此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126 ]
发表博客,介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,给出执行效果截图,展示你感觉得意、突破、困难的地方。
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键盘在控制台下输入命令。
由于刚开始学习python,看到需求时觉得处处是重点样样是难点。并且忽视了功能一(认为只是一个例子),直接看功能二,让自己吃了不少亏。首先正常思路需要拿到文件,但是这里的文件名需要用户给出,因此涉及到控制台读取输入的问题。在控制台输入上,使用的raw_input() ,而在python3中,raw_input()与input()是合并了的,由于我买的书是python 3版本,而安装的却是python 2 的版本,二者不兼容,所以这也是遇到卡壳的地方。诸如这样的小问题太多太多,还是需要多看书学习。回到问题,书中给出,字典是解决这种问题非常高效且功能强大的数据结构。题中需要对其排序,因此要将字典里的每一对放入列表,对次数排序,因此要将字典里的每一对都倒置之后放入列表。这样才能按照字典里的第二个元素,也就是次数进行排序。这个我觉得是很困难很难想到的地方。代码如下:
wordCounts={} #create a dictionary
for line in infile:
processLine(line.lower(),wordCounts) #count in every lines
pairs=list(wordCounts.items()) #get pairs
items=[[x,y] for (y,x) in pairs] #reverse pairs
items.sort() #sort
另外由于我一开始是照着功能二做的功能一,功能一中的文本并没有十个单词,运行出来的结果将那五个单词又循环输出了一遍,造成错误。加上if语句判断后功能正常。代码如下:
if len(wordCounts)>=10:
for i in range(len(items)-1,len(items)-11,-1):#show the most 10 words and counts
print(items[i][1]+" "+str(items[i][0]))
else:
for i in range(len(items)-1,-1,-1):
print(items[i][1]+" "+str(items[i][0]))
此外,在输出不同单词数量功能上正常,但是在输出总词汇数量功能上,由于主函数的循环里调用了方法,导致输出有误。尝试了设置全局变量、设置返回值等方法,均未能解决。。。
运行结果如下:
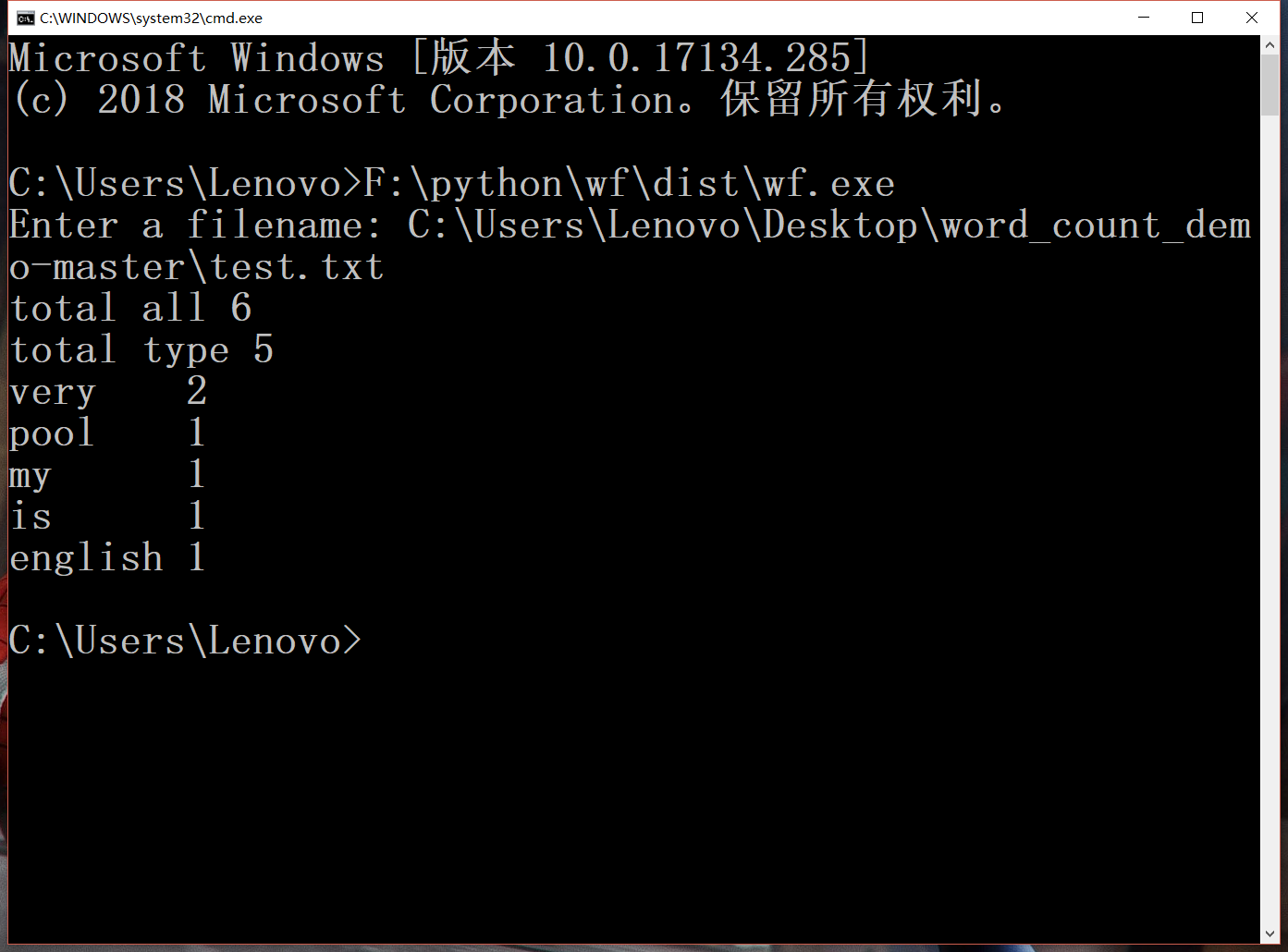
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
最大的困难在于支持命令行并且要求不依赖python解释器,需要转化为exe文件,一开始网上找了各种方法都未能行通,包括同学在博客上发的教程,我猜想可能是我安装python版本的问题。后来在同学帮助下通过脚本成功将其转化为exe文件。主要代码如下:
def processLine(line,wordCounts):
total=0
line=replacePunctuations(line) #replace the punctuation with a space
words = line.split() #get words
for word in words: #if in the dictionary,count+1,if not,types+1
if word in wordCounts:
wordCounts[word] += 1
total += 1
else:
wordCounts[word] = 1
total += 1
print("total all"),total
def replacePunctuations(line):
for ch in line:
if ch in "~!@#$%^''""&*()_+=,.;:<>?/|": #if it is a punctuation replace it
line = line.replace(ch," ")
return line
输出结果一处调用导致输出有误,尝试了设置全局变量、设置返回值等方法,均未能解决。。。
运行结果如下:

功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
查看了书上关于文件的介绍,无法解决这个问题,又在网上看了大量的博客(>=10)以及文件介绍,尝试编辑代码运行,未能成功。
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
上网搜索 linux 重定向的问题,查阅有关内容,不能看明白,询问无果,有些无从下手。
PSP
|
PSP阶段 |
预计花费时间(分钟) |
实际花费时间(分钟) |
时间花费差距(分钟) |
原因 |
|
功能一 |
120 |
357 |
237 |
安装的python版本与看的python语言程序设计一书的python版本不一致,导致中间磨蹭了太多时间,对需求的不注意,想当然导致功能做的有偏差,又得各种查漏补缺。 |
|
测试功能一 |
10 |
43 |
33 |
由于功能实现磕磕碰碰,导致测试时间也明显比预计要多得多。 |
|
功能二 |
100 |
386 |
186 |
要求能不依赖python解释器,因此需要转化为exe文件,看了网上大多数教程对我的机器并不适用,我猜想可能是跟我的python安装有关系,但是也没法推到重来,最后在同学的帮助下,使用的一串代码脚本成功转化成了exe文件。此外,计数时候的总词数总是出现问题,花费了太长时间仍是未调试好的状态。 |
|
测试功能二 |
20 |
38 |
18 |
调试总词数花费了过多的时间。 |
|
功能三 |
100 |
239 |
139 |
查看了书上关于文件的介绍,无法解决这个问题,又在网上看了大量的博客(>=10)以及文件介绍,尝试编辑代码运行,未能成功。 |
|
测试功能三 |
10 |
|
|
|
|
功能四 |
60 |
50 |
|
上网搜索linux 重定向有关内容,不能看明白,询问无果,有些无从下手。 |
|
测试功能四 |
10 |
|
|
代码及版本控制