Interval Join
KeyedStream,KeyedStream → DataStream #
Join two elements e1 and e2 of two keyed streams with a common key over a given time interval, so that e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound.
Interval Join会将两个数据流按照相同的key,并且在其中一个流的时间范围内的数据进行join处理。通常用于把一定时间范围内相关的分组数据拉成一个宽表。我们通常可以用类似下面的表达式来使用interval Join来处理两个数据流:
key1 == key2 && e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
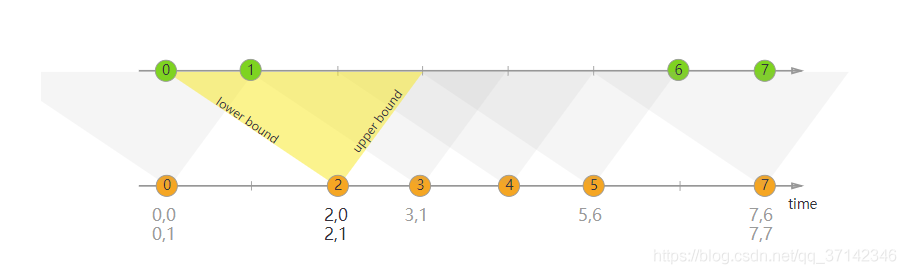
我们通常可以使用下面的编程模型来处理两个数据流:
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream
.keyBy(<KeySelector>)
.intervalJoin(greenStream.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(first + "," + second);
}
});
2.操作DataSet
实例如下:
public class JoinDemo {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env=ExecutionEnvironment.getExecutionEnvironment();
DataSet<Tuple2<String,Integer>> data1=env.fromElements(
Tuple2.of("class1",100),
Tuple2.of("class1",400),
Tuple2.of("class2",200),
Tuple2.of("class2",400)
);
DataSet<Tuple2<String,Integer>> data2=env.fromElements(
Tuple2.of("class1",300),
Tuple2.of("class1",600),
Tuple2.of("class2",200),
Tuple2.of("class3",200)
);
data1.join(data2)
.where(0).equalTo(0)
.with(new JoinFunction<Tuple2<String,Integer>, Tuple2<String,Integer>, Object>() {
@Override
public Object join(Tuple2<String, Integer> tuple1,
Tuple2<String, Integer> tuple2) throws Exception {
return new String(tuple1.f0+" : "+tuple1.f1+" "+tuple2.f1);
}
}).print();
}
}
运行结果:
class1 : 100 300
class1 : 400 300
class1 : 100 600
class1 : 400 600
class2 : 200 200
class2 : 400 200
除此之外,在操作DataSet时还有很多join,如Outer Join,Flat Join等等,具体可以查看官方文档: