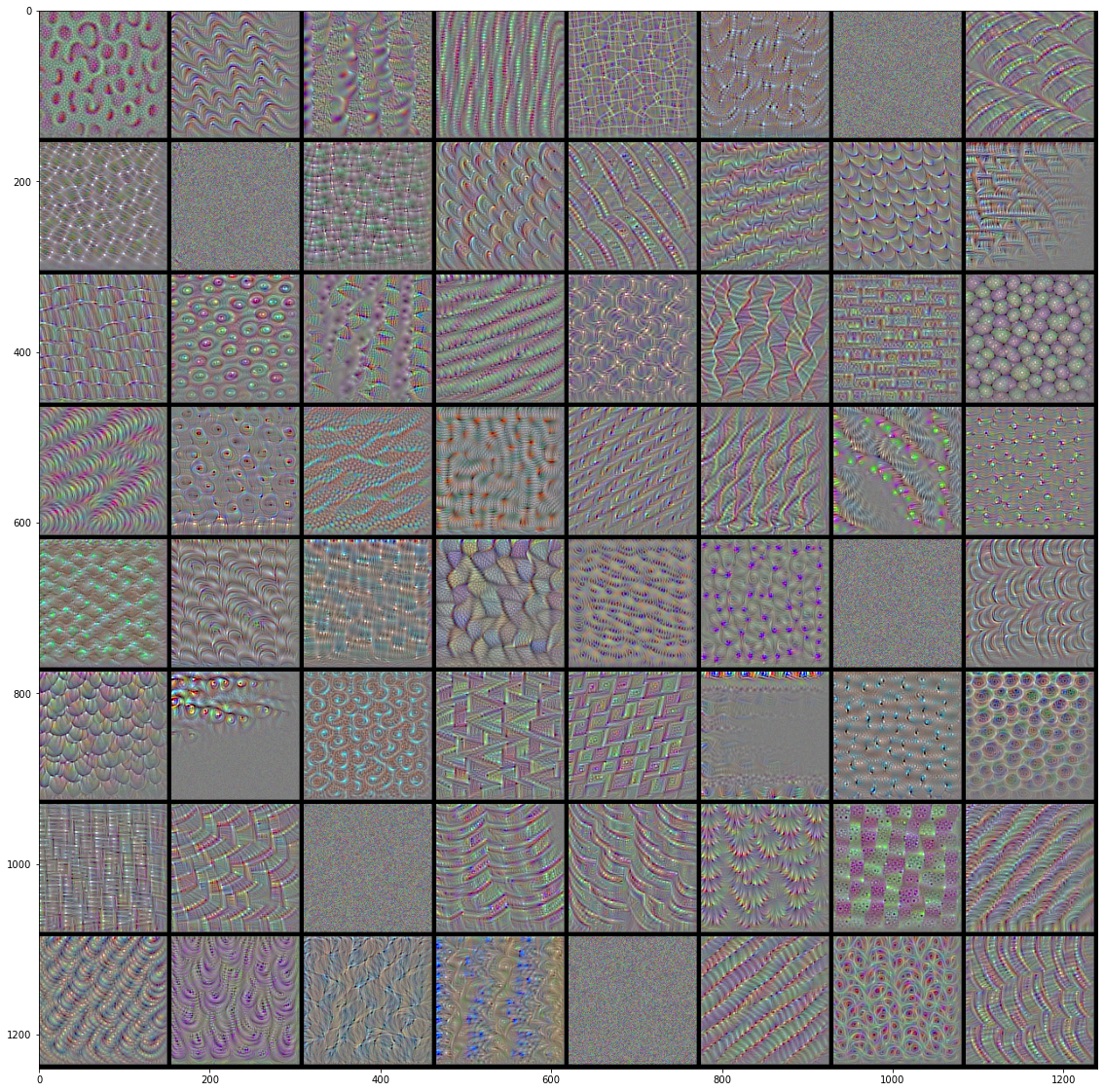
#%% import tensorflow as tf import keras import matplotlib.pyplot as plt import numpy as np from tensorflow.keras.models import load_model from keras import backend as K #%%绘制层过滤器 def produce_img(x): x -= x.mean() x /= x.std()+1e-5 x = (x*0.1)+0.5 x = np.clip(x,0,1) x *= 255 x = np.clip(x,0,255).astype('uint8') return x def show_filter(model0,layer_name, filter_index,input_size): '''model0要看过滤器的模型,layer_index待查看过滤器的层序号,filter_index要查看的过滤器序号 实现的操作主要是keras后端的特性,使用python函数来定义keras函数 ''' layer_output = model0.get_layer(layer_name).output #获取某层输出 loss = K.mean(layer_output[:,:,:,filter_index]) #输出的均值作为梯度下降的损失 grads = K.gradients(loss,model0.input)[0] #计算损失关于输入的梯度,这里仅为函数的定义,并没有计算,后面传入input才开始计算 grads /= K.sqrt(K.mean(K.square(grads)))+1e-5 #梯度标准化 iterate = K.function([model0.input],[loss,grads]) #定义产生梯度和损失的函数,也就是说,输入是model0的输入,输出是上面定义的loss和grads。 #这是keras后端自带的定义函数的函数 input_img = np.random.random((1,input_size,input_size,3))*20+128. #随机一个噪音图片用来迭代 step = 1.0 for i in range(40): loss_value, grads_value = iterate([input_img]) input_img += grads_value*step return produce_img(input_img)[0] #%%以下是显示代码 from keras.applications import VGG16 input_size = 150 model = VGG16(weights='imagenet',include_top = False) #获取模型 model.summary() #查看一下模型各层 max_layer = 4 #要显示的最大层 raw = 8 #图片显示的行数 col = 8 #图片显示的列数 for k in range(max_layer): show_pic = np.zeros([raw*(input_size+5),col*(input_size+5),3]) for i in range(raw): for j in range(col): print('block'+str(k+1)+'_conv'+str(1)) print(i,j) show_pic[ i*(input_size+5):i*(input_size+5)+input_size, j*(input_size+5):j*(input_size+5)+input_size,:] = show_filter(model,'block'+str(k+1)+'_conv'+str(1), i*col+j,input_size) show_pic/=255 plt.imshow(show_pic) plt.show()
VGG16前4层的前64个过滤器的效果图:
 |
 |
 |
 |
TensorBoard