前面两篇讲述了正则表达式的基础和一些简单的例子,这篇将稍微深入一点探讨一下正则表达式分组,在.NET中正则表达式分组是用Match类来代表的。
首先先看一段代码:
/// <summary> /// 显示Match内多个Group的例子 /// </summary> public void ShowStructure() { //要匹配的字符串 string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080"; //正则表达式 string pattern = @"((/d+)([a-z]))/s+"; //使用RegexOptions.IgnoreCase枚举值表示不区分大小写 Regex r = new Regex(pattern, RegexOptions.IgnoreCase); //使用正则表达式匹配字符串,仅返回一次匹配结果 Match m = r.Match(text); while (m.Success) { //显示匹配开始处的索引值和匹配到的值 System.Console.WriteLine("Match=[" + m + "]"); CaptureCollection cc = m.Captures; foreach (Capture c in cc) { Console.WriteLine("/tCapture=[" + c + "]"); } for (int i = 0; i < m.Groups.Count; i++) { Group group = m.Groups[i]; System.Console.WriteLine("/t/tGroups[{0}]=[{1}]", i, group); for (int j = 0; j < group.Captures.Count; j++) { Capture capture = group.Captures[j]; Console.WriteLine("/t/t/tCaptures[{0}]=[{1}]", j, capture); } } //进行下一次匹配. m = m.NextMatch(); } }
这段代码的执行效果如下:
Match=[1A ]
Capture=[1A ]
Groups[0]=[1A ]
Captures[0]=[1A ]
Groups[1]=[1A]
Captures[0]=[1A]
Groups[2]=[1]
Captures[0]=[1]
Groups[3]=[A]
Captures[0]=[A]
Match=[2B ]
Capture=[2B ]
Groups[0]=[2B ]
Captures[0]=[2B ]
Groups[1]=[2B]
Captures[0]=[2B]
Groups[2]=[2]
Captures[0]=[2]
Groups[3]=[B]
Captures[0]=[B]
..................此去省略一些结果
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
通过对上面的代码结合代码的分析,我们得出下面的结论,在((/d+)([a-z]))/s+这个正则表达式里总共包含了四个Group,即分组,按照默认的从左到右的匹配方式,其中Groups[0]代表了整个分组,其它的则是子分组,用示意图表示如下: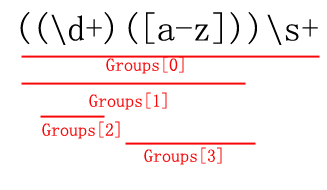
在上面的代码中是采用了Regex类的Match()方法,调用这种方法返回的是一个Match,要处理分析全部的字符串,还需要在while循环的中通过Match类的NextMatch()方法返回下一个可能成功的匹配(可通过Match类的Success属性来判断是否成功匹配)。上面的代码还可以写成如下形式:
/// <summary> /// 使用Regex类的Matches方法所有所有的匹配 /// </summary> public void Matches() { //要匹配的字符串 string text = "1A 2B 3C 4D 5E 6F 7G 8H 9I 10J 11Q 12J 13K 14L 15M 16N ffee80 #800080"; //正则表达式 string pattern = @"((/d+)([a-z]))/s+"; //使用RegexOptions.IgnoreCase枚举值表示不区分大小写 Regex r = new Regex(pattern, RegexOptions.IgnoreCase); //使用正则表达式匹配字符串,返回所有的匹配结果 MatchCollection matchCollection = r.Matches(text); foreach (Match m in matchCollection) { //显示匹配开始处的索引值和匹配到的值 System.Console.WriteLine("Match=[" + m + "]"); CaptureCollection cc = m.Captures; foreach (Capture c in cc) { Console.WriteLine("/tCapture=[" + c + "]"); } for (int i = 0; i < m.Groups.Count; i++) { Group group = m.Groups[i]; System.Console.WriteLine("/t/tGroups[{0}]=[{1}]", i, group); for (int j = 0; j < group.Captures.Count; j++) { Capture capture = group.Captures[j]; Console.WriteLine("/t/t/tCaptures[{0}]=[{1}]", j, capture); } } } }
上面的这段代码和采用While循环遍历所有匹配的结果是一样的,在实际情况中有可能出现不需要全部匹配而是从某一个位置开始匹配的情况,比如从第32个字符处开始匹配,这种要求可以通过Match()或者Matches()方法的重载方法来实现,仅需要将刚才的实例代码中的MatchCollection matchCollection = r.Matches(text);改为MatchCollection matchCollection = r.Matches(text,48);就可以了。
输出结果如下:
Match=[5M ]
Capture=[5M ]
Groups[0]=[5M ]
Captures[0]=[5M ]
Groups[1]=[5M]
Captures[0]=[5M]
Groups[2]=[5]
Captures[0]=[5]
Groups[3]=[M]
Captures[0]=[M]
Match=[16N ]
Capture=[16N ]
Groups[0]=[16N ]
Captures[0]=[16N ]
Groups[1]=[16N]
Captures[0]=[16N]
Groups[2]=[16]
Captures[0]=[16]
Groups[3]=[N]
Captures[0]=[N]
注意上面的MatchCollection matchCollection = r.Matches(text,48)表示从text字符串的位置48处开始匹配,要注意位置0位于整个字符串的之前,位置1位于字符串中第一个字符之后第二个字符之前,示意图如下(注意是字符串“1A”与“2B”之间有空格):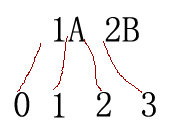
在text的位置48处正好是15M中的5处,因此返回的第一个Match是5M而不是15M。这里还继续拿出第一篇中的图来,如下: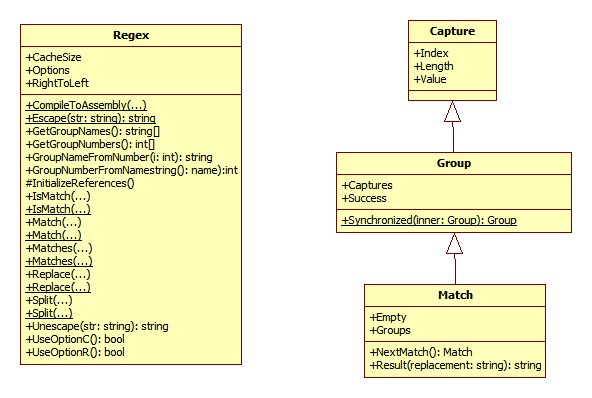
从上图可以看出Capture、Group及Match类之间存在继承关系,处在继承关系顶端的Capture类中就定义了Index、Length和Value属性,其中Index表示原始字符串中发现捕获子字符串的第一个字符的出现位置,Length属性表示子字符串的长度,而Value属性表示从原始字符串中捕获的子字符串,利用这些属性可以实现一些比较复杂的应用。例如在现在还有很多论坛仍没有使用所见即所得的在线编辑器,而是使用了一种UBB编码的编辑器,使用所见即所得的编辑器存在着一定的安全风险,比如可以在源代码中嵌入js代码或者其它恶意代码,这样浏览者访问时就会带来安全问题,而使用UBB代码就不会代码这个问题,因为UBB代码包含了有限的、但不影响常规使用的标记并且支持UBB代码的编辑器不允许直接在字符串中出现HTML代码,也而就避免恶意脚本攻击的问题。在支持UBB代码的编辑器中输入的文本在存入数据库中保存的形式是UBB编码,显示的时候需要将UBB编码转换成HTML代码,例如下面的一段代码就是UBB编码:
[url]http://zhoufoxcn.blog.51cto.com[/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]
下面通过例子演示如何将上面的UBB编码转换成HTML代码:
下面通过例子演示如何将上面的UBB编码转换成HTML代码: /// <summary> /// 下面的代码实现将文本中的UBB超级链接代码替换为HTML超级链接代码 /// </summary> public void UBBDemo() { string text = "[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]"; Console.WriteLine("原始UBB代码:" + text); Regex regex = new Regex(@"(/[url=([ /S/t]*?)/])([^[]*)(/[//url/])", RegexOptions.IgnoreCase); MatchCollection matchCollection = regex.Matches(text); foreach (Match match in matchCollection) { string linkText = string.Empty; //如果包含了链接文字,如第二个UBB代码中存在链接名称,则直接使用链接名称 if (!string.IsNullOrEmpty(match.Groups[3].Value)) { linkText = match.Groups[3].Value; } else//否则使用链接作为链接名称 { linkText = match.Groups[2].Value; } text = text.Replace(match.Groups[0].Value, "<a href="/" mce_href="/""" + match.Groups[2].Value + "/" target=/"_blank/">" + linkText + "</a>"); } Console.WriteLine("替换后的代码:"+text); }
程序执行结果如下:
原始UBB代码:[url=http://zhoufoxcn.blog.51cto.com][/url][url=http://blog.csdn.net/zhoufoxcn]周公的专栏[/url]
替换后的代码:<a href="http://zhoufoxcn.blog.51cto.com" target="_blank">http://zhoufoxcn.blog.51cto.com</a><a href="http://blog.csdn.net/zhoufoxcn"target="_blank">周公的专栏</a>
上面的这个例子就稍微复杂点,对于初学正则表达式的朋友来说,可能有点难于理解,不过没有关系,后面我会讲讲正则表达式。在实际情况下,可能通过match.Groups[0].Value这种方式不太方便,就想在访问DataTable时写string name=dataTable.Rows[i][j]这种方式一样,一旦再次调整,这种通过索引的方式极容易出错,实际上我们也可以采用名称而不是索引的放来来访问Group分组,这个也会在以后的篇幅中去讲。