一、MySQL有多少种存储引擎?
在MySQL5之后,支持的存储引擎有十多个,但是我们常用的就那么几种,而且,默认支持的也是 InnoDB。
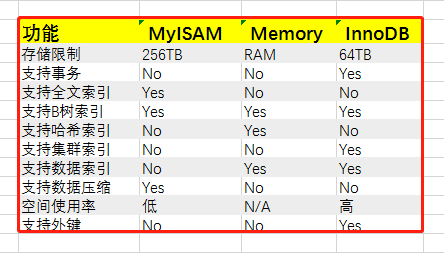
通过命令:show engines g,我们可以查看到当前数据库可以支持的存储引擎有哪些。MySQL默认支持了9种,其中,有3种是我们最常见的。如下图:
二、你们项目中使用MySQL的搜索引擎是哪个?为什么要用这个?
我们使用的是 InnoDB。
1、InnoDB
InnoDB是默认的数据库存储引擎,主要特点有:
a、可以自动增长列,方法是:auto_increment。
b、支持事务。默认的事务隔离级别是可重复读,通过MVCC(并发版本控制)来实现。
c、使用的锁粒度为行级锁,可以支持更高的并发。
d、支持外键约束;外键约束其实降低了表的查询速度,但是增加了表之间的耦合度。
e、配合一些热备工具可以支持在线热备份。
f、在 InnoDB 中存着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度;
g、对于 InnoDB 类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织,数据和索引放在一块,都位于B+树的叶子节点上。
当然,InnoDB 的存储表和索引也有下面两种形式:
(1)使用共享表空间存储:所有的表和索引存放在同一个表空间中。
(2)使用多表空间存储:表结构放在frm文件,数据和索引放在IBD文件中。分区表的话,每个分区对应单独的IBD文件,分区表的定义可以查看我的其他文章。使用分区表的好处在于提升查询效率。
对于InnoDB来说,最大的特点在于支持事务。但是这是以损失效率来换取的。
2、MyISAM
使用这个存储引擎,每个 MyISAM 在磁盘上存储形成3个文件:
a、frm文件:存储表的定义数据;
b、MYD文件:存放表具体记录的数据;
c、MYI文件:存储索引;
frm 和 MYI 可以存放在不同的目录下。MYI 文件用来存储索引,但仅保存记录所在页的指针,索引的结构是B+树结构。
下面这张图就是MYI文件保存的机制:
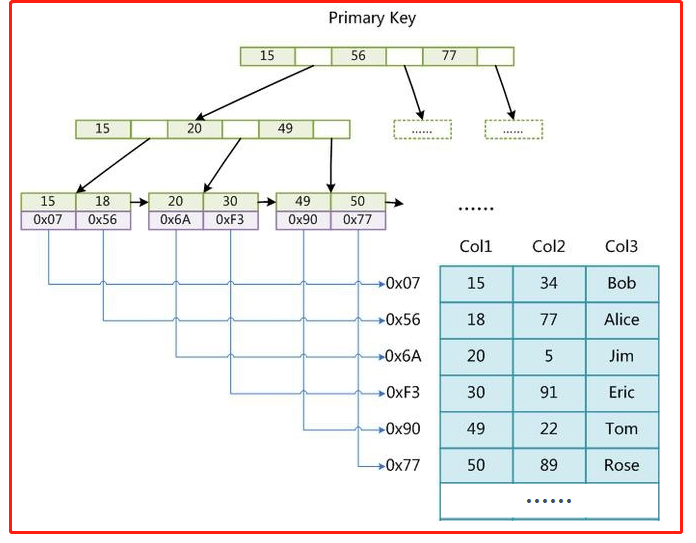
从这张图可以发现,这个存储引擎通过MYI的B+树结构来查找记录页,再根据记录页查找记录。并且支持全文索引、B树索引和数据压缩。
支持数据的类型也有三种:
(1)静态固定长度表
这种方式的优点在于存储速度非常快,容易发生缓存,而且表发生损坏后也容易修复。缺点是占空间。这也是默认的存储格式。
(2)动态可变长表
优点是节省空间,但是一旦出错恢复起来比较麻烦。
(3)压缩表
上面说到支持数据压缩,说明肯定也支持这个格式。在数据文件发生错误时候,可以使用check table工具来检查,而且还可以使用repair table工具来恢复。
有一个重要的特点那就是不支持事务,但是这也意味着他的存储速度更快,如果你的读写操作允许有错误数据的话,只是追求速度,可以选择这个存储引擎。
3、Memory
将数据存在内存,为了提高数据的访问速度,每一个表实际上和一个磁盘文件关联。文件是frm。
(1)支持的数据类型有限制,比如:不支持TEXT和BLOB类型,对于字符串类型的数据,只支持固定长度的行,VARCHAR会被自动存储为CHAR类型;
(2)支持的锁粒度为表级锁。所以,在访问量比较大时,表级锁会成为MEMORY存储引擎的瓶颈;
(3)由于数据是存放在内存中,一旦服务器出现故障,数据都会丢失;
(4)查询的时候,如果有用到临时表,而且临时表中有BLOB,TEXT类型的字段,那么这个临时表就会转化为MyISAM类型的表,性能会急剧降低;
(5)默认使用hash索引。
(6)如果一个内部表很大,会转化为磁盘表。
在这里只是给出3个常见的存储引擎。使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
三、你们数据库中单表最大的数据量有多少?查询时有什么问题?你们怎么处理的?
优化:1、分库分表(阿里开发规范里,单表数据量超过500W或超过2GB,才推荐分库分表。);2、索引优化;