上一篇博文我们讲到了iptables的一些常用的扩展匹配模块以及扩展模块的一些选项的说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12273755.html;今天再来说说剩下的几个比较常用的扩展模块。
1、limit,此模块主要是基于收发报文的速率来做匹配,通俗的讲就是来控制访问速率的。其原理是用的令牌桶算法,具体如下图

提示:从图上大概可以了解到它的基本流程,首先令牌桶在第一次会生成一定数量的令牌,然后用户要访问服务器需要从令牌桶里拿令牌才可以访问,这个令牌桶有个特点,就是如果令牌桶里的令牌是满的,它就不会生成新的令牌,如果令牌桶里的令牌不是满的,它会以一定速率的向令牌桶里放令牌,这个放令牌的速度是一个恒定的值,它不取决于令牌用的速度,即便令牌桶空了,它也是一定时间生成一定量的令牌来往里生成令牌;如果令牌桶里的令牌没有了,这时又有新的请求,那么没有拿到令牌的请求将会丢弃,不予处理其请求。这样一种控制速率的机制,它有个特点就是在最开始的请求中,也就是令牌桶是满的状态,可能存在短时间的疯抢令牌情况,因为令牌桶里有足够的令牌,使得来的一大波请求都能够拿到令牌。但这种情况一般只是短时间的,不会太长久,随后它会趋于一定速率的处理请求。
了解了令牌桶控制速率的机制,我们就不难理解下面的limit模块的选项了
--limit # [/second|/minute/hour|/day] ,次选项用于指定其生成令牌的速率
--limit-burst number ,此选项用于指定令牌桶里能够存放的令牌数量,也就是桶的大小
示例:允许所有主机ping 192.168.0.99 ,令牌桶里的令牌最大容量为5个,生成令牌的速率是每分钟生成10,来控制客户端ping服务端
[root@test ~]# iptables -F
[root@test ~]# iptables -nvL
Chain INPUT (policy ACCEPT 6 packets, 396 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 4 packets, 384 bytes)
pkts bytes target prot opt in out source destination
[root@test ~]# iptables -A INPUT -d 192.168.0.99 -p icmp --icmp-type 8 -m limit --limit 10/minute --limit-burst 5 -j ACCEPT
[root@test ~]# iptables -A INPUT -d 192.168.0.99 -p icmp -j DROP
[root@test ~]# iptables -nvL
Chain INPUT (policy ACCEPT 19 packets, 1332 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT icmp -- * * 0.0.0.0/0 192.168.0.99 icmptype 8 limit: avg 10/min burst 5
0 0 DROP icmp -- * * 0.0.0.0/0 192.168.0.99
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 13 packets, 1212 bytes)
pkts bytes target prot opt in out source destination
[root@test ~]#
提示:本人之所以要加一条拒绝所有icmp的请求规则,是因为我的INPUT链默认策略是ACCEPT,如果默认规则是REJECT或者DROP 是可以不用加第二条规则
测试:用客户端ping 192.168.0.99看看其回复报文有什么特点,是不是起到了控制速率的效果
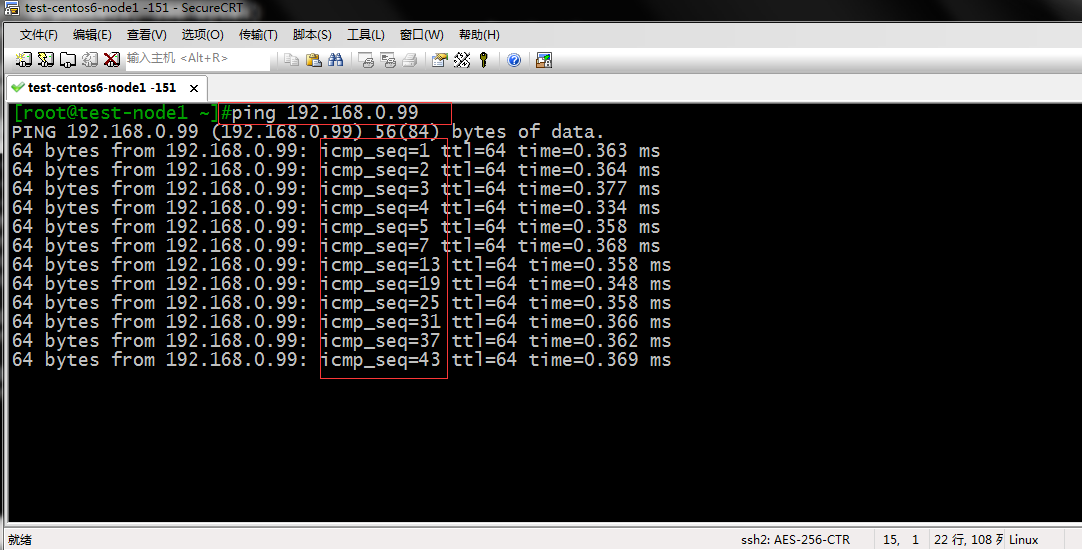
提示:我们从上面测试结果可以看到,ping请求的回应包序号,最开始它是顺序的,过了5个包后,基本上就是6秒一个回应包,这里的原因就像我们上面说的,最开始令牌桶里有5个令牌,一开始请求的时候,请求报文能够拿到令牌,过一段时间后,令牌桶里的令牌不足了,所以在令牌生成的这一段时间里的请求报文,防火墙是匹配到第二条规则里,所以给拒绝掉了,当令牌桶里有新的令牌时,去请求的报文就可以拿到一个令牌,从而得到响应报文,所以我们看到的响应报文,也是基于令牌生成的速率来的。这就是为什么我们看到的回应报文序列号 是每隔6秒有一个回应包的原因。
2、state扩展
state模块是根据连接追踪机制去检查连接的状态,使用这个模块去匹配报文时比较消耗防火墙资源的,因为防火墙要在其内存维护一张连接追踪表,这个表记录着请求本机和响应之间的关系。每检查一次请求报文,它都会去这个表里看一看,是不是之前来过的,基于某一状态来追踪报文的合法性。
state状态有如下几种:
NEW:这种状态表示新发出的请求报文;连接追踪信息表中不存在此链接的相关信息条目,因此会识别成第一次发出的请求;
ESTABLISHED:此状态表示,NEW状态之后,连接追踪信息表中为其建立的条目失效之前期间内所进行的通信状态
RELATED:此状态表示新发起的请求,但与已连接相关联的连接,比如FTP协议的数据连接与命令连接之间的关系
INVALID:此状态表示无效的连接,如flag标记不正确的连接
UNTRACKED:此状态表示未进行追踪的连接,如raw表中关闭追踪的连接
[!] --state state,此选项表示指定其连接追踪状态,这个选项指定的值就是上面几种状态的一种或多种。
示例:在INPUT链上添加对其指定端口的指定状态连接给予放行
[root@test ~]# iptables -F
[root@test ~]# iptables -nvL
Chain INPUT (policy ACCEPT 9 packets, 620 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 6 packets, 712 bytes)
pkts bytes target prot opt in out source destination
[root@test ~]# iptables -A INPUT -p tcp -m multiport --dports 23,41319 -m state --state NEW,ESTABLISHED -j ACCEPT
[root@test ~]# iptables -A INPUT -j DROP
[root@test ~]# iptables -A OUTPUT -p tcp -m multiport --sports 23,41319 -m state --state ESTABLISHED -j ACCEPT
[root@test ~]# iptables -A OUTPUT -j DROP
[root@test ~]# iptables -nvL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
364 27040 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 multiport dports 23,41319 state NEW,ESTABLISHED
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
59 5460 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 multiport sports 23,41319 state ESTABLISHED
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0
[root@test ~]#
提示:以上规则表示放行INPUT链上连接状态为NEW,ESTABLISHED的连接,在OUTPUT链上允许放行状态为ESTABLISHED的连接
测试:用客户端去连接服务器
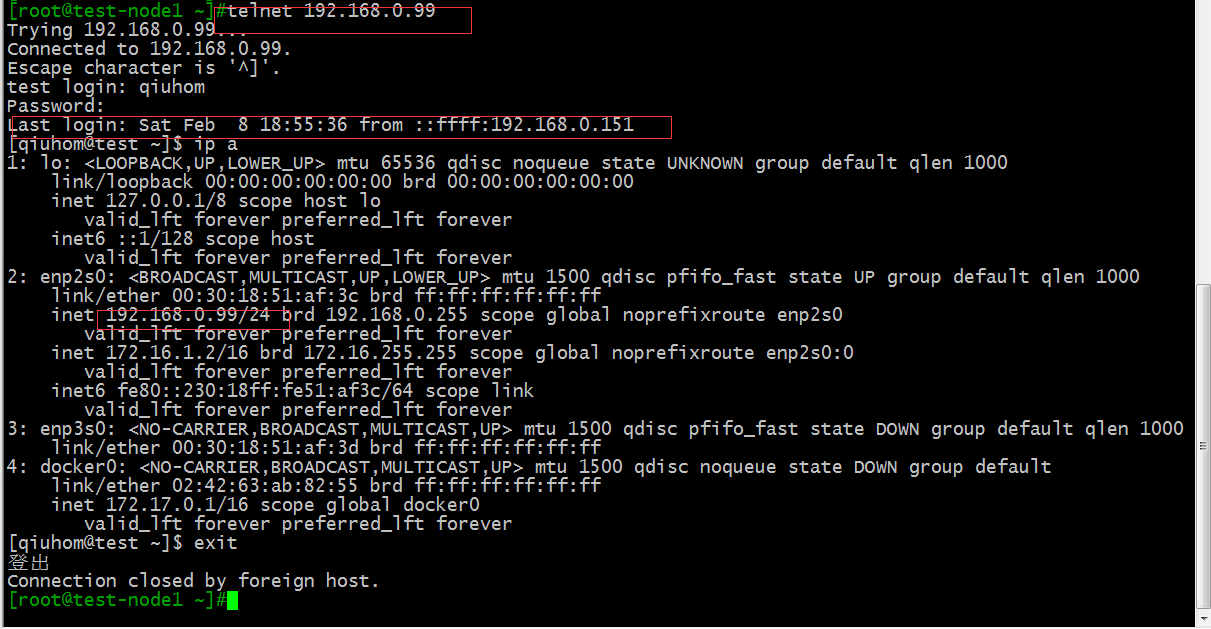
提示:可以看到我们用客户端去连接服务端是没有问题的。

提示:在服务端查看防火墙规则,也看到了对应的规则上匹配到了响应的数据报文
在服务端我们可以查看/proc/net/conntrack文件,这个文件中就是我们说到的连接追踪信息表
[root@test ~]# cat /proc/net/nf_conntrack ipv4 2 tcp 6 299 ESTABLISHED src=192.168.0.232 dst=192.168.0.99 sport=8004 dport=41319 src=192.168.0.99 dst=192.168.0.232 sport=41319 dport=8004 [ASSURED] mark=0 zone=0 use=2 ipv4 2 tcp 6 431993 ESTABLISHED src=192.168.0.151 dst=192.168.0.99 sport=39715 dport=23 src=192.168.0.99 dst=192.168.0.151 sport=23 dport=39715 [ASSURED] mark=0 zone=0 use=2 ipv4 2 tcp 6 235 ESTABLISHED src=192.168.0.99 dst=192.168.0.99 sport=36426 dport=3306 src=192.168.0.99 dst=192.168.0.99 sport=3306 dport=36426 [ASSURED] mark=0 zone=0 use=2 [root@test ~]#
提示:可以看到我们指定放行的状态连接的主机信息都在里面。我们前面说过这个连接追踪信息表它是有大小和时效的,我们怎么看本机的连接追踪最大值和失效呢,在/proc/sys/net/nf_conntrack_max 文件中就记录了最大连接追踪的条目个数,在/proc/sys/net/netfilter/这个目录里就定义了各种协议的连接追踪时长,接下来我们来看看这些文件
[root@test ~]# cat /proc/sys/net/nf_conntrack_max 65536 [root@test ~]# ls /proc/sys/net/netfilter/ nf_conntrack_acct nf_conntrack_helper nf_conntrack_tcp_timeout_close nf_conntrack_buckets nf_conntrack_icmp_timeout nf_conntrack_tcp_timeout_close_wait nf_conntrack_checksum nf_conntrack_log_invalid nf_conntrack_tcp_timeout_established nf_conntrack_count nf_conntrack_max nf_conntrack_tcp_timeout_fin_wait nf_conntrack_dccp_loose nf_conntrack_sctp_timeout_closed nf_conntrack_tcp_timeout_last_ack nf_conntrack_dccp_timeout_closereq nf_conntrack_sctp_timeout_cookie_echoed nf_conntrack_tcp_timeout_max_retrans nf_conntrack_dccp_timeout_closing nf_conntrack_sctp_timeout_cookie_wait nf_conntrack_tcp_timeout_syn_recv nf_conntrack_dccp_timeout_open nf_conntrack_sctp_timeout_established nf_conntrack_tcp_timeout_syn_sent nf_conntrack_dccp_timeout_partopen nf_conntrack_sctp_timeout_heartbeat_acked nf_conntrack_tcp_timeout_time_wait nf_conntrack_dccp_timeout_request nf_conntrack_sctp_timeout_heartbeat_sent nf_conntrack_tcp_timeout_unacknowledged nf_conntrack_dccp_timeout_respond nf_conntrack_sctp_timeout_shutdown_ack_sent nf_conntrack_timestamp nf_conntrack_dccp_timeout_timewait nf_conntrack_sctp_timeout_shutdown_recd nf_conntrack_udp_timeout nf_conntrack_events nf_conntrack_sctp_timeout_shutdown_sent nf_conntrack_udp_timeout_stream nf_conntrack_events_retry_timeout nf_conntrack_tcp_be_liberal nf_log nf_conntrack_expect_max nf_conntrack_tcp_loose nf_log_all_netns nf_conntrack_generic_timeout nf_conntrack_tcp_max_retrans [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_icmp_timeout 30 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_udp_timeout 30 [root@test ~]#
提示:可以看到/proc/sys/net/netfilter/这个目录下的文件都记录了对应协议的超时时间。而/proc/sys/net/nf_conntrack_max这个文件中记录了连接追踪表里最大记录连接追踪信息的条目个数。我们可以通过修改对应的文件来调节连接追踪表的大小和个协议失效时长。
iptables的连接追踪表最大容量由/proc/sys/net/nf_conntrack_max文件中定义,各种状态的连接超时后会从连接追踪表中删除;当连接追踪表满了,后续的连接可能会超时,这个时候我们有两种解决办法:第一个就是加大连接追踪表容量,前提是我们要有足够的内存去存这个连接追踪表;其次我们还可以把各个状态的超时降低,让其连接追踪表里的条目能够很快的腾出空间来记录新的状态的连接追踪信息
1、加大nf_conntrack_max值
编辑/etc/sysctl.conf 把如下内容添加到该文件中,然后保存
net.nf_conntrack_max = 393216
net.netfilter.nf_conntrack_max = 393216
当然后面的值可以根据情况自己定义一个合适大小的值
[root@test ~]# cat /etc/sysctl.conf # sysctl settings are defined through files in # /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/. # # Vendors settings live in /usr/lib/sysctl.d/. # To override a whole file, create a new file with the same in # /etc/sysctl.d/ and put new settings there. To override # only specific settings, add a file with a lexically later # name in /etc/sysctl.d/ and put new settings there. # # For more information, see sysctl.conf(5) and sysctl.d(5). net.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_max = 393216 [root@test ~]# sysctl -p net.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_max = 393216 [root@test ~]# cat /proc/sys/net/nf_conntrack_max 393216 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_max 393216 [root@test ~]#
提示:当然把对应的值写到文件中是永久更改的方式,也就是下一次重新开机,这个值不会变。如果想临时测试下,我们可以用echo 命令 echo 一个值到/proc/sys/net/nf_conntrack_max文件中即可
2、降低 nf_conntrack timeout时间
编辑/etc/sysctl.conf 把以下内容写入其中,然后保存
net.netfilter.nf_conntrack_tcp_timeout_established = 300
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 1
[root@test ~]# cat /etc/sysctl.conf # sysctl settings are defined through files in # /usr/lib/sysctl.d/, /run/sysctl.d/, and /etc/sysctl.d/. # # Vendors settings live in /usr/lib/sysctl.d/. # To override a whole file, create a new file with the same in # /etc/sysctl.d/ and put new settings there. To override # only specific settings, add a file with a lexically later # name in /etc/sysctl.d/ and put new settings there. # # For more information, see sysctl.conf(5) and sysctl.d(5). net.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_tcp_timeout_established = 300 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60 net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 1 [root@test ~]# sysctl -p net.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_max = 393216 net.netfilter.nf_conntrack_tcp_timeout_established = 300 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60 net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 1 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_established 300 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_time_wait 120 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_close_wait 60 [root@test ~]# cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_fin_wait 1 [root@test ~]#
提示:我们把对应的参数和值写到/etc/sysctl.conf文件中,然后用sysctl -p 去重读配置文件,让其对应的文件中的值发生变化。这种方式是修改内核参数常规的方式。同样我们只是想测试下,不想永久的修改,可以选择用echo命令往对应文件中写入对应的值
开放被动模式的ftp服务
众所周知ftp被动模式下,其数据端口是随机的,也就是说我们在防火墙上配置是相当麻烦的,可以说没法用匹配端口的方式去配置防火墙,我们需要用到连接追踪功能,我们知道FTP 的数据端口是通过命令端口21去协商出来的一个端口,客户端和服务端协商好一个随机端口,然后开始传输数据,在防火墙上我们需要配置只要和21号端口有关联的我们都给开放,这样一来我们防火墙匹配报文就可以匹配到和21号端口相关的数据端口,从而实现放行FTP数据端口的目的。默认情况下Linux系统默认装载的连接追踪模块对于FTP是不生效的,针对FTP连接追踪我们需要重新加载专用的连接追踪模块nf_conntrack_ftp 接下来我们来看看系统是否有这个模块。
[root@test ~]# ls /lib/modules/3.10.0-693.el7.x86_64/kernel/net/netfilter/|grep -E *.ftp nf_conntrack_ftp.ko.xz nf_conntrack_tftp.ko.xz nf_nat_ftp.ko.xz nf_nat_tftp.ko.xz [root@test ~]#
提示:可以看到我们内核模块目录里有nf_conntrack_ftp这个模块。有这个模块但不一定装载了,接下来还要检查系统是否转载了
[root@test ~]# lsmod |grep -E *.ftp [root@test ~]#
提示:可以看到系统没有装载任何和FTP有关的模块
[root@test ~]# modprobe nf_conntrack_ftp [root@test ~]# lsmod |grep -E *.ftp nf_conntrack_ftp 18638 0 nf_conntrack 137239 9 ip_vs,nf_nat,xt_connlimit,nf_nat_ipv4,xt_conntrack,nf_nat_masquerade_ipv4,nf_conntrack_netlink,nf_conntrack_ftp,nf_conntrack_ipv4 [root@test ~]#
提示:modprobe命令是用来装载指定模块的,这种方式是临时装载,如果我们重启系统后,这个模块它不会重新去装载,要想开机自动装载对应的模块,我们可以选择把要装载的模块名称写到/etc/sysconfig/iptables-config配置文件中,如下所示
[root@test ~]# head /etc/sysconfig/iptables-config # Load additional iptables modules (nat helpers) # Default: -none- # Space separated list of nat helpers (e.g. 'ip_nat_ftp ip_nat_irc'), which # are loaded after the firewall rules are applied. Options for the helpers are # stored in /etc/modprobe.conf. IPTABLES_MODULES="nf_conntrack_ftp" # Unload modules on restart and stop # Value: yes|no, default: yes # This option has to be 'yes' to get to a sane state for a firewall [root@test ~]#
提示:如果有多个模块需要加载,可以用空格把多个模块名称隔开
加载了专用的模块后,我们就可以写防火墙规则,来放行被动模式下的FTP
测试:在写规则前,我们先测试下,FTP是否能够通过客户端访问

提示:防火墙INPUT和OUTPUT链上默认规则是DROP,然后对应的规则上没有开放其21号端口,所以我们用客户端连接21号端口是没法连接的,接下来我们在防火墙上配置规则,放行其21号端口的报文
[root@test ~]# iptables -P INPUT ACCEPT
[root@test ~]# iptables -P OUTPUT ACCEPT
[root@test ~]# iptables -F
[root@test ~]# iptables -A INPUT -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT
[root@test ~]# iptables -A OUTPUT -p tcp -m state --state ESTABLISHED -j ACCEPT
[root@test ~]# iptables -A INPUT -p tcp -m multiport --dports 21,41319 -m state --state NEW -j ACCEPT
[root@test ~]# iptables -P INPUT DROP
[root@test ~]# iptables -P OUTPUT DROP
[root@test ~]# iptables -nvL
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
412 29132 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 multiport dports 21,41319 state NEW
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
165 15340 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 state ESTABLISHED
[root@test ~]#
提示:我们把INPUT和OUTPUT链上的默认规则配置成ACCEPT,然后在清楚之前配置的规则,然后在INPUT链上允许放行状态为ESTABLISHED和RELATED的报文,在OUTPUT链上允许放行状态为ESTABLISHED的数据报文,然后在INPUT链上放行21号端口和SSH连接端口的状态为NEW的数据报文,最后我们把INPUT和OUTPUT链上的默认策略更改为DROP,这样配置后,在OUTPUT链上,只要报文状态是ESTABLISHED的都给予放行处理,在INPUT链上,如果是请求的目标端口是21号且状态为NEW的都给予放行,这样一来首先客户端登录FTP是没有问题的,其次是数据链锯,在INPUT链上我们配置了状态为RELATED的数据报文是允许放行,这样一来FTP的数据链路应该是没有问题。接下来我们在客户端连接FTP服务器,看看其数据链路的报文是否都被允许了
测试:在客户端用FTP工具连接FTP服务器,看看其数据链路是否超时
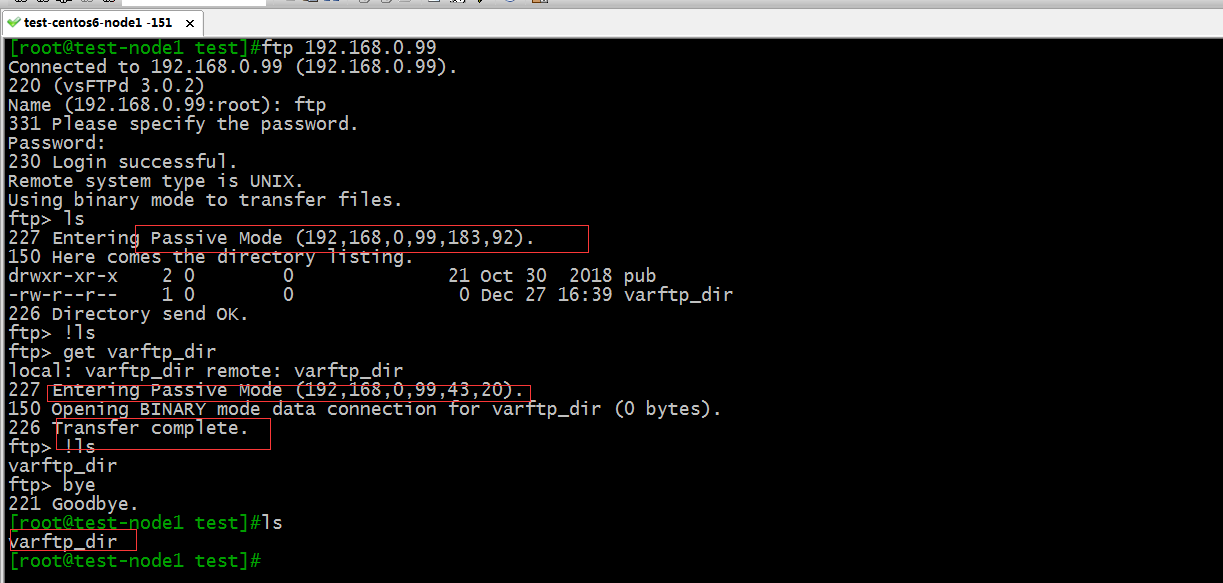
提示:可以看到在客户端连接FTP服务器是可以正常的登录和下载文件,充分说明了我们配置的防火墙规则是没有问题的
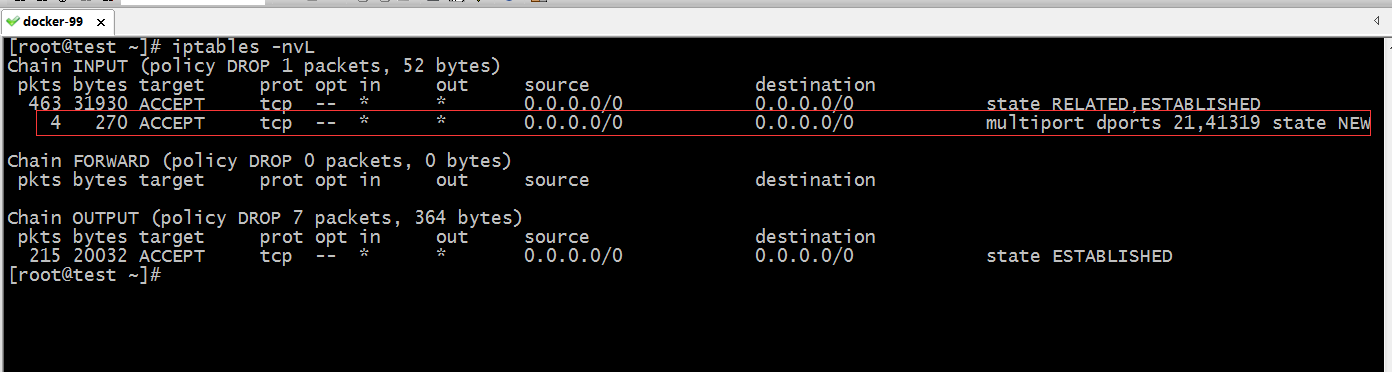
提示:在服务端我们也可以看到INPUT链上的第二条规则就匹配到4个包,而其他规则匹配了大量的包,为什么第二条规则匹配的报文这么少呢?这时因为第二条规则只有新客户端最开始去连接FTP服务器时 它才能匹配得到,后续的报文状态要么是ESTABLISHED的状态,要么是RELATED状态的报文。所以在INPUT和OUTPUT链上的第一条规则相当于一个万能的规则,只要其状态符合通行的条件报文就可以通过。有了state这个扩展模块,我们发现我们写的规则可以大大的减少很多,很多规则可以用一条就可以代替。这里还需要注意一点的是,用state扩展匹配条件,对服务器的性能有影响,我们在使用state模块的功能的同时,还需要考虑它服务器的性能。