0 前言
0.1 编译阶段生成JobGraph

0.2 运行阶段生成调度ExecutionGraph
1 task 数据之间的传输
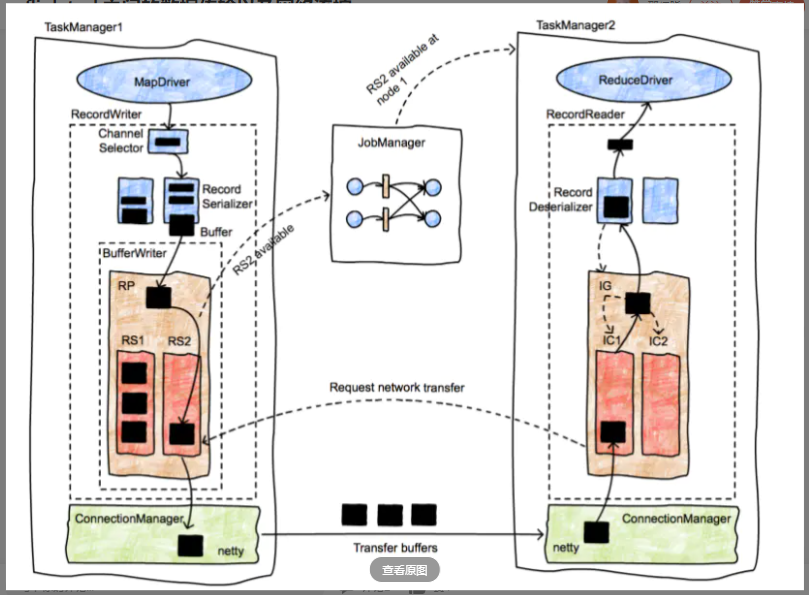
此图片更详细地介绍了数据记录从生产者运送到消费者时的生命周期。最初,MapDriver会生成记录(由收集器收集),这些记录将传递到RecordWriter对象。 RecordWriters包含许多序列化程序(RecordSerializer对象),每个使用方任务一个,可能会消耗这些记录。例如,在随机播放或广播中,序列化器的数量将与使用者任务的数量一样多。 ChannelSelector选择一个或多个串行器以放置记录。例如,如果广播记录,则将它们放置在每个序列化程序中。如果记录是按哈希分区的,则ChannelSelector将评估记录上的哈希值并选择适当的序列化程序。
序列化程序将记录序列化为它们的二进制表示形式,并将它们放置在固定大小的缓冲区中(记录可以跨越多个缓冲区)。这些缓冲区并移交给BufferWriter并写出到ResultPartition(RP)。 RP由几个子分区(ResultSubpartitions-RS)组成,这些子分区收集特定使用者的缓冲区。在图中,该缓冲区发往第二个reducer(在TaskManager 2中),并将其放置在RS2中。由于这是第一个缓冲区,因此RS2可供使用(请注意,此行为实现了流式分发),并通知JobManager。
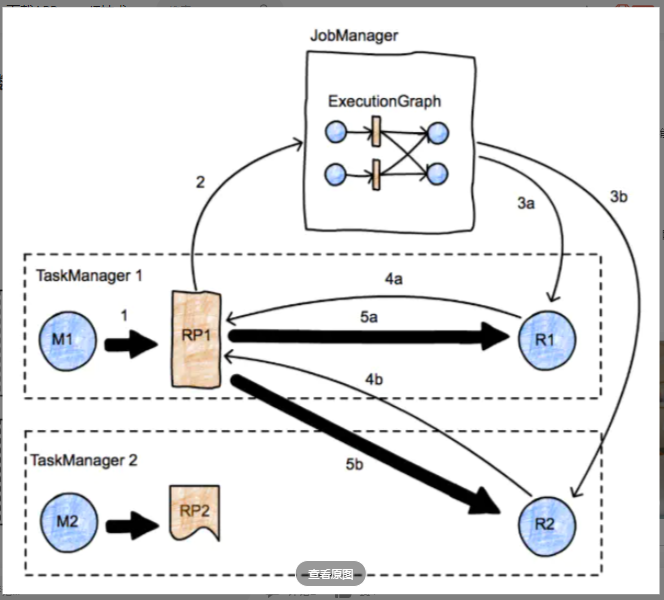
JobManager查找RS2的使用者,并通知TaskManager 2可用数据块。发送到TM2的消息向下传播到应该接收此缓冲区的InputChannel,后者进而通知RS2可以启动网络传输。然后,RS2将缓冲区移交给TM1的网络堆栈,后者又将其移交给Netty进行运输。网络连接是长期运行的,并且存在于TaskManager之间,而不是单个任务之间。
一旦TM2接收到缓冲区,它就会通过相似的对象层次结构,从InputChannel(与IRPQ等效的接收器端)开始,到达InputGate(包含多个IC),最后在RecordDeserializer中结束,从缓冲区生成类型化的记录,并将其交给接收任务,在这种情况下为ReduceDriver。
ResultPartition as RP 和 ResultSubpartition as RS
ExecutionVertex 会被调度到 TaskManager 中执行,一个 Task 对应一个 ExecutionVertex。同 ExecutionVertex 的输出结果 IntermediateResultPartition 相对应的则是 ResultPartition。IntermediateResultPartition 可能会有多个 ExecutionEdge 作为消费者,那么在 Task 这里,ResultPartition 就会被拆分为多个 ResultSubpartition,下游每一个需要从当前 ResultPartition 消费数据的 Task 都会有一个专属的 ResultSubpartition。ResultPartitionType指定了ResultPartition 的不同属性,这些属性包括是否流水线模式、是否会产生反压以及是否限制使用的 Network buffer 的数量。enum ResultPartitionType 有三个枚举值:BLOCKING:非流水线模式,无反压,不限制使用的网络缓冲的数量
PIPELINED:流水线模式,有反压,不限制使用的网络缓冲的数量
PIPELINED_BOUNDED:流水线模式,有反压,限制使用的网络缓冲的数量
InputGate as IG 和 InputChannel as ICTask 中,InputGate是对输入的封装,InputGate 是和 JobGraph 中 JobEdge 一一对应的。也就是说,InputGate 实际上对应的是该 Task 依赖的上游算子(包含多个并行子任务),每个 InputGate 消费了一个或多个 ResultPartition。InputGate 由 InputChannel 构成,InputChannel 和ExecutionEdge 一一对应;也就是说, InputChannel 和 ResultSubpartition 一一相连,一个 InputChannel接收一个ResultSubpartition 的输出。根据读取的ResultSubpartition 的位置,InputChannel 有 LocalInputChannel 和 RemoteInputChannel 两种不同的实现。作者:邵红晓
链接:https://www.jianshu.com/p/72e996b4c2bd
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。